pyspark的基础使用
同时处理多个文件
读取的时候直接读取一个用,分隔的字符串即可,具体来说用','.join()来对文件名进行拼接即可。
如果需要转成Dataframe做后续的处理,读完之后先map然后再转即可。
查看交集
用rdd.intersection会比较好
SQL读出来的Dataframe转rdd
记得还要.map(lambda x:str(x[0]))进行转换,否则得到的结果都是含有Row(...)
all_gids_query_template = """
SELECT
DISTINCT group_id
FROM
toutiao_developer.feed_card
WHERE
date = {}
LIMIT 999999999
"""
all_gids_query = all_gids_query_template.format(20200521)
all_gids = spark.sql(all_gids_query).rdd
没有转换前
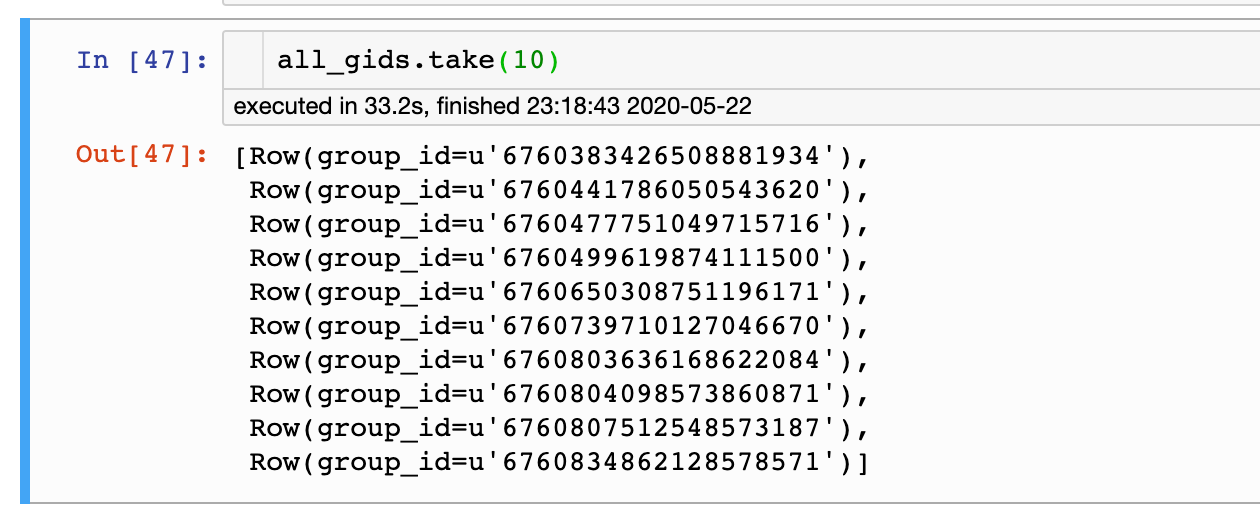
转换后:
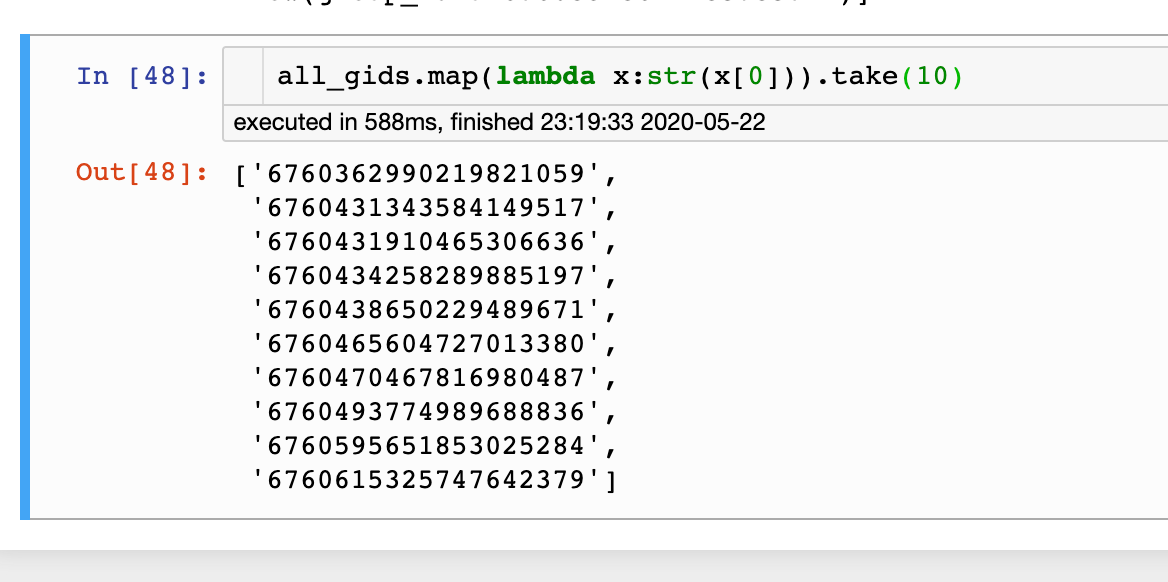
获取distribution
rdd
from __future__ import print_function
import sys
from operator import add
# SparkSession:是一个对Spark的编程入口,取代了原本的SQLContext与HiveContext,方便调用Dataset和DataFrame API
# SparkSession可用于创建DataFrame,将DataFrame注册为表,在表上执行SQL,缓存表和读取parquet文件。
from pyspark.sql import SparkSession
if __name__ == "__main__":
# Python 常用的简单参数传入
if len(sys.argv) != 2:
print("Usage: wordcount <file>", file=sys.stderr)
exit(-1)
# appName 为 Spark 应用设定一个应用名,改名会显示在 Spark Web UI 上
# 假如SparkSession 已经存在就取得已存在的SparkSession,否则创建一个新的。
spark = SparkSession\
.builder\
.appName("PythonWordCount")\
.getOrCreate()
# 读取传入的文件内容,并写入一个新的RDD实例lines中,此条语句所做工作有些多,不适合初学者,可以截成两条语句以便理解。
# map是一种转换函数,将原来RDD的每个数据项通过map中的用户自定义函数f映射转变为一个新的元素。原始RDD中的数据项与新RDD中的数据项是一一对应的关系。
lines = spark.read.text(sys.argv[1]).rdd.map(lambda r: r[0])
# flatMap与map类似,但每个元素输入项都可以被映射到0个或多个的输出项,最终将结果”扁平化“后输出
counts = lines.flatMap(lambda x: x.split(' ')) \
.map(lambda x: (x, 1)) \
.reduceByKey(add)
# collect() 在驱动程序中将数据集的所有元素作为数组返回。 这在返回足够小的数据子集的过滤器或其他操作之后通常是有用的。由于collect 是将整个RDD汇聚到一台机子上,所以通常需要预估返回数据集的大小以免溢出。
output = counts.collect()
for (word, count) in output:
print("%s: %i" % (word, count))
spark.stop()以待统计的为key,map成(key, 1),最后用reduceByKey即可
保存文件
rdd
saveAsTextFile:默认保存成snappy格式(即一定会有压缩)
result=[('2', 332), ('46', 1084214), ('0', 28107643)]
res_rdd=sc.parallelize(result,1)
res_rdd.collect()
>>>[('2', 332), ('46', 1084214), ('0', 28107643)]
res_rdd.repartition(1).map(lambda x:'\t'.join([str(i) for i in x])).saveAsTextFile(chnid_ouputdir)注意:
- 要把每一个(k,v)转化成字符串,可以用
'\t'.join([str(i) for i in x])
最后的输出为`path/to/directory/part-0000.snappy’:

在driver上临时保存成文件然后再用Popen put到hdfs上
with open(output_txt, 'w') as f:
f.write('\t'.join([str(i) for i in result]))
put_file=Popen(['hdfs','dfs','-put', output_txt, output_txt_dir], stdout=PIPE)
# put_file_res=put_file.communicat()重定向输出到管道之后,只有一次communicate的机会,第二次communicate会报错
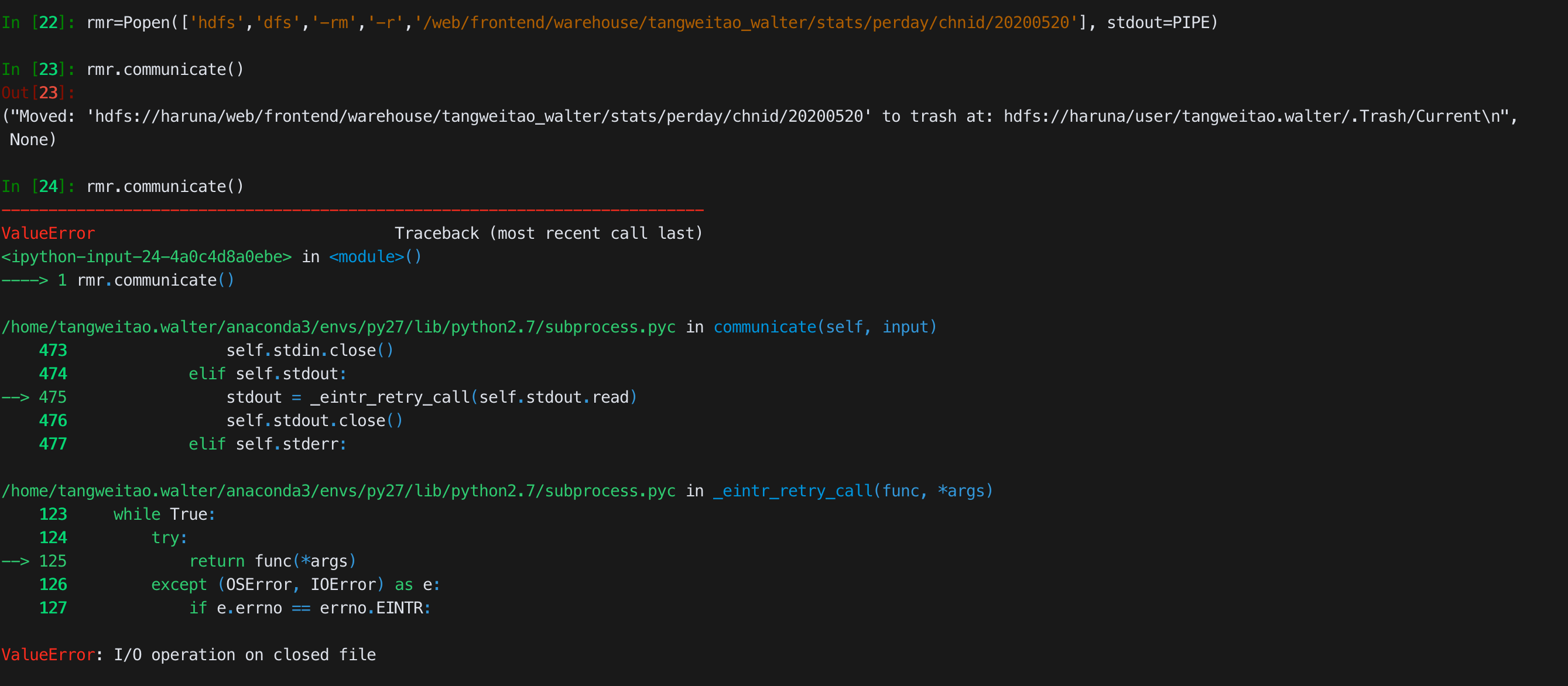
和hdfs交互
直接用SparkContext自带的
# sc stands for SparkContext
hdfs = sc._jvm.org.apache.hadoop.fs.FileSystem.get(sc._jsc.hadoopConfiguration())
fs = sc._jvm.org.apache.hadoop.fshdfs对应FileSystem,下面有exists, delete, isFile等操作
fs主要就是用的Path对象
Path对象
在pyspark中如果想用上述的hdfs或者fs进行hdfs操作,path并不能直接用String带入,因为相关的韩式接受的对象都是fs.Path对象。正确的做法应该是用fs.Path包裹起来:fs.Path('dir_string'):
# 若存在文件,即删除
if hdfs.exists(fs.Path(outputDir)):
hdfs.delete(fs.Path(outputDir), True)读取文件
写入文件
- 用
FSDataOutputStream.writeUTF(string S)写入string - 只有当
FSDataOutputStream.flush且FSDataOutputStream.close`后才能用`hdfs dfs -text 读到`。**或者更好的方法:直接用FSDataOutputStream.hflush或者``FSDataOutputStream.hsync**,就能够实现实时读取
例如:
output=fs.create(scfs.Path(log_dir+'/logs.txt'), True) # True代表overwrite=True
output.writeUTF('Test line 1 \n')
output.writeUTF('Test line 2 \n')
# 执行到这里并不能从对应的logs.txt中读出这两行,还需要flush+close才行
output.flush()
output.close()或者
output=fs.create(scfs.Path(log_dir+'/logs.txt'), True) # True代表overwrite=True
output.writeUTF('Test line 1 \n')
output.writeUTF('Test line 2 \n')
output.hflush() # 这一步执行之后即可在文件中读出上述内容,文件无需close上述代码中的hflush还可替换为hsync
把本地(driver上的文件)put到hdfs上
fs.copyFromLocalFile(scfs.Path('local_src'), scfs.Path('dst'))注意:
- dst要以期望的文件名为后缀
- 不需要目录存在,即不需要先
fs.mkdirs创建文件夹,直接copy到dst即可
如:
fs.copyFromLocalFile(scfs.Path('./chnid_20200520.txt'), scfs.Path(log_dir+'/chnid_20200520.txt'))list files
用正则表达式或者通配符(*)进行筛选
Wildcard in Hadoop’s FileSystem listing API calls
用globStatus(有两个函数接口),第二个能够实现更加复杂的结构,返回的都是FileStatus的数组

注意:
- 获取path需要进一步遍历数组使用
.getPath().toString() - 如果要把结果直接以一个rdd的形式读入,则还需要用
','.join(list_of_path)
one_hour_files='/data/kafka_dump/online_training_full_preclick_train_data_with_sample/{}/{}_task*'.format(date, hour)
one_hour_lists=fs.globStatus(scfs.Path(one_hour_files))
one_hour_all_lists=[i for i in one_hour_lists]
# 取前15个
sampled_one_hour_lists=one_hour_lists[:15]
sampled_one_hour_lists_str=','.join([i.getPath().toString() for i in sampled_one_hour_lists])
# 全部读入一个rdd
sampled_one_hour_rdd = sc.hadoopFile(sampled_one_hour_lists_str,
inputFormatClass='com.bytedance.hadoop.mapred.PBInputFormat',
keyClass='org.apache.hadoop.io.LongWritable',
valueClass='org.apache.hadoop.io.Text',
)
显示一个目录下全部的file
用fs.listFiles或者fs.listStatus都可以,前者可以递归地返回所有子目录的文件,后者不行
fs.listFiles
If the path is a directory, if recursive is false, returns files in the directory; if recursive is true, return files in the subtree rooted at the path. If the path is a file, return the file's status and block locations.
使用时注意:
- 返回的是一个迭代器,需要不断调用
hasNext()和next()获得实例 next()返回的是一个LocalFileStatus对象,还需要进一步调用.getPath().toString()才能获得具体的路径
one_day_all_files='/data/kafka_dump/online_training_full_preclick_train_data_with_sample/{}'.format(date)
one_day_all_files_iterator=hdfs.listFiles(fs.Path(one_day_all_files), True)
one_day_all_files_list=[]
while(one_day_all_files_iterator.hasNext()):
one_day_all_files_list.append(one_day_all_files_iterator.next())
one_day_all_files_list[0].getPath().toString()
fs.listStatus
直接返回的就是一个FileStatus的数组,直接索引即可
one_day_all_files_list=hdfs.listStatus(fs.Path(one_day_all_files))
one_day_all_files_list[1].getPath().toString()
使用python logging模块
和普通的python脚本一样:获取logger,设置Handler,开始logging。不同的是由于是在driver上执行python脚本,因此FileHandler对应的log文件只会保存在driver上,如果需要下载到hdfs上还需要用上述的copyFromLocalFile接口
local_logs = './local.log'
fmttr = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
fh = logging.FileHandler(local_logs, mode='w')
fh.setLevel(logging.DEBUG)
fh.setFormatter(fmttr)
console = logging.StreamHandler()
console.setLevel(logging.DEBUG)
console.setFormatter(fmttr)
logger = logging.getLogger('logs')
logger.addHandler(fh)
logger.addHandler(console)
logger.setLevel(logging.DEBUG)效果(默认输出到stdout中):

使用Dataframe
取消默认的压缩格式(snappy)
how to set hadoop configuration values from pyspark
spark saveastextfile without compression
只要设置:
sc._jsc.hadoopConfiguration().set('mapred.output.compress', 'false')测试文件
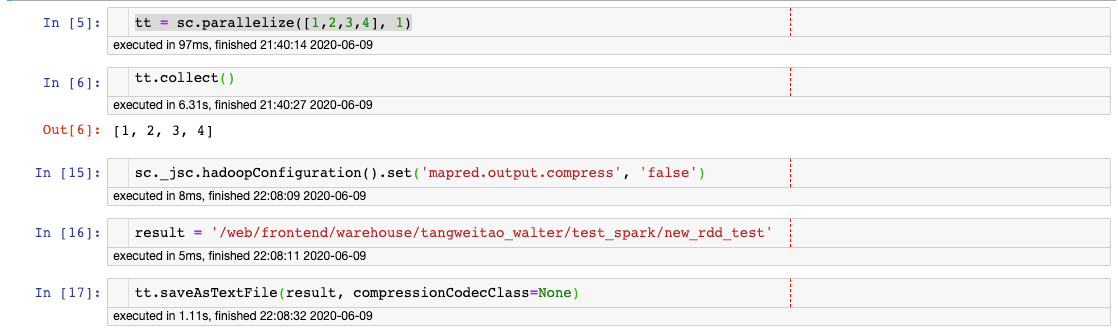
最后的确是没有压缩的:
