pytorch加速与降低显存
总体而言,主要从以下两个方面改善,不过能把第一个加速了就很好了:
- 数据预处理部分
- 模型自身的部分
当数据都在GPU时,prefetcher收益不大
哪怕数据不在GPU,FastDataloader效果也不错
而且GPU占用也不高
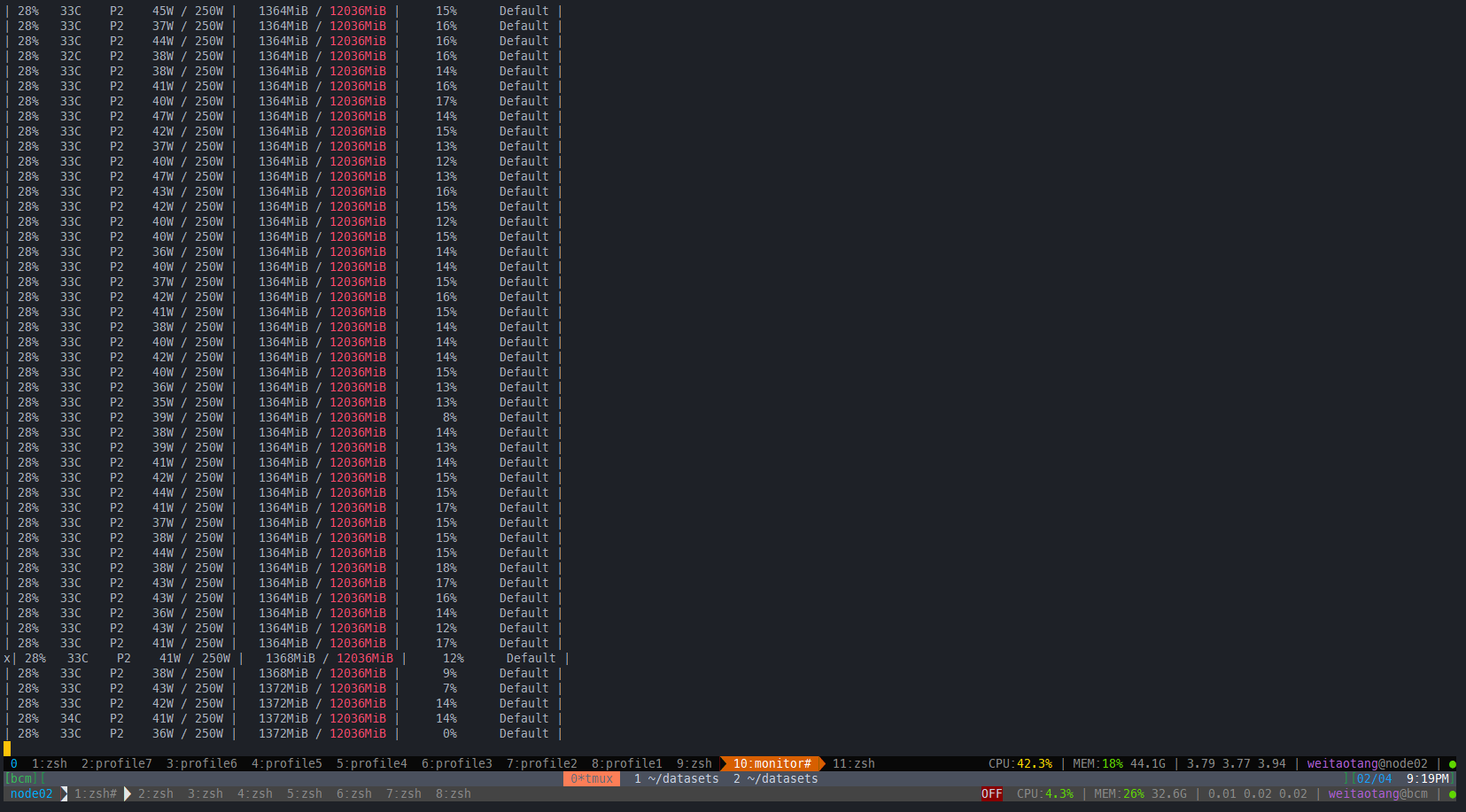
测试脚本
import torch
from torchvision import datasets, transforms
import time
if __name__ == '__main__':
use_cuda = torch.cuda.is_available()
for num_workers in range(0,50,5): # 遍历worker数
kwargs = {'num_workers': num_workers, 'pin_memory': False} if use_cuda else {}
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('./data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=64, shuffle=True, **kwargs)
start = time.time()
for epoch in range(1, 5):
for batch_idx, (data, target) in enumerate(train_loader): # 不断load
pass
end = time.time()
print("Finish with:{} second, num_workers={}".format(end-start,num_workers))data_prefetch核心代码
prefetcher = DataPrefetcher(self.data_loader)
batch_data = prefetcher.next()
batch_idx = 0
while batch_data is not None:
# for batch_idx, batch_data in enumerate(self.data_loader):
self.train_metrics.set_step()
inputs, labels, clean_labels = batch_data[:-2], batch_data[-2], batch_data[-1]
batch_idx += 1
batch_data = prefetcher.next()
def forward(self, *all_xs):
x_feats = []
with profiler.record_function("FORWARD-passing"):
for x, fc in zip(all_xs, self.all_fcs):
x_feats.append(fc(x))
with profiler.record_function("FORWARD-fusioning"):
if self.fusion == 'concat':
final = torch.cat(x_feats, dim=1)
fc = self.fc(final)
elif self.fusion == 'sum':
x_feats = torch.stack(x_feats, dim=0)
# x_feats = torch.cat([torch.unsqueeze(x_feat, dim=0) for x_feat in x_feats])
final = torch.sum(x_feats, dim=0)
fc = self.fc(final)
elif self.fusion == 'outer':
bs = x_feats[0].size(0)
device = x_feats[0].device
_x_hs = [
torch.cat((x_feat, torch.ones((bs, 1), requires_grad=False, dtype=torch.float, device=device)),
dim=1)
for x_feat in x_feats]
fusion_xs = [torch.matmul(_x_h, factor) for _x_h, factor in zip(_x_hs, self.factors)]
fusion_zy = reduce(mul, fusion_xs)
fc = torch.matmul(self.fusion_weights, fusion_zy.permute(1, 0, 2)).squeeze() + self.fusion_bias
fc = fc.view(-1, 6)
else:
raise ValueError("Not implemented fusion method:{}".format(self.fusion))
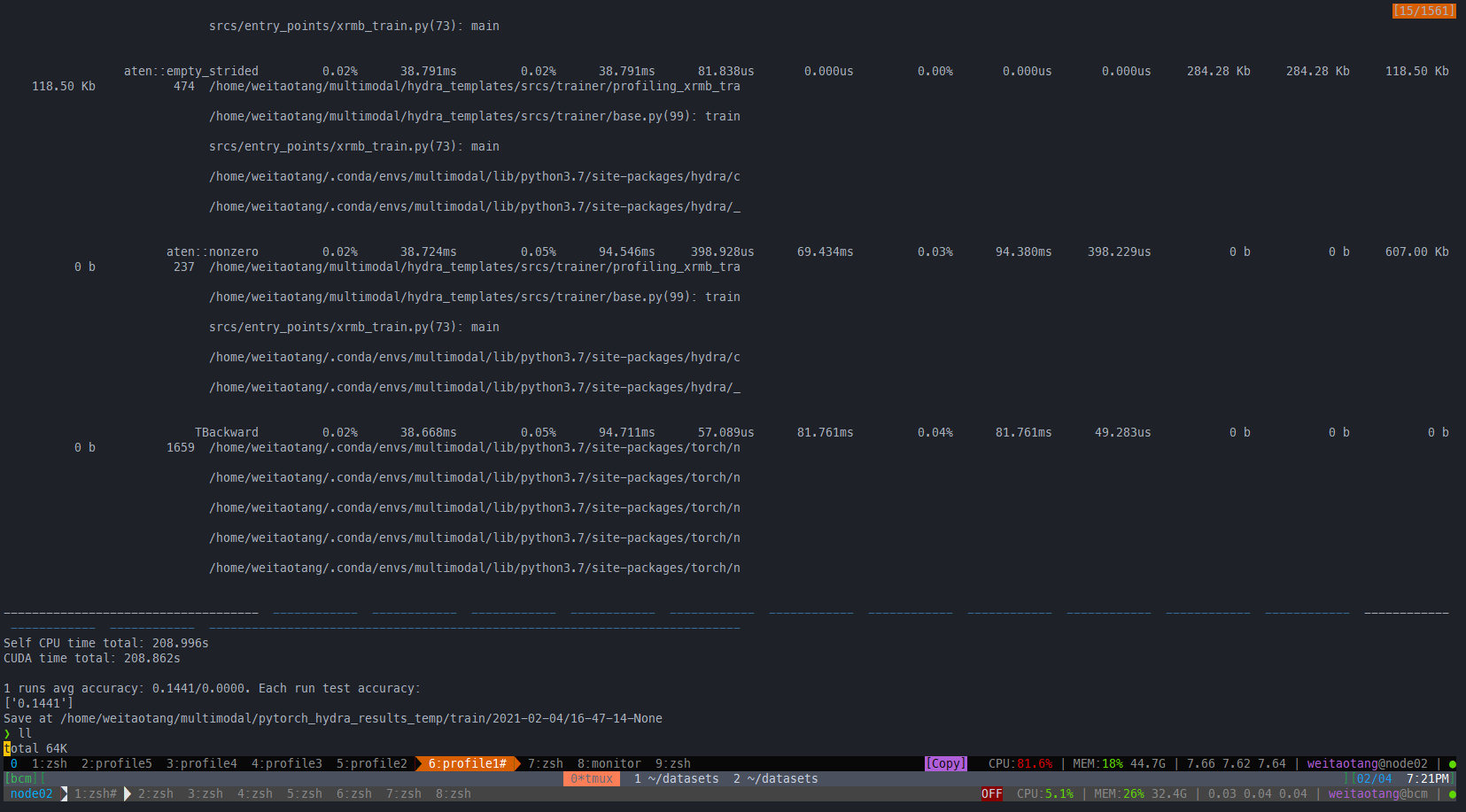
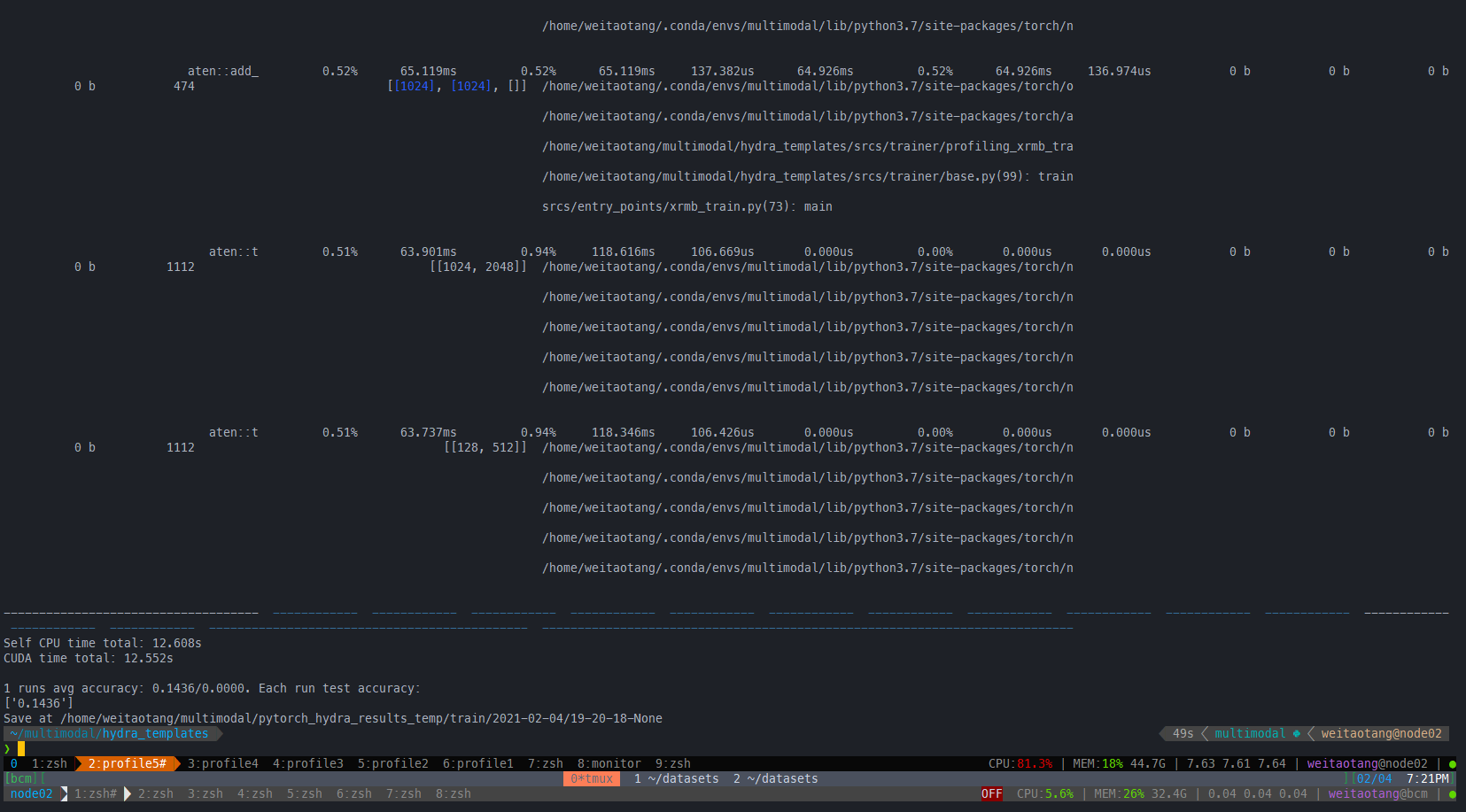
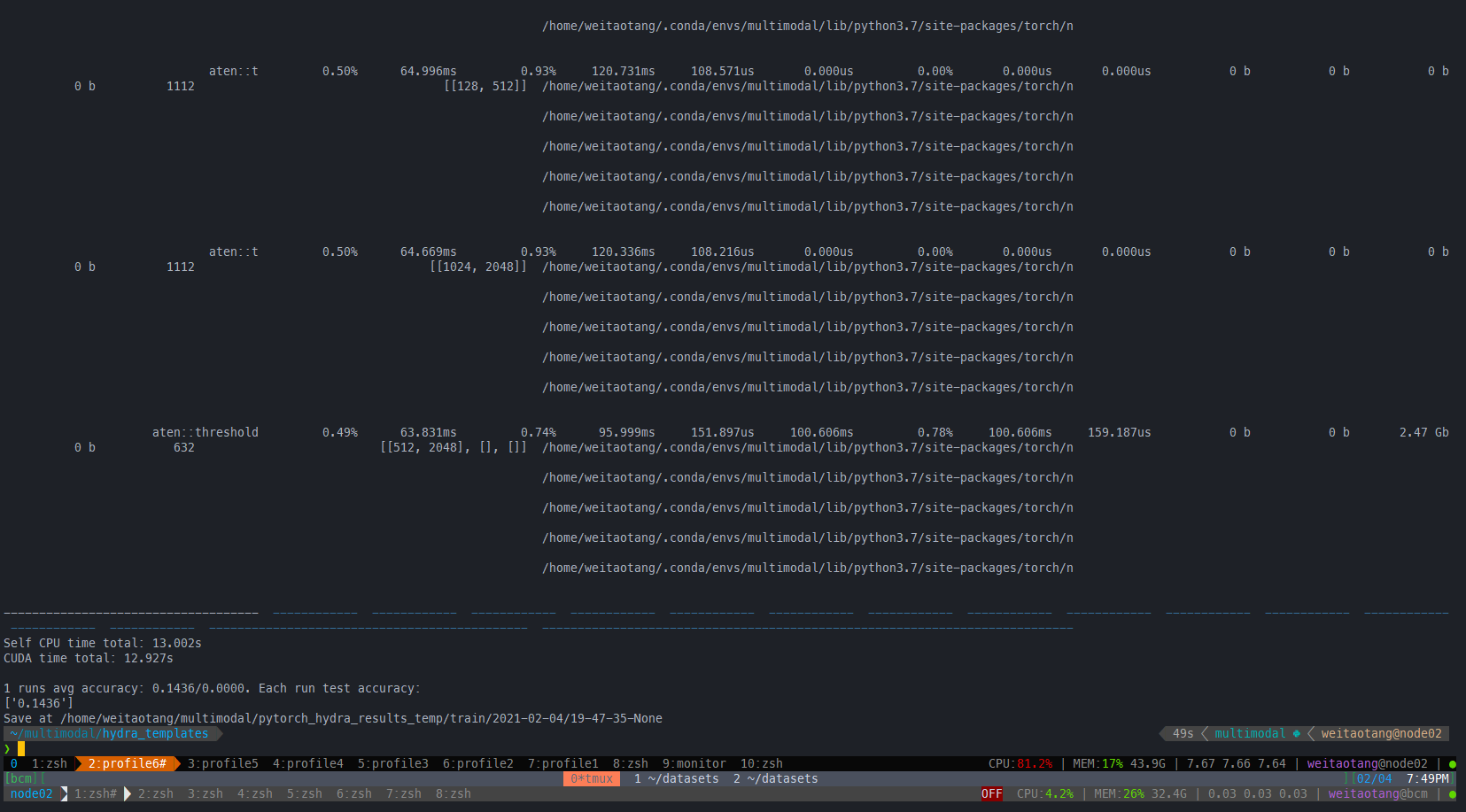
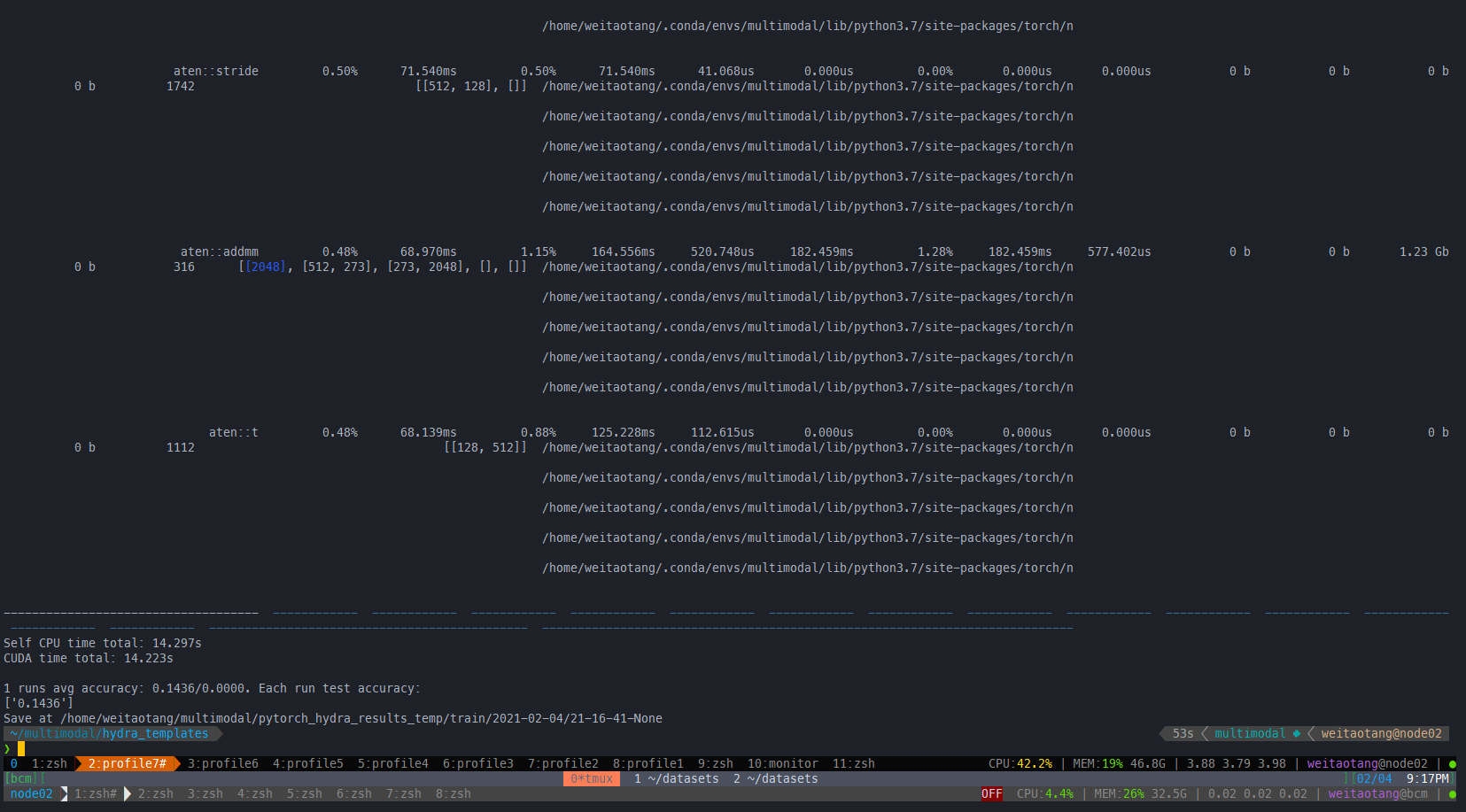
return fc在IEG 原版上:有一定的提升:
一个epoch:all_cuda=True
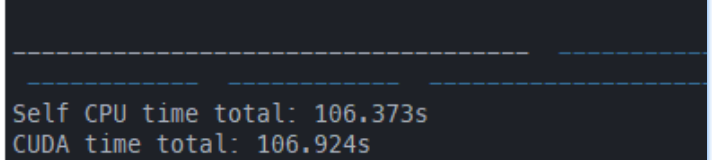
all_cuda=False
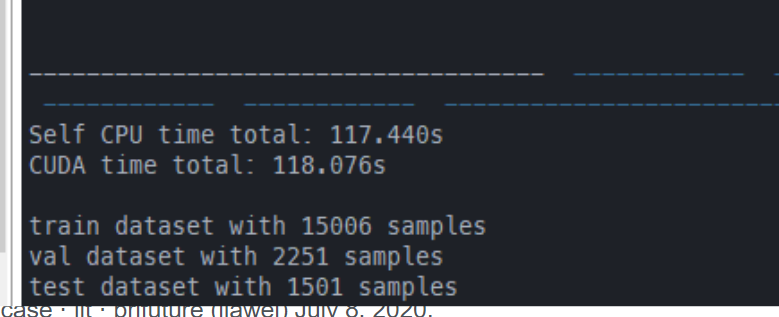
原来的:
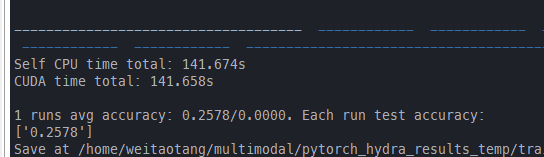
待查看
https://www.cnblogs.com/lylec/p/13597240.html
https://tianws.github.io/skill/2019/08/27/gpu-volatile/
DALI使用
首先应该看看这个Speeding up dataloading with DALI tutorial,其中的post1 Case Study: ResNet50 with DALI很重要
To verify that CPU is indeed the bottleneck in our training, let’s conduct a simple experiment. Normally the preprocessing of dataset is performed on the CPU (using libraries like NumPy or Pillow) while the training runs on the GPU. Furthermore, they work in parallel – the CPU processing of a batch runs at the same time that the GPU conducts forward and back propagation of the previous batch.
Let’s compare the speed of a regular ResNet50 data processing pipeline and a synthetic pipeline, in which no data augmentation occurs, only training. At this point we don’t care that the neural network won’t train; all we need is to compare the performance of the two pipelines.
If we observe no performance difference between these two pipelines in our experiment, then the CPU workload proves irrelevant. On the other hand, if we discover lower speed in the regular pipeline, it means that the CPU is the likely bottleneck for training.
Indeed, as table 1 shows, we observe a difference in the performance of these two pipelines. This observation indicates a bottleneck within the preprocessing pipeline occuring on the CPU. To address this situation, we can make use of DALI – the library exclusively designed to offload the preprocessing from CPU to GPU, thereby reducing or eliminating the CPU bottleneck.
所以使用DALI之前,应该通过synthetic inputs来测试整个pipeline,比如如果很少用到augmentation,那么显然瓶颈应该不在这
PyTorch - Accelerate DataLoader 其中提到,原博主自己使用过之后提升不明显
实测效果与官方的transform比,速度提升不明显(约10%): FER-2013, batch=256, epoch=1, GPU=0, 单GPU训练: 38s:43s FER-2013, batch=256, epoch=1, GPU=0, 双GPU训练: 27s:34s 调整dali的num_threads对速度基本无影响 FER-2013, batch=64, epoch=1, GPU=0, 双GPU训练: 41s:45s 在开始训练前, 官方的方法要等比较久的时间,而DALI开始的很快
Ravdess提速
确认augmentation步骤费时
参照上面DALI 使用,需要先把所有augmentation的步骤的关了进行对比
关闭augmentation:
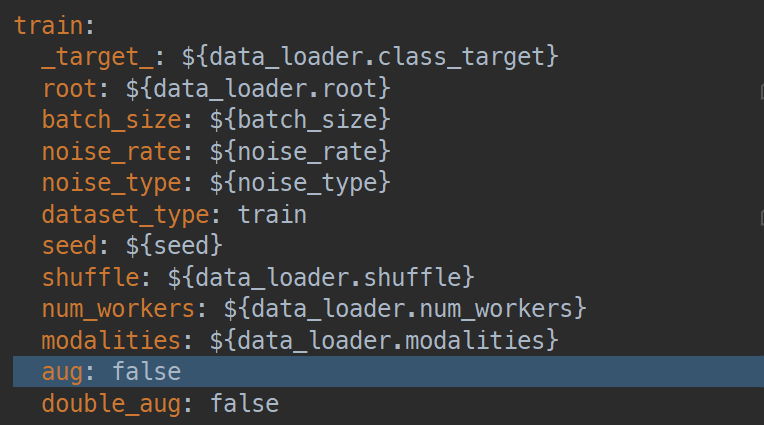
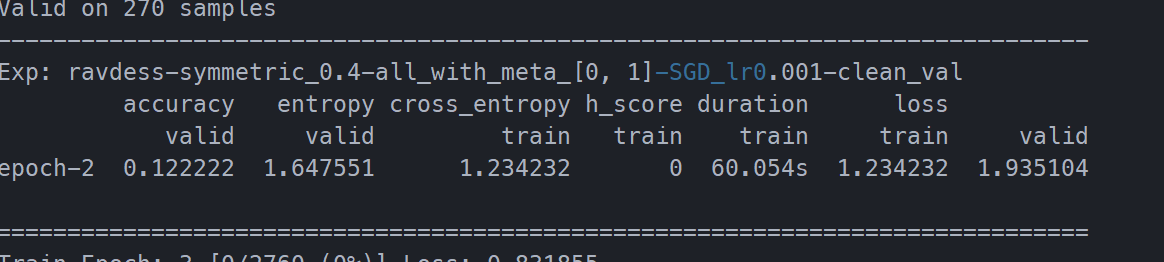
开启单次augmentation:
train_audio_transform = transforms.Compose([
# transforms.Resize((224, 224)),
transforms.ToTensor()
])
train_image_transform = transforms.Compose([
transforms.Resize((160, 160)),
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.RandomRotation(10),
transforms.ColorJitter(0.05, 0.05, 0.05, 0.05),
transforms.ToTensor()
])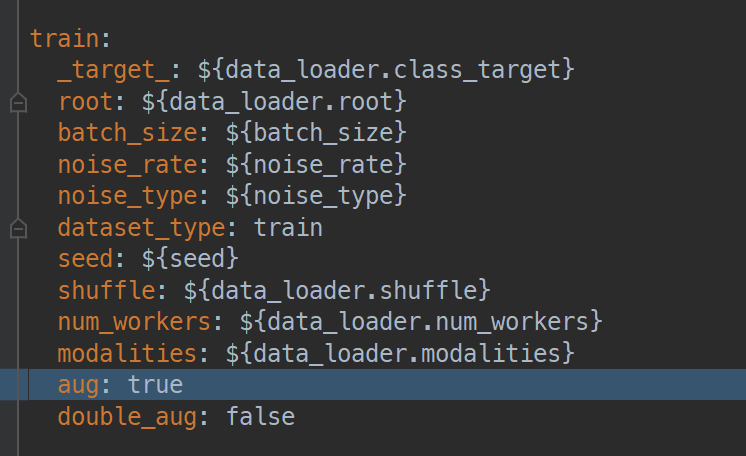
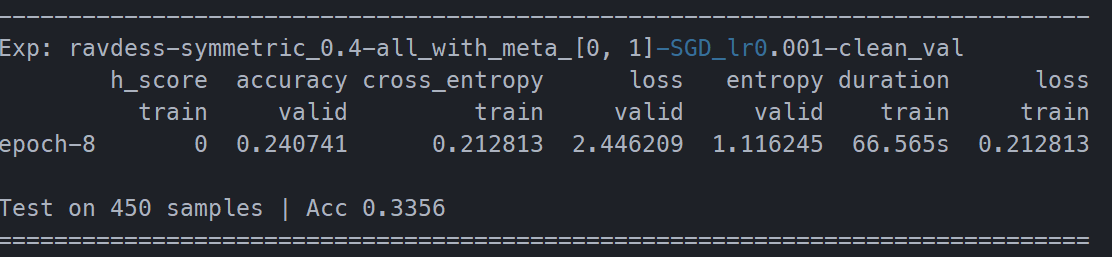
增加的时间不多
如果把所有image的augmentation也关了,则:
train_audio_transform = transforms.Compose([
# transforms.Resize((224, 224)),
transforms.ToTensor()
])
train_image_transform = transforms.Compose([
# transforms.Resize((160, 160)),
# transforms.RandomHorizontalFlip(),
# transforms.RandomVerticalFlip(),
# transforms.RandomRotation(10),
# transforms.ColorJitter(0.05, 0.05, 0.05, 0.05),
transforms.ToTensor()
])
也差不多要翻一倍
实测单模态(image/audio),有无augmentation的区别
audio由于本身就几乎没有augmentation(只有totensor),因此此处只记录一个情况:
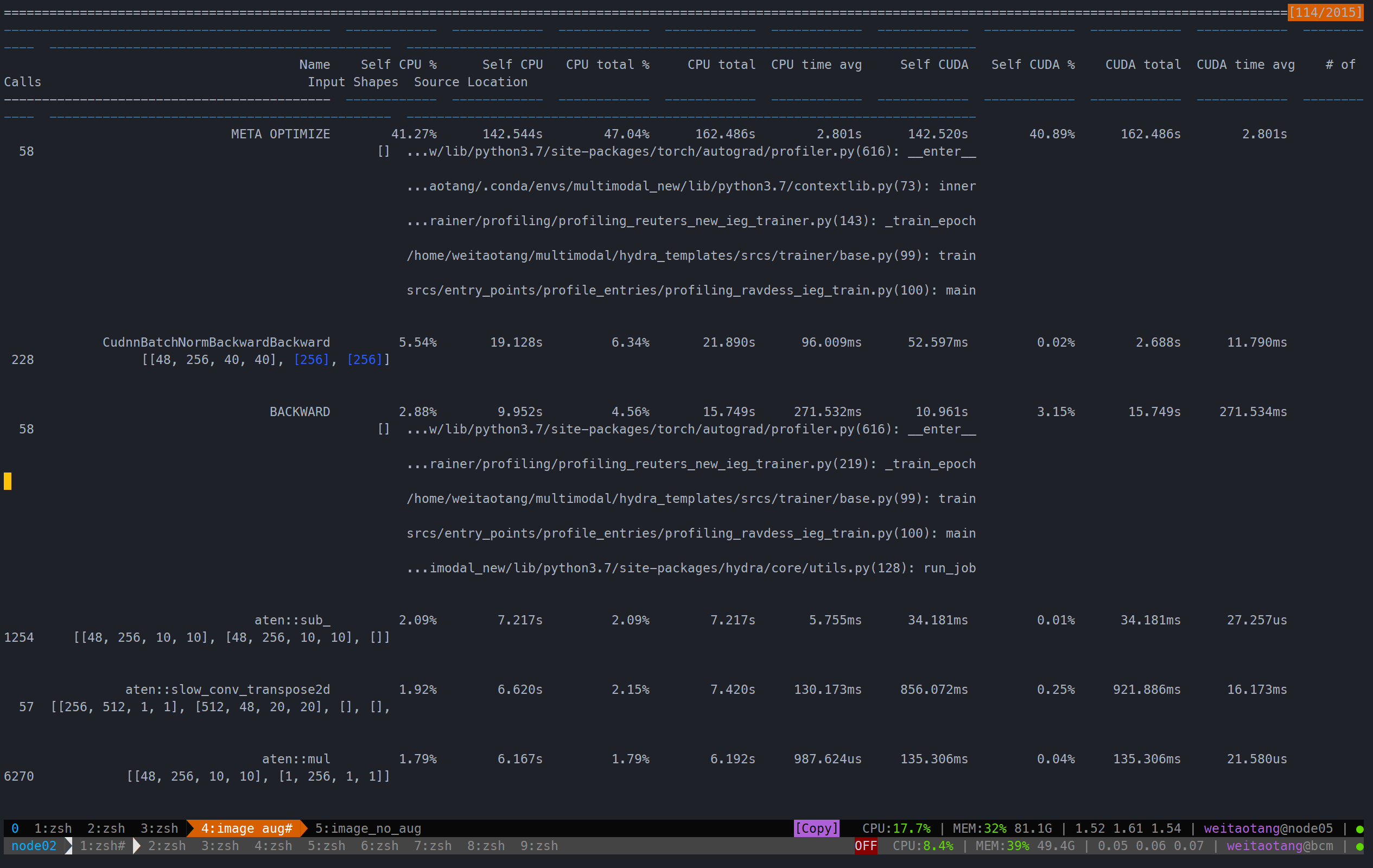
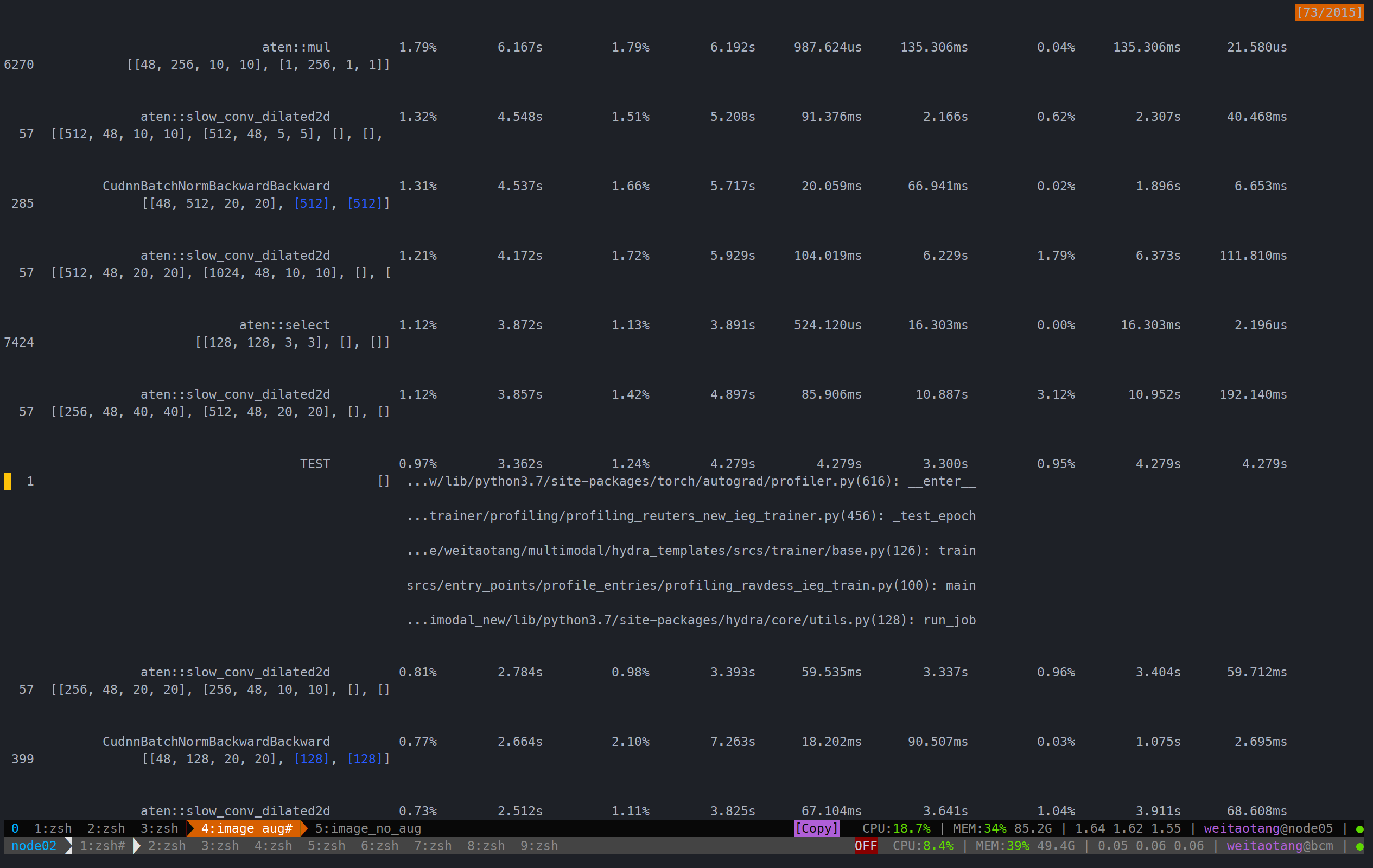
用时 111.650s
image下则显然更费时一些(哪怕完全关闭了augmentation)
完全没有augmentation:
Save at /home/weitaotang/multimodal/pytorch_hydra_results_temp/debug/2021-02-12/23-25-33-None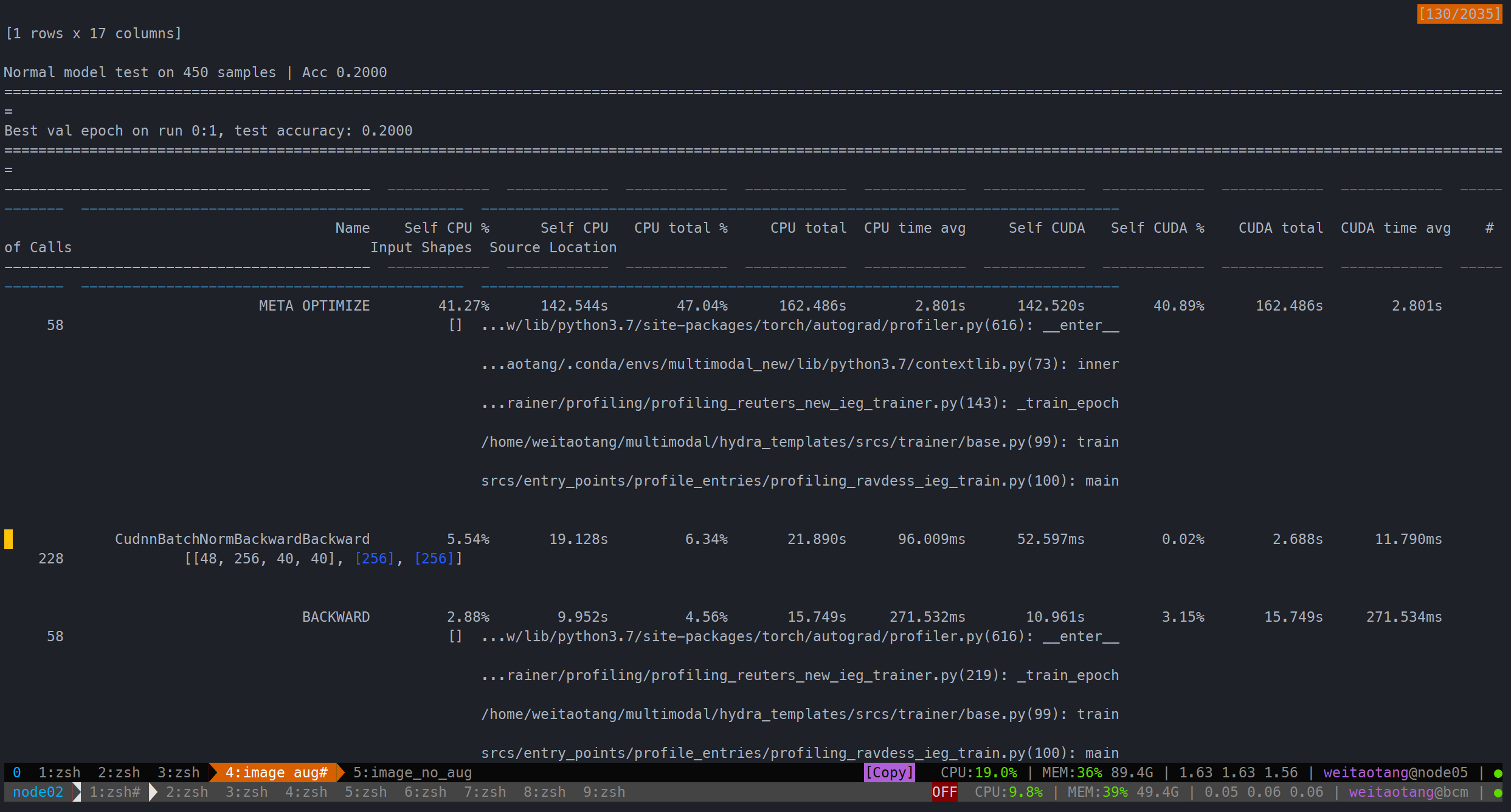
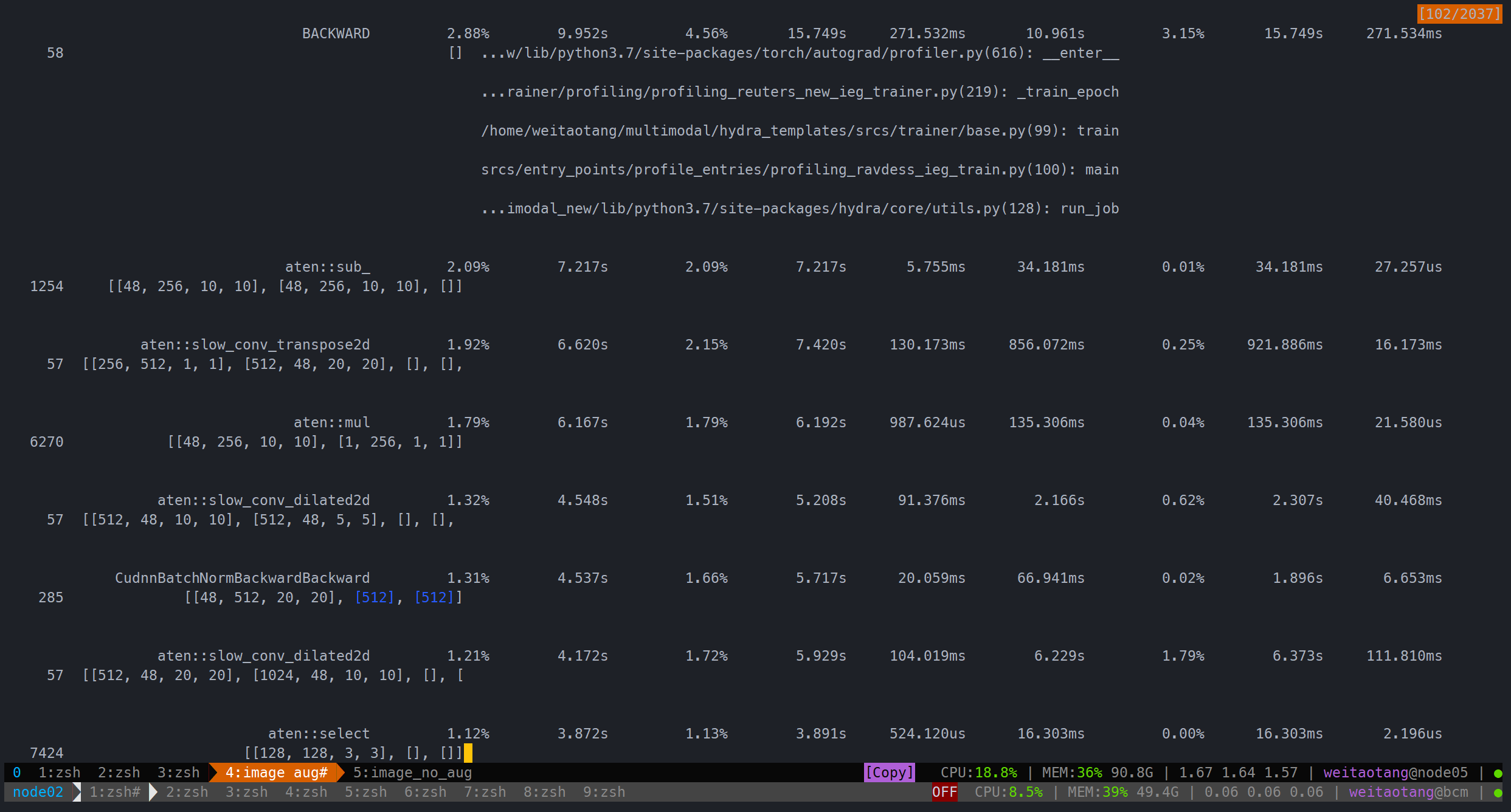
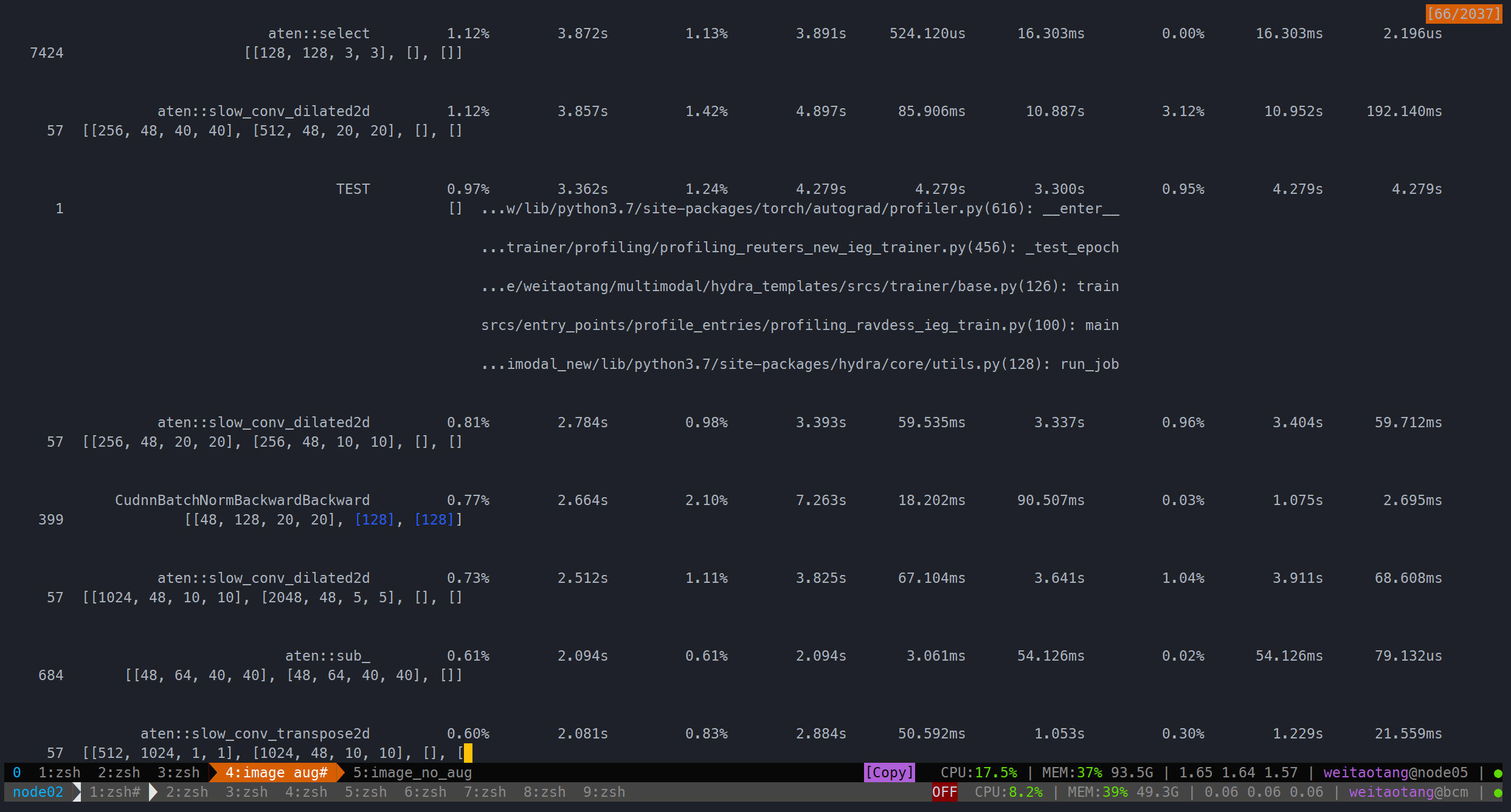
用时202.359s
单一augmentation:
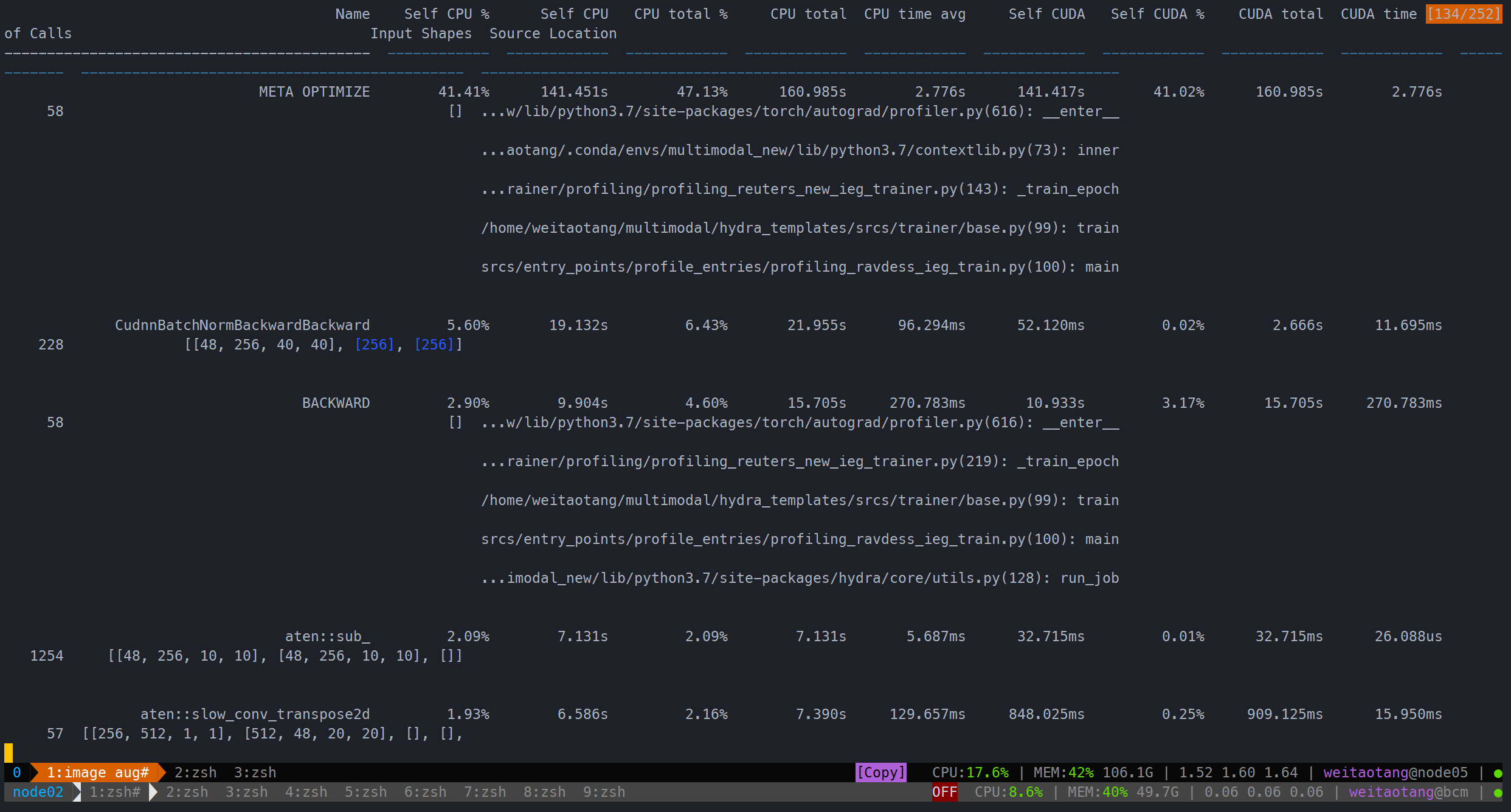
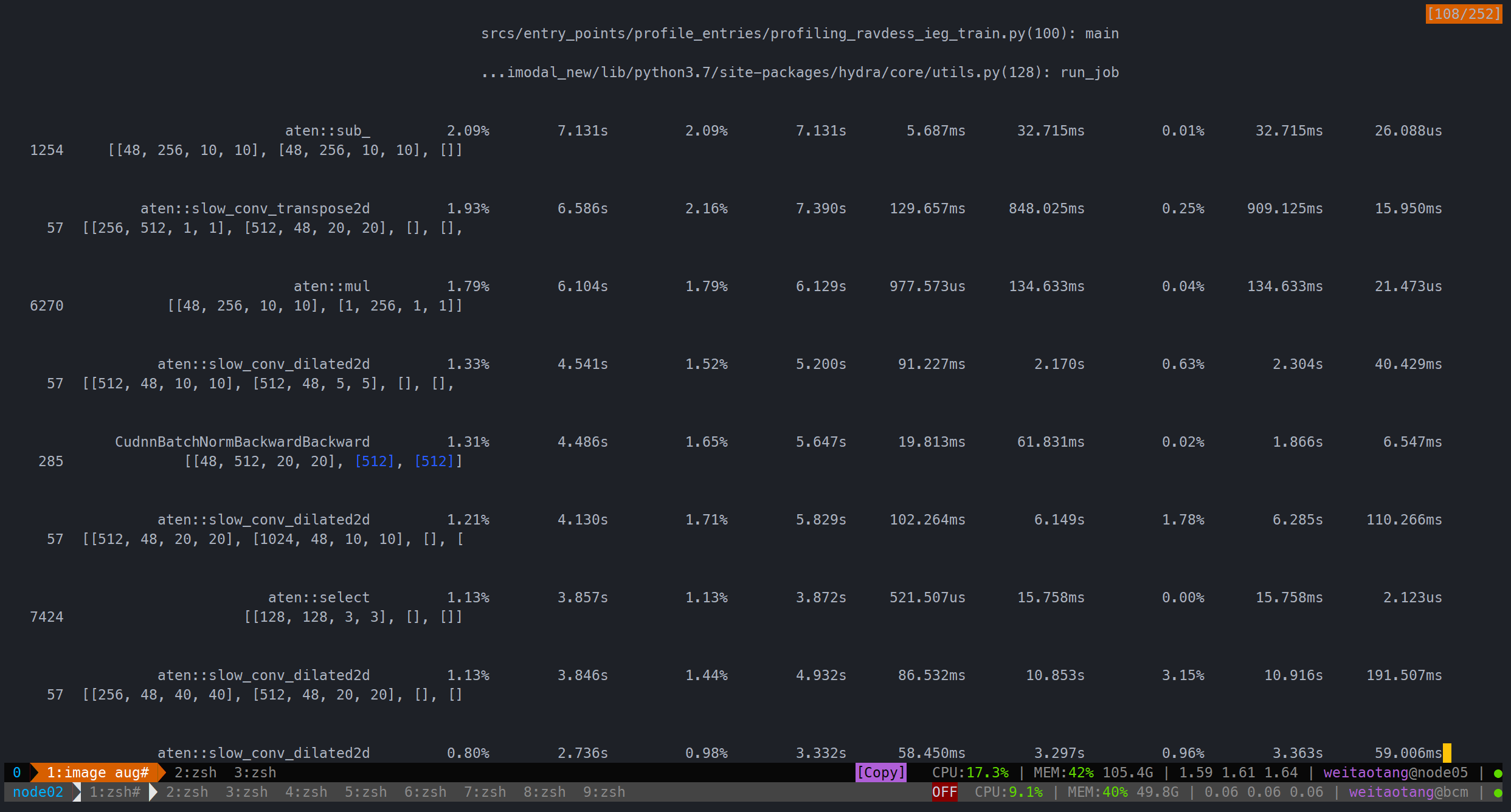
用时201.045s
综合下来可以看到似乎差别不大
