experiments-record
Image单模态,LR设为0.1不可训练(不可行)
并没有tanaka在joint optimization中提到的high learning rate能有助于不学习label noise
可以看到symmetric 0.4或者asymmetric 0.6在lr 0.1(10x)的情况下,准确率很差
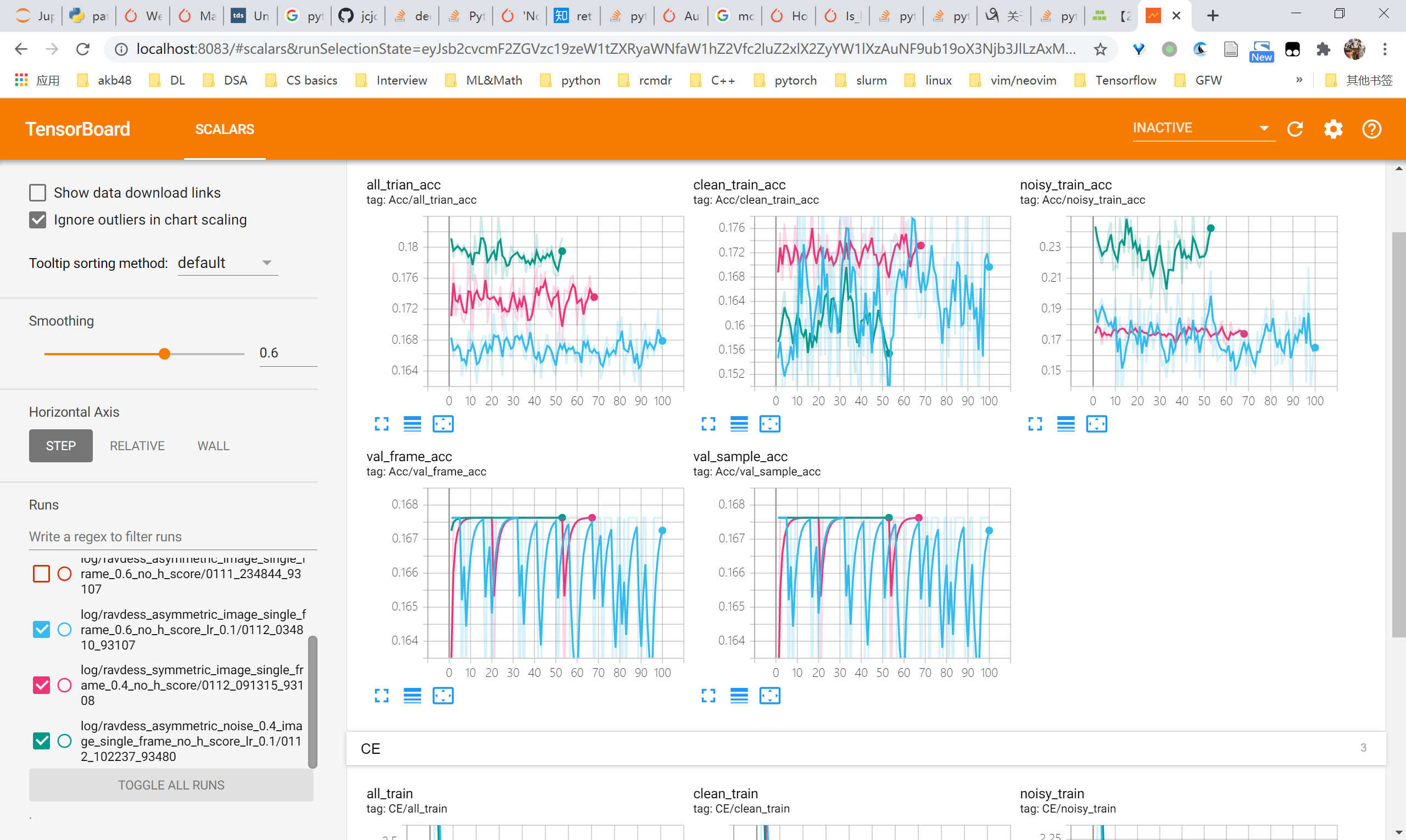
- symmetric noise 0.4,lr 0.1 vs lr 0.01
- asymmetric 0.4 lr 0.1 vs lr 0.01
LR设为0.05 0.005也不可行
- symmetric noise 0.4的情况下,对比可以看到0.1,0.05,0.005都不太行,只有0.01比较好
看loss也可以一开始的loss都是不太一样的,但是后面越训练越趋近
T Revision MNIST测试
symmetric noise 0.4
默认参数测试
MNIST 默认batch_size=128来看,估计的还算比较准确
batch_size = 12800, lr = 0.1
可以看到效果更差了,还是默认的参数比较好。而且也和估计前学习到的classifier有关
asymmetric noise 0.4
默认参数
Estimated transition matrix:
tensor([[7.2138e-01, 2.7854e-01, 3.0262e-06, 3.6738e-07, 1.2981e-07, 5.1001e-06,
1.8148e-05, 3.1714e-05, 1.3197e-06, 1.8157e-05],
[5.7726e-04, 6.2115e-01, 3.7681e-01, 1.3360e-04, 3.5784e-04, 8.6032e-05,
5.3814e-05, 1.9459e-04, 4.5552e-04, 1.8873e-04],
[9.7088e-06, 8.9477e-04, 6.8011e-01, 3.0870e-01, 6.0487e-03, 1.5677e-04,
2.0933e-04, 3.5460e-04, 3.0163e-03, 4.9286e-04],
[1.3503e-05, 7.5012e-05, 9.7758e-04, 5.4234e-01, 4.5637e-01, 1.6872e-04,
5.0566e-05, 1.7940e-07, 3.3701e-06, 8.3027e-06],
[4.8065e-06, 9.4964e-06, 6.2487e-05, 3.7153e-05, 7.0554e-01, 2.9411e-01,
1.7484e-04, 4.4826e-05, 8.6875e-06, 5.9524e-06],
[7.3357e-05, 1.3101e-05, 1.3800e-06, 5.4869e-05, 6.3327e-04, 6.3130e-01,
3.6769e-01, 9.2295e-05, 6.4091e-05, 7.0743e-05],
[1.5855e-03, 8.7621e-04, 3.1088e-05, 7.7596e-06, 6.9697e-05, 2.1452e-02,
6.4550e-01, 3.3030e-01, 6.9375e-05, 1.0396e-04],
[8.1278e-04, 2.3544e-04, 5.0871e-05, 7.7580e-05, 7.5762e-05, 8.7224e-04,
3.7420e-04, 6.6014e-01, 3.3609e-01, 1.2711e-03],
[1.9071e-03, 3.5230e-04, 2.1717e-03, 9.8912e-04, 1.4255e-03, 3.2609e-04,
2.6533e-04, 1.0653e-04, 6.1251e-01, 3.7995e-01],
[4.0376e-01, 5.3920e-07, 3.7207e-07, 5.6868e-06, 4.2000e-04, 1.2035e-04,
7.1814e-07, 1.5838e-04, 2.0765e-04, 5.9533e-01]], device='cuda:0')
True transition matrix:
[[0.6 0.4 0. 0. 0. 0. 0. 0. 0. 0. ]
[0. 0.6 0.4 0. 0. 0. 0. 0. 0. 0. ]
[0. 0. 0.6 0.4 0. 0. 0. 0. 0. 0. ]
[0. 0. 0. 0.6 0.4 0. 0. 0. 0. 0. ]
[0. 0. 0. 0. 0.6 0.4 0. 0. 0. 0. ]
[0. 0. 0. 0. 0. 0.6 0.4 0. 0. 0. ]
[0. 0. 0. 0. 0. 0. 0.6 0.4 0. 0. ]
[0. 0. 0. 0. 0. 0. 0. 0.6 0.4 0. ]
[0. 0. 0. 0. 0. 0. 0. 0. 0.6 0.4]
[0.4 0. 0. 0. 0. 0. 0. 0. 0. 0.6]]
The estimation error is 0.11802714886404604
总体还是估计的比较准
T Revision CIFAR10测试
symmetric noise 0.4
默认参数
- 可以看到还是有一定的准确率的,至少能够保证对角线上的元素不会接近于1,但同时也是同一行最大的元素
[[0.6 0.04444444 0.04444444 0.04444444 0.04444444 0.04444444
0.04444444 0.04444444 0.04444444 0.04444444]
[0.04444444 0.6 0.04444444 0.04444444 0.04444444 0.04444444
0.04444444 0.04444444 0.04444444 0.04444444]
[0.04444444 0.04444444 0.6 0.04444444 0.04444444 0.04444444
0.04444444 0.04444444 0.04444444 0.04444444]
[0.04444444 0.04444444 0.04444444 0.6 0.04444444 0.04444444
0.04444444 0.04444444 0.04444444 0.04444444]
[0.04444444 0.04444444 0.04444444 0.04444444 0.6 0.04444444
0.04444444 0.04444444 0.04444444 0.04444444]
[0.04444444 0.04444444 0.04444444 0.04444444 0.04444444 0.6
0.04444444 0.04444444 0.04444444 0.04444444]
[0.04444444 0.04444444 0.04444444 0.04444444 0.04444444 0.04444444
0.6 0.04444444 0.04444444 0.04444444]
[0.04444444 0.04444444 0.04444444 0.04444444 0.04444444 0.04444444
0.04444444 0.6 0.04444444 0.04444444]
[0.04444444 0.04444444 0.04444444 0.04444444 0.04444444 0.04444444
0.04444444 0.04444444 0.6 0.04444444]
[0.04444444 0.04444444 0.04444444 0.04444444 0.04444444 0.04444444
0.04444444 0.04444444 0.04444444 0.6 ]]
[[0.6 0.04444444 0.04444444 0.04444444 0.04444444 0.04444444
0.04444444 0.04444444 0.04444444 0.04444444]
[0.04444444 0.6 0.04444444 0.04444444 0.04444444 0.04444444
0.04444444 0.04444444 0.04444444 0.04444444]
[0.04444444 0.04444444 0.6 0.04444444 0.04444444 0.04444444
0.04444444 0.04444444 0.04444444 0.04444444]
[0.04444444 0.04444444 0.04444444 0.6 0.04444444 0.04444444
0.04444444 0.04444444 0.04444444 0.04444444]
[0.04444444 0.04444444 0.04444444 0.04444444 0.6 0.04444444
0.04444444 0.04444444 0.04444444 0.04444444]
[0.04444444 0.04444444 0.04444444 0.04444444 0.04444444 0.6
0.04444444 0.04444444 0.04444444 0.04444444]
[0.04444444 0.04444444 0.04444444 0.04444444 0.04444444 0.04444444
0.6 0.04444444 0.04444444 0.04444444]
[0.04444444 0.04444444 0.04444444 0.04444444 0.04444444 0.04444444
0.04444444 0.6 0.04444444 0.04444444]
[0.04444444 0.04444444 0.04444444 0.04444444 0.04444444 0.04444444
0.04444444 0.04444444 0.6 0.04444444]
[0.04444444 0.04444444 0.04444444 0.04444444 0.04444444 0.04444444
0.04444444 0.04444444 0.04444444 0.6 ]]
Val Loss: 1.945421, Acc: 0.431000 [0/373]
epoch 20
Train Loss: 1.740070, Acc: 0.479556
Val Loss: 1.973744, Acc: 0.431400
Estimated transition matrix:
tensor([[0.4469, 0.0260, 0.1041, 0.0390, 0.1306, 0.0741, 0.0450, 0.0878, 0.0115,
0.0351],
[0.0220, 0.6145, 0.0254, 0.0339, 0.0490, 0.0716, 0.0512, 0.0372, 0.0461,
0.0492],
[0.0606, 0.0301, 0.4259, 0.0794, 0.0816, 0.0407, 0.0582, 0.0853, 0.0927,
0.0454],
[0.0399, 0.0185, 0.0344, 0.5259, 0.0116, 0.1639, 0.0885, 0.0600, 0.0253,
0.0321],
[0.0338, 0.0265, 0.0805, 0.0910, 0.5191, 0.0445, 0.0589, 0.0735, 0.0252,
0.0470],
[0.0309, 0.0330, 0.0383, 0.0972, 0.0380, 0.4335, 0.0312, 0.2013, 0.0714,
0.0252],
[0.0274, 0.0401, 0.0219, 0.0906, 0.1141, 0.0547, 0.5203, 0.0391, 0.0442,
0.0476],
[0.0377, 0.0196, 0.0225, 0.0213, 0.0454, 0.0261, 0.0224, 0.7676, 0.0175,
0.0199],
[0.0248, 0.0538, 0.0659, 0.0488, 0.0559, 0.0609, 0.0244, 0.0700, 0.4952,
0.1002],
[0.0261, 0.0160, 0.0332, 0.0479, 0.0088, 0.0322, 0.0142, 0.0486, 0.0229,
0.7501]], device='cuda:0')
True transition matrix:
[[0.6 0.04444444 0.04444444 0.04444444 0.04444444 0.04444444
0.04444444 0.04444444 0.04444444 0.04444444]
[0.04444444 0.6 0.04444444 0.04444444 0.04444444 0.04444444
0.04444444 0.04444444 0.04444444 0.04444444]
[0.04444444 0.04444444 0.6 0.04444444 0.04444444 0.04444444
0.04444444 0.04444444 0.04444444 0.04444444]
[0.04444444 0.04444444 0.04444444 0.6 0.04444444 0.04444444
0.04444444 0.04444444 0.04444444 0.04444444]
[0.04444444 0.04444444 0.04444444 0.04444444 0.6 0.04444444
0.04444444 0.04444444 0.04444444 0.04444444]
[0.04444444 0.04444444 0.04444444 0.04444444 0.04444444 0.6
0.04444444 0.04444444 0.04444444 0.04444444]
[0.04444444 0.04444444 0.04444444 0.04444444 0.04444444 0.04444444
0.6 0.04444444 0.04444444 0.04444444]
[0.04444444 0.04444444 0.04444444 0.04444444 0.04444444 0.04444444
0.04444444 0.6 0.04444444 0.04444444]
[0.04444444 0.04444444 0.04444444 0.04444444 0.04444444 0.04444444
0.04444444 0.04444444 0.6 0.04444444]
[0.04444444 0.04444444 0.04444444 0.04444444 0.04444444 0.04444444
0.04444444 0.04444444 0.04444444 0.6 ]]
The estimation error is 0.32300532655583486
Estimate finish.....Training......
asymmetric 0.4
- 默认参数
Actual noise 0.40
[[0.6 0.4 0. 0. 0. 0. 0. 0. 0. 0. ]
[0. 0.6 0.4 0. 0. 0. 0. 0. 0. 0. ]
[0. 0. 0.6 0.4 0. 0. 0. 0. 0. 0. ]
[0. 0. 0. 0.6 0.4 0. 0. 0. 0. 0. ]
[0. 0. 0. 0. 0.6 0.4 0. 0. 0. 0. ]
[0. 0. 0. 0. 0. 0.6 0.4 0. 0. 0. ]
[0. 0. 0. 0. 0. 0. 0.6 0.4 0. 0. ]
[0. 0. 0. 0. 0. 0. 0. 0.6 0.4 0. ]
[0. 0. 0. 0. 0. 0. 0. 0. 0.6 0.4]
[0.4 0. 0. 0. 0. 0. 0. 0. 0. 0.6]]
Actual noise 0.40
[[0.6 0.4 0. 0. 0. 0. 0. 0. 0. 0. ]
[0. 0.6 0.4 0. 0. 0. 0. 0. 0. 0. ]
[0. 0. 0.6 0.4 0. 0. 0. 0. 0. 0. ]
[0. 0. 0. 0.6 0.4 0. 0. 0. 0. 0. ]
[0. 0. 0. 0. 0.6 0.4 0. 0. 0. 0. ]
[0. 0. 0. 0. 0. 0.6 0.4 0. 0. 0. ]
[0. 0. 0. 0. 0. 0. 0.6 0.4 0. 0. ]
[0. 0. 0. 0. 0. 0. 0. 0.6 0.4 0. ]
[0. 0. 0. 0. 0. 0. 0. 0. 0.6 0.4]
[0.4 0. 0. 0. 0. 0. 0. 0. 0. 0.6]]
Estimate transition matirx......Waiting......
epoch 1
Train Loss: 1.020411, Acc: 0.518000
Val Loss: 1.220109, Acc: 0.464000
epoch 20
Train Loss: 1.005580, Acc: 0.521067
Val Loss: 1.226898, Acc: 0.463200
Estimated transition matrix:
tensor([[7.4242e-01, 2.4246e-01, 2.7850e-03, 8.4317e-04, 4.9211e-04, 5.2459e-04,
1.8819e-04, 7.3340e-04, 4.9761e-03, 4.5775e-03],
[6.8398e-04, 6.4443e-01, 3.5391e-01, 2.6642e-05, 1.2400e-05, 1.3245e-05,
1.8296e-04, 1.0236e-04, 2.1593e-04, 4.2654e-04],
[3.7985e-05, 5.2442e-01, 4.7549e-01, 2.8910e-07, 3.6711e-08, 6.9056e-08,
1.0048e-07, 3.4097e-07, 4.7454e-06, 4.9120e-05],
[8.2929e-03, 1.5819e-03, 3.0692e-02, 5.7357e-01, 3.0599e-01, 2.9479e-02,
2.8462e-02, 1.5182e-02, 2.5711e-03, 4.1792e-03],
[1.3662e-03, 1.9915e-04, 7.3622e-03, 1.8071e-02, 5.7474e-01, 3.8528e-01,
9.2216e-03, 3.4835e-03, 2.1991e-04, 5.0631e-05],
[1.0864e-03, 6.3302e-04, 8.7667e-03, 6.2122e-02, 5.6899e-02, 4.8854e-01,
3.3600e-01, 3.4640e-02, 1.1092e-02, 2.2156e-04],
[1.5093e-04, 8.9852e-05, 1.7349e-04, 4.1022e-04, 3.8422e-04, 1.3375e-04,
6.2308e-01, 3.7530e-01, 1.9503e-04, 8.2571e-05],
[1.1851e-03, 1.3255e-03, 7.4400e-04, 3.6824e-04, 1.6724e-03, 1.8169e-03,
4.6614e-04, 6.3631e-01, 3.5525e-01, 8.6169e-04],
[3.1831e-03, 1.4675e-03, 2.6400e-04, 5.8988e-05, 7.8735e-05, 3.5662e-05,
1.6588e-05, 1.1765e-04, 6.6807e-01, 3.2671e-01],
[2.4795e-01, 5.7143e-02, 4.9979e-02, 6.4383e-06, 8.2659e-07, 1.5378e-06,
5.9085e-06, 2.6324e-06, 4.2720e-05, 6.4487e-01]], device='cuda:0')
True transition matrix:
[[0.6 0.4 0. 0. 0. 0. 0. 0. 0. 0. ]
[0. 0.6 0.4 0. 0. 0. 0. 0. 0. 0. ]
[0. 0. 0.6 0.4 0. 0. 0. 0. 0. 0. ]
[0. 0. 0. 0.6 0.4 0. 0. 0. 0. 0. ]
[0. 0. 0. 0. 0.6 0.4 0. 0. 0. 0. ]
[0. 0. 0. 0. 0. 0.6 0.4 0. 0. 0. ]
[0. 0. 0. 0. 0. 0. 0.6 0.4 0. 0. ]
[0. 0. 0. 0. 0. 0. 0. 0.6 0.4 0. ]
[0. 0. 0. 0. 0. 0. 0. 0. 0.6 0.4]
[0.4 0. 0. 0. 0. 0. 0. 0. 0. 0.6]]
The estimation error is 0.2717611408448902
Estimate finish.....Training......
关于DMI
无论是哪个任务,都需要在pretrain
参考 Why bad performance without model pre-training?
作者的观点:
Hi,
Sorry for the late response. It’s a very good question. My guess is that if we don’t pretrain and directly apply L_dmi for training, the gradient is exploded and it’s very hard to schedule the learning rate.
To illustrate this, the gradient to the matrix A under $L_dmi$ loss is : $\partial log(∣det(A)∣) =(A^{−1})^T$. Note that when we random intialize a classifiers, the $det(A)$ or $det(submatrix of A)$ is rathely small. It leads to very large elements in $(A^{−1})^T$. Hence the gradient explode.
If we pretrain the model for a while, det(A) or det(submatrix of A) would be much more amendable.
Thanks.
Yilun
具体操作:
- 把原来的noisy train set划分出一个noisy validation set,预训练和正式训练差不多的epoch数,然后保存在noisy/clean validation上最好的模型
- load 1中获得的模型,继续用DMI LOSS在同一的noisy validation set上训练,同样通过noisy/clean validation set筛选出“最好的”模型,在clean test set上学习。
例如:
- 在CIFAR10的实验中,用的是noisy validation
- 在Clothing 1M中,则是用的clean validation(50k clean training数据)
对DMI的尝试
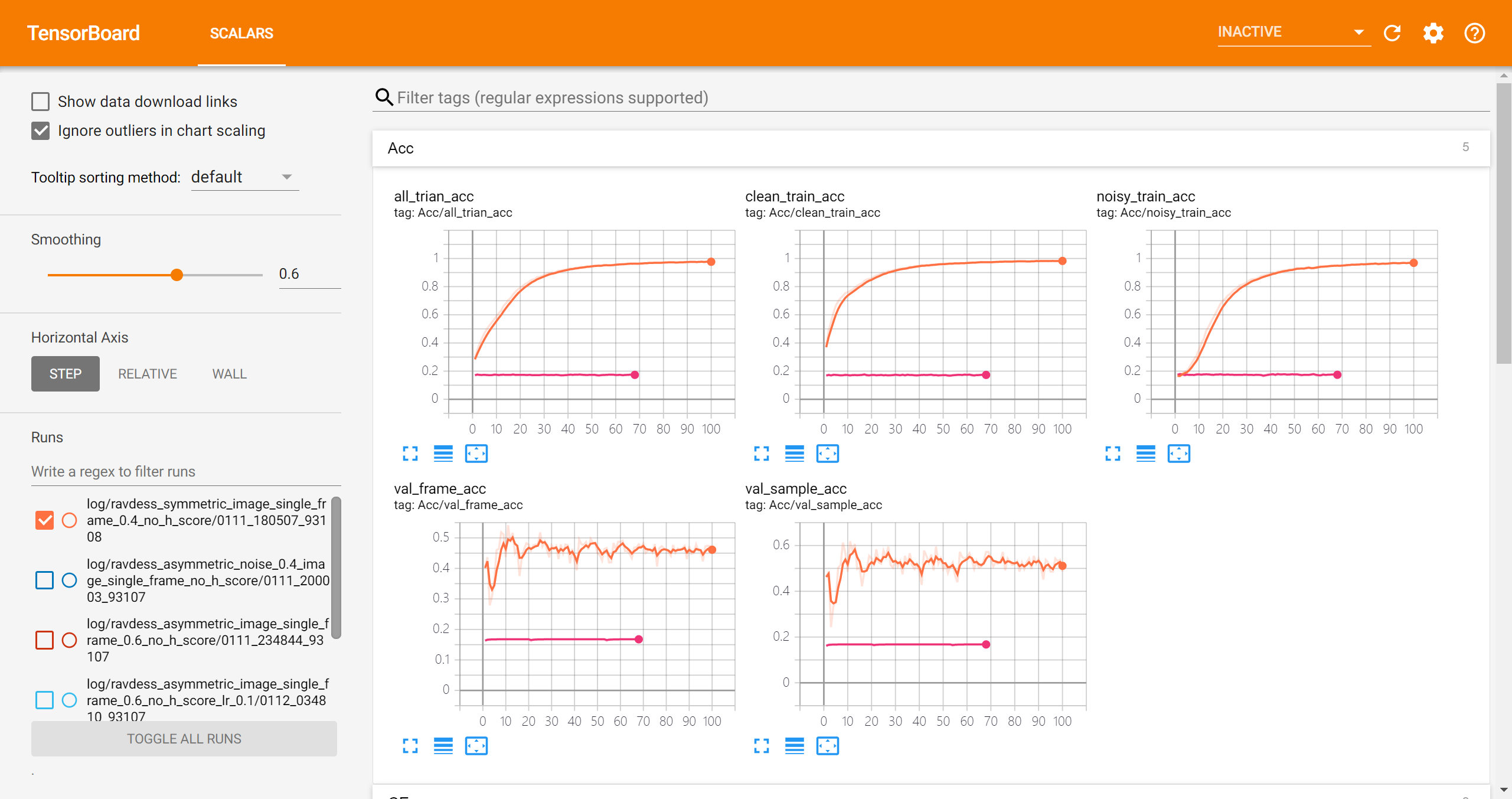
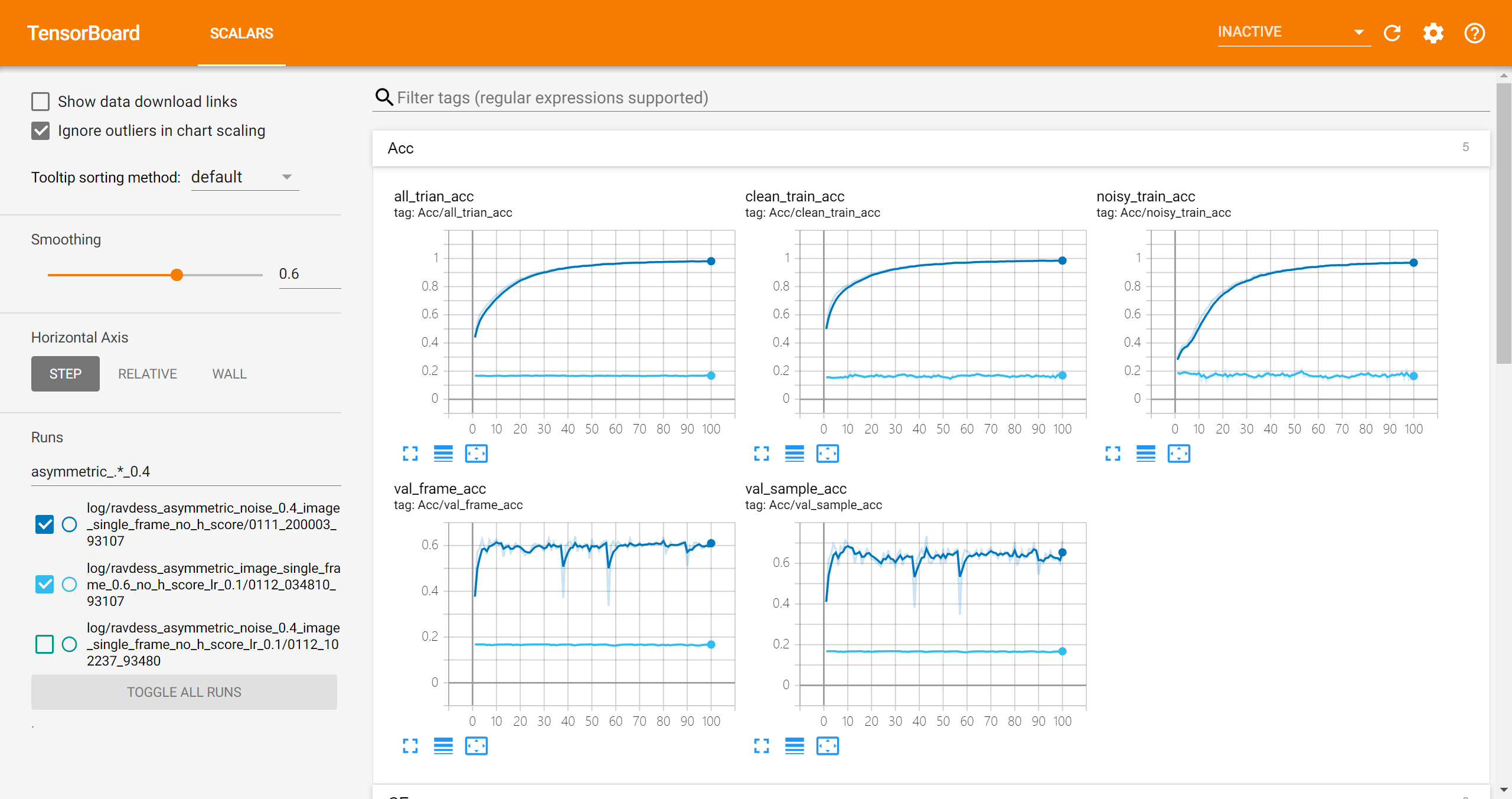
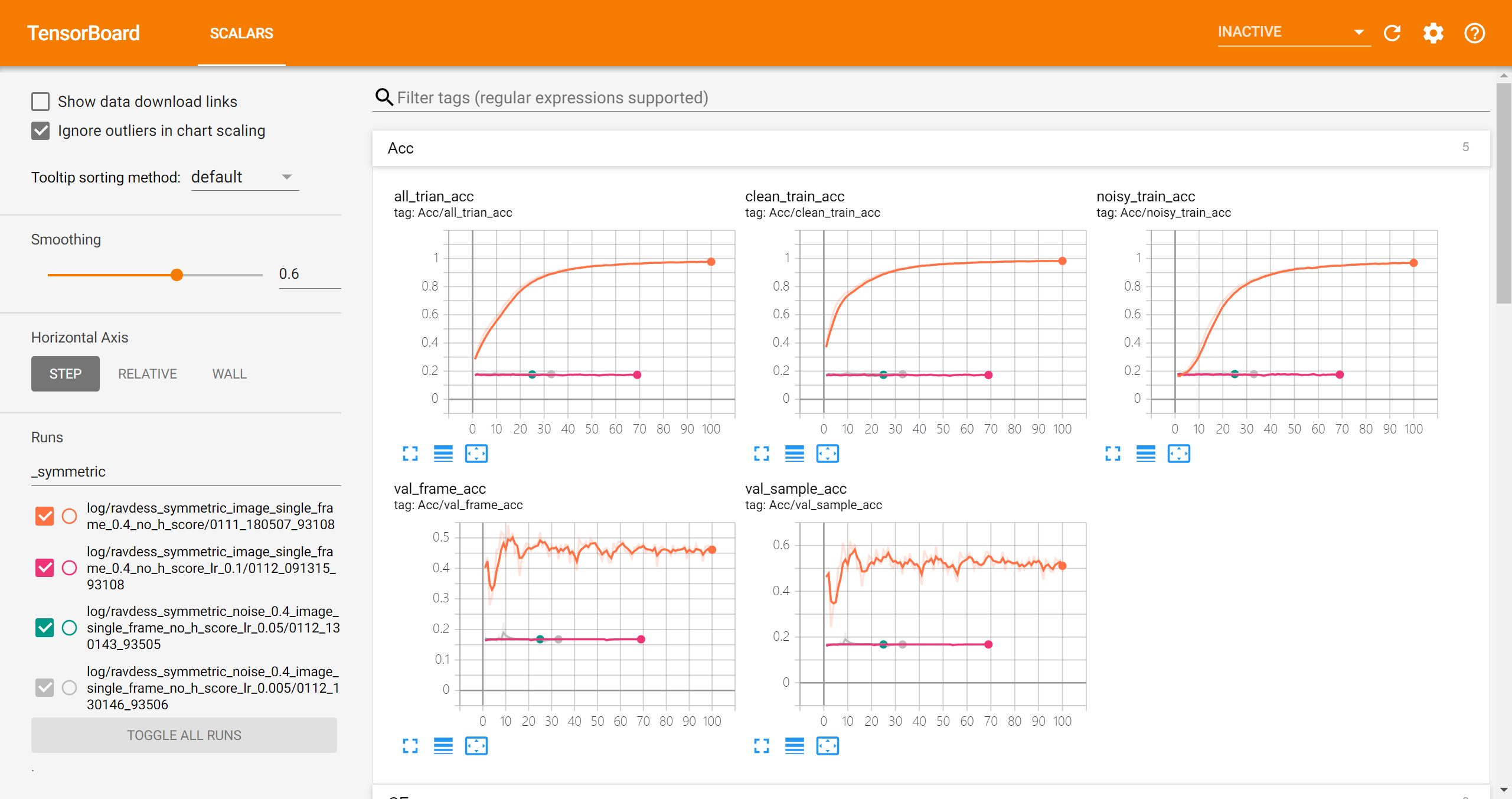
symmetric noise 0.4 + pretrain 15 epochs
- 加载ckpt
/home/weitaotang/multimodal/results_temp/image_single_frame/models/ravdess_symmetric_image_single_frame_0.4_no_h_score/0111_180507_93108/checkpoint-epoch15.pth - SGD: lr 1e-07, mementum 0.9, weight_decay 1e-3
可以看到总体来说是能够学习到clean的信息的:
- clean sample的frame accuracy比noisy sample的大
- 在validation set上的accuracy经过16个epoch的训练后两个点的提升
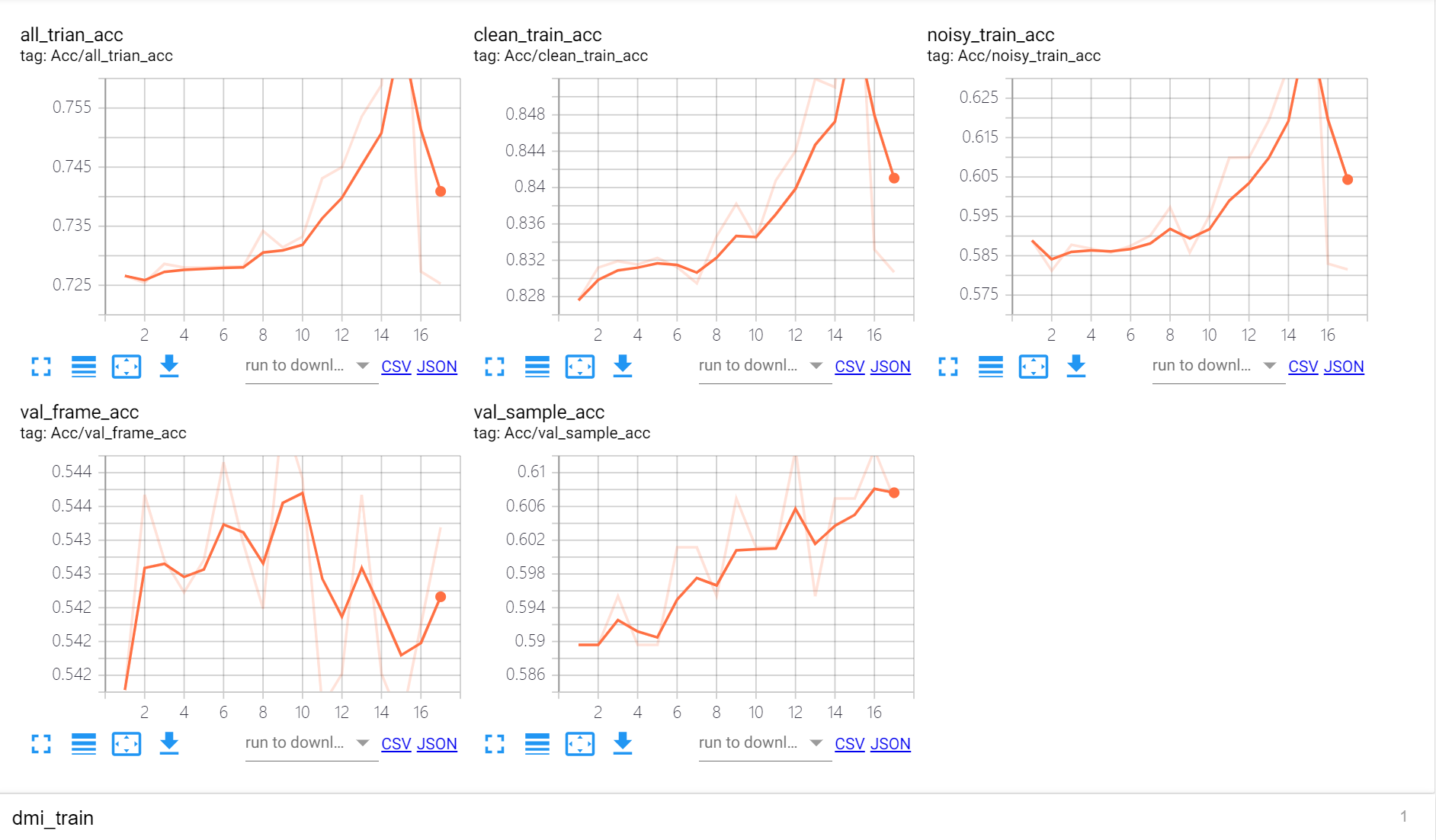
但是训练不是非常稳定,比如loss有所反弹:
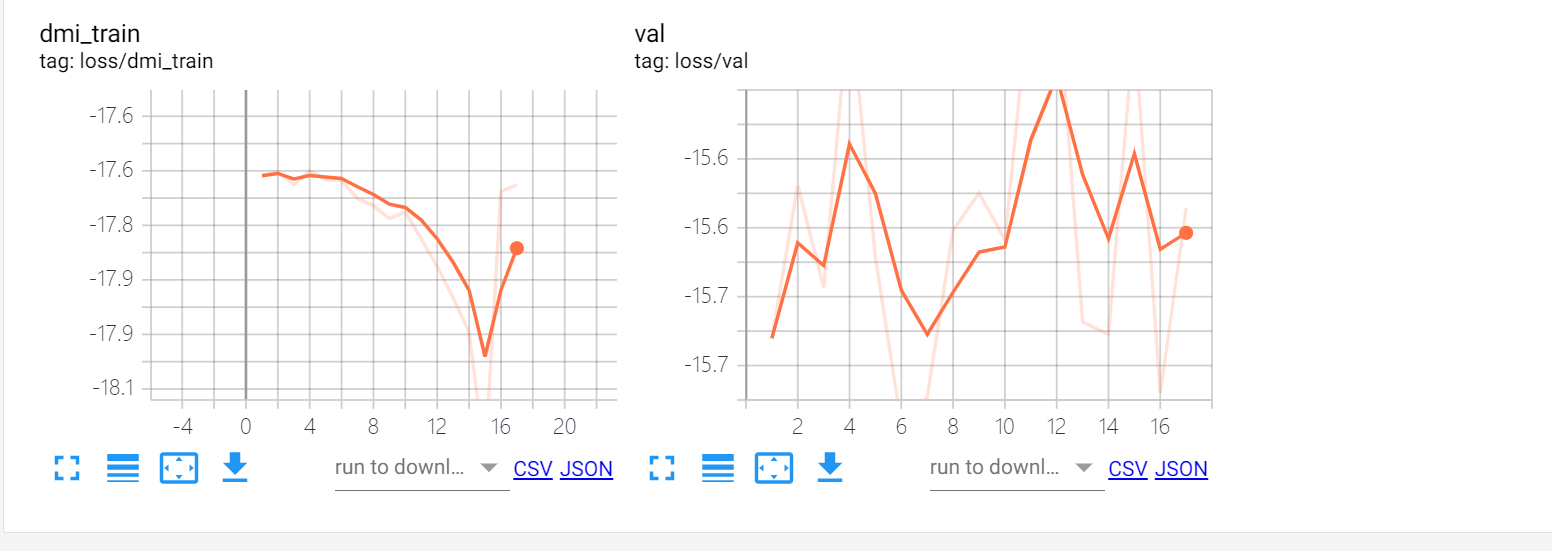
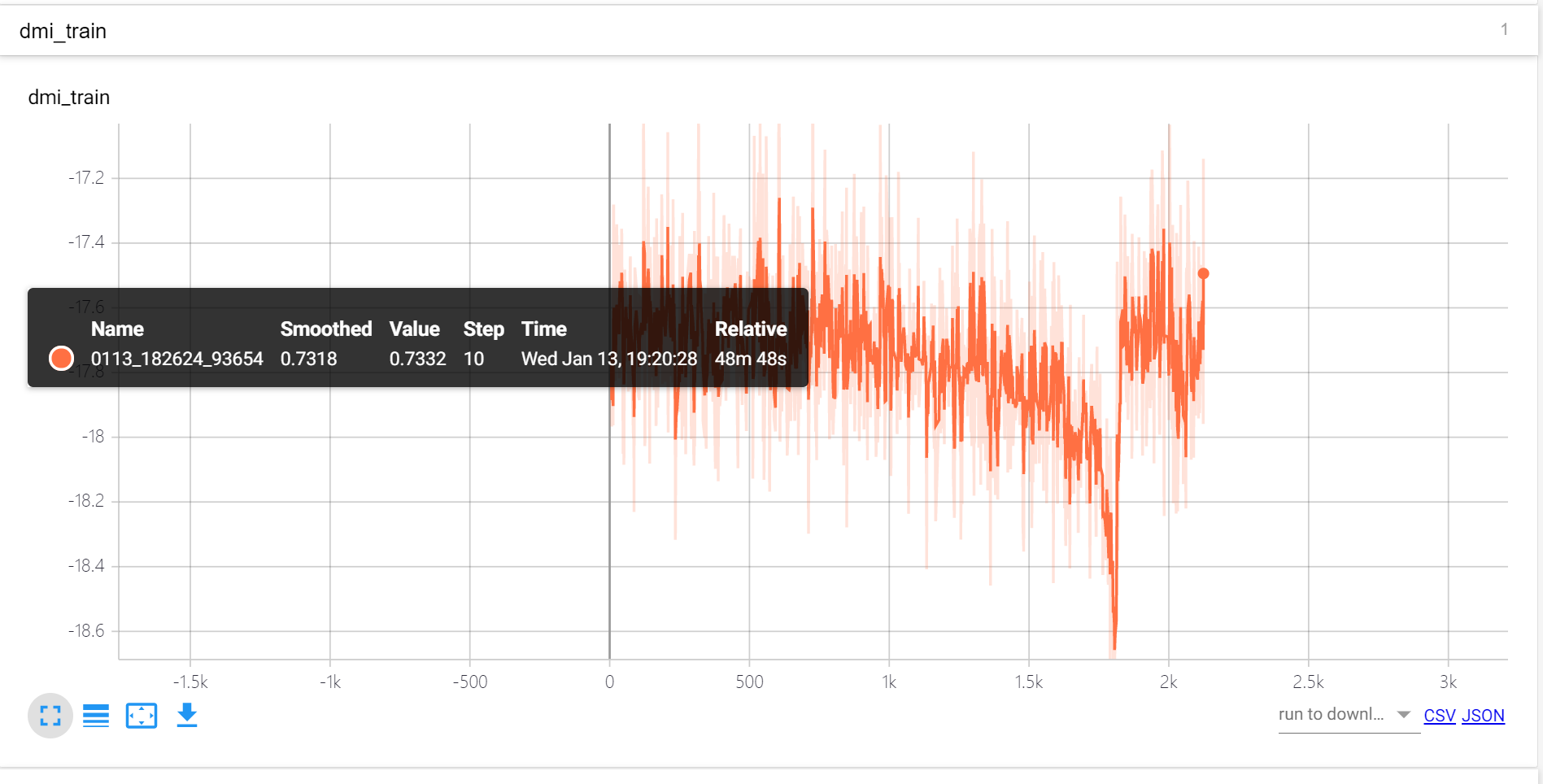
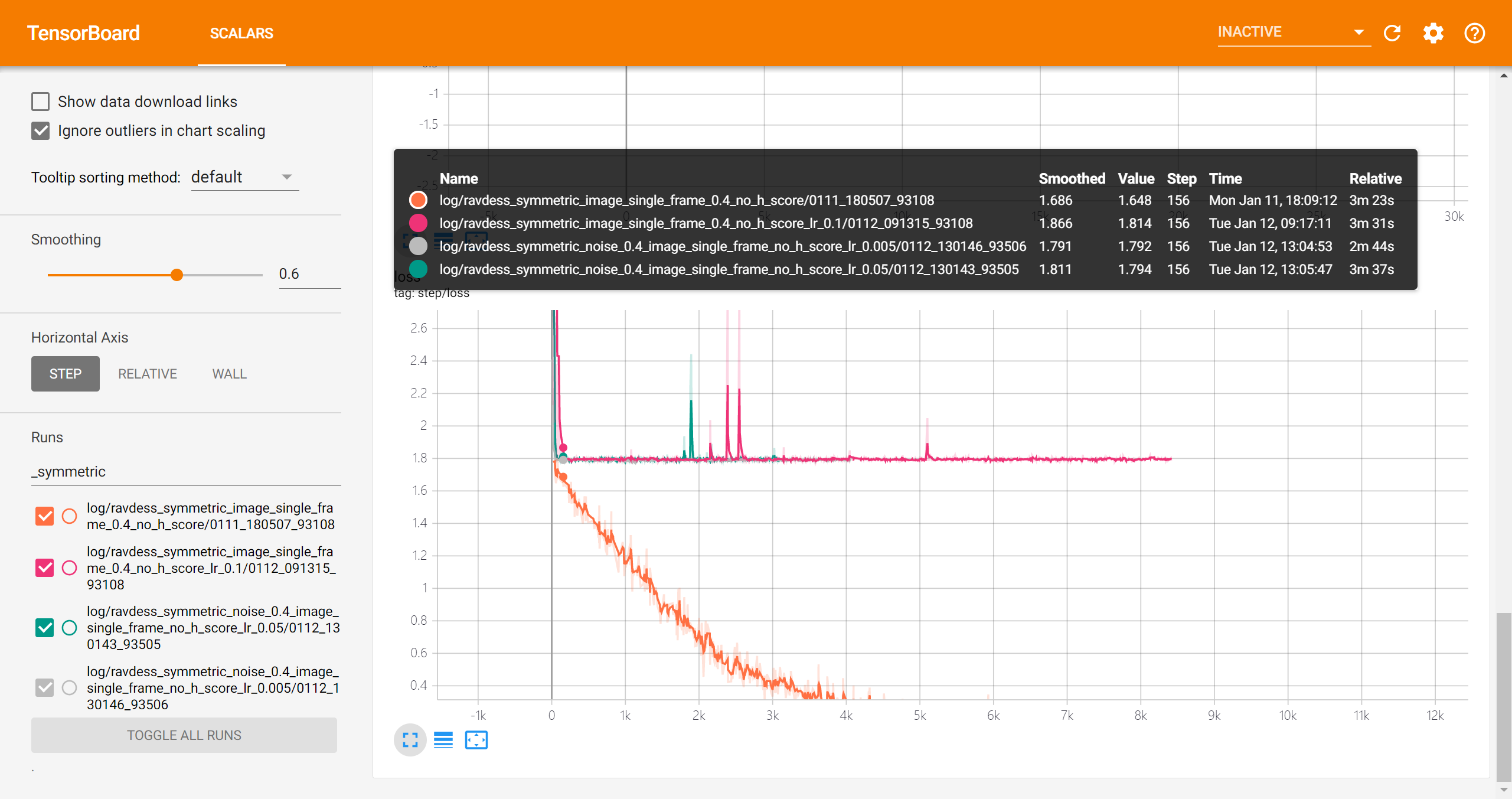
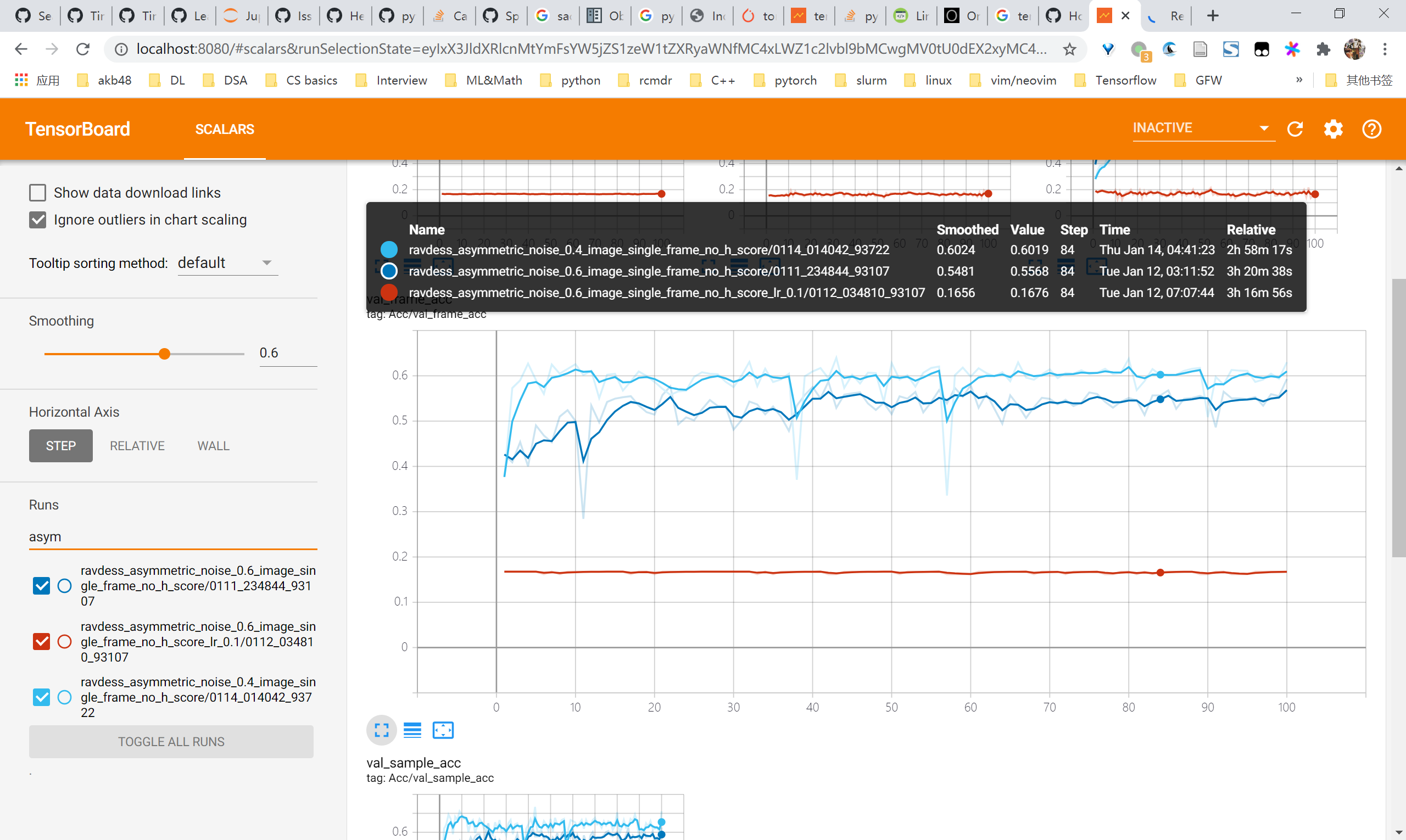
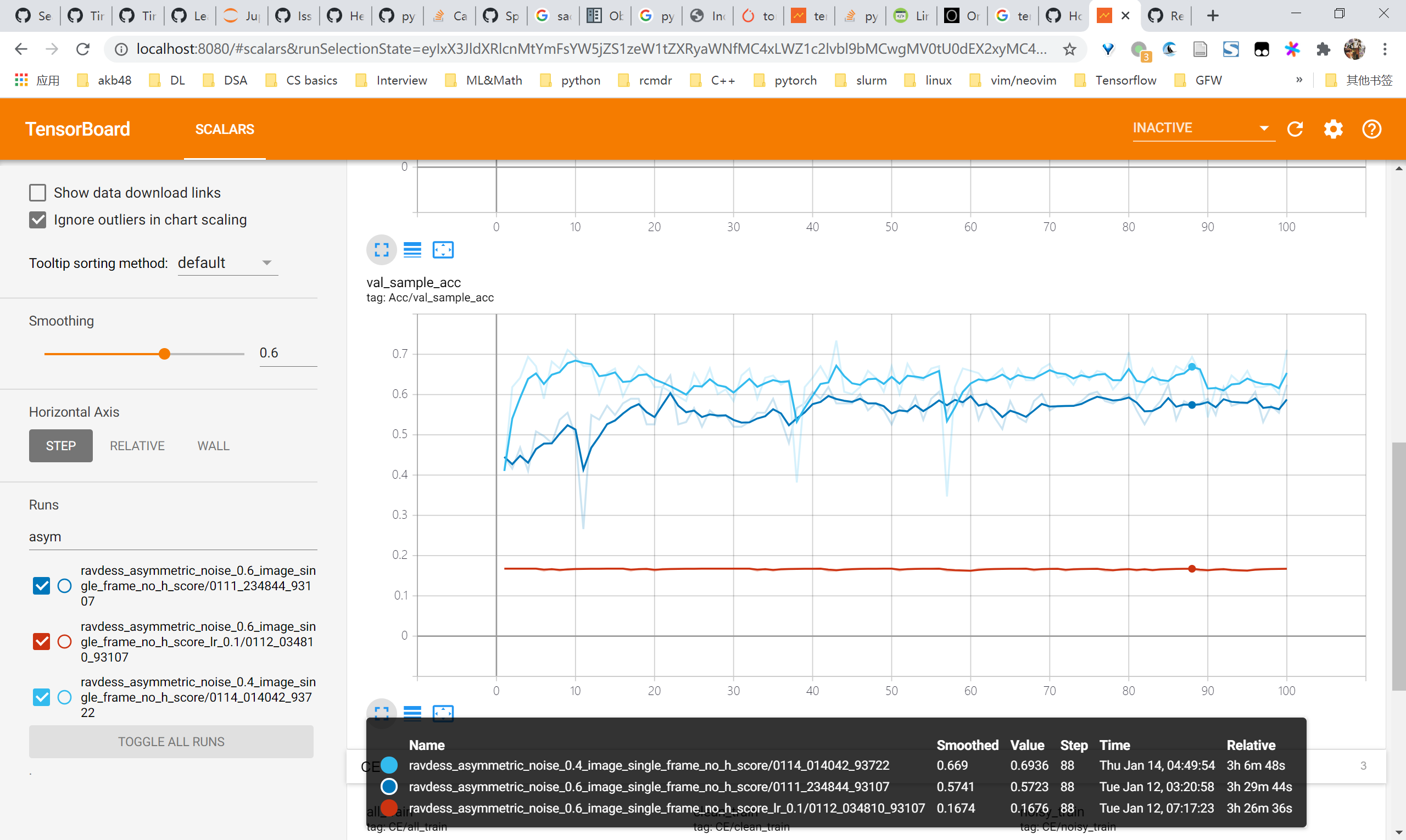
image single frame实验结果
symmetric
- val frame acc
- val sample acc
asymmetric
audio实验结果
- frame acc
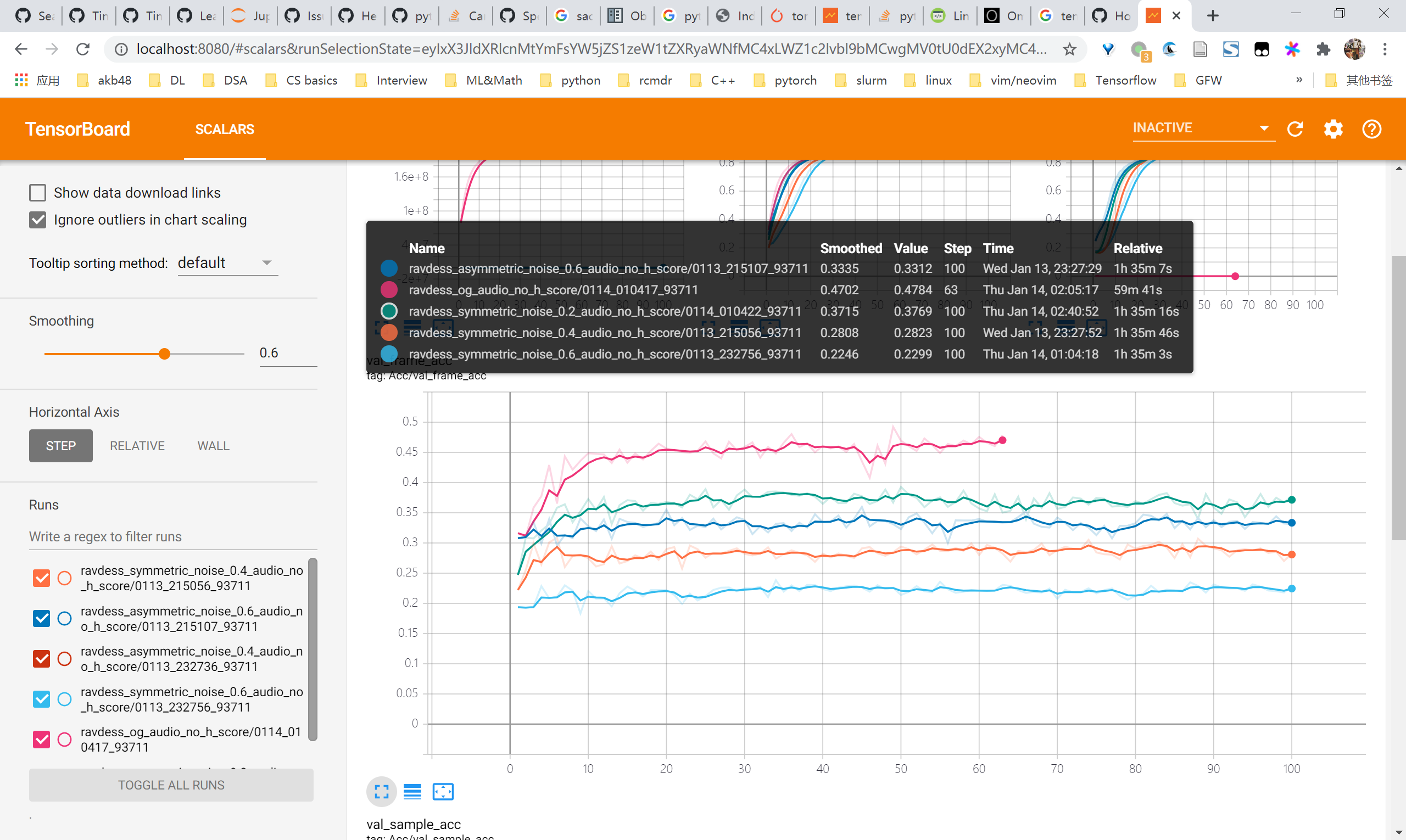
- val sample acc
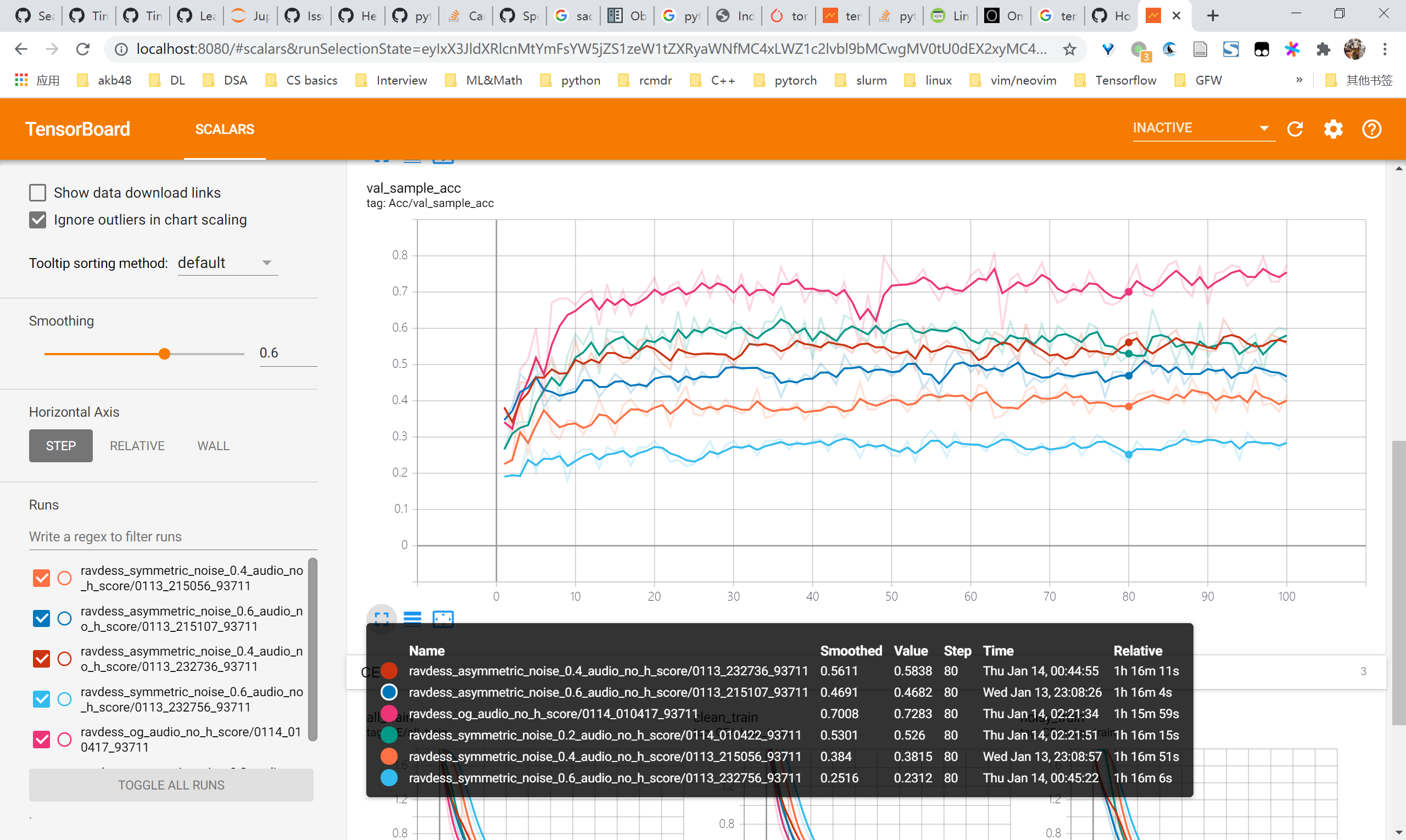
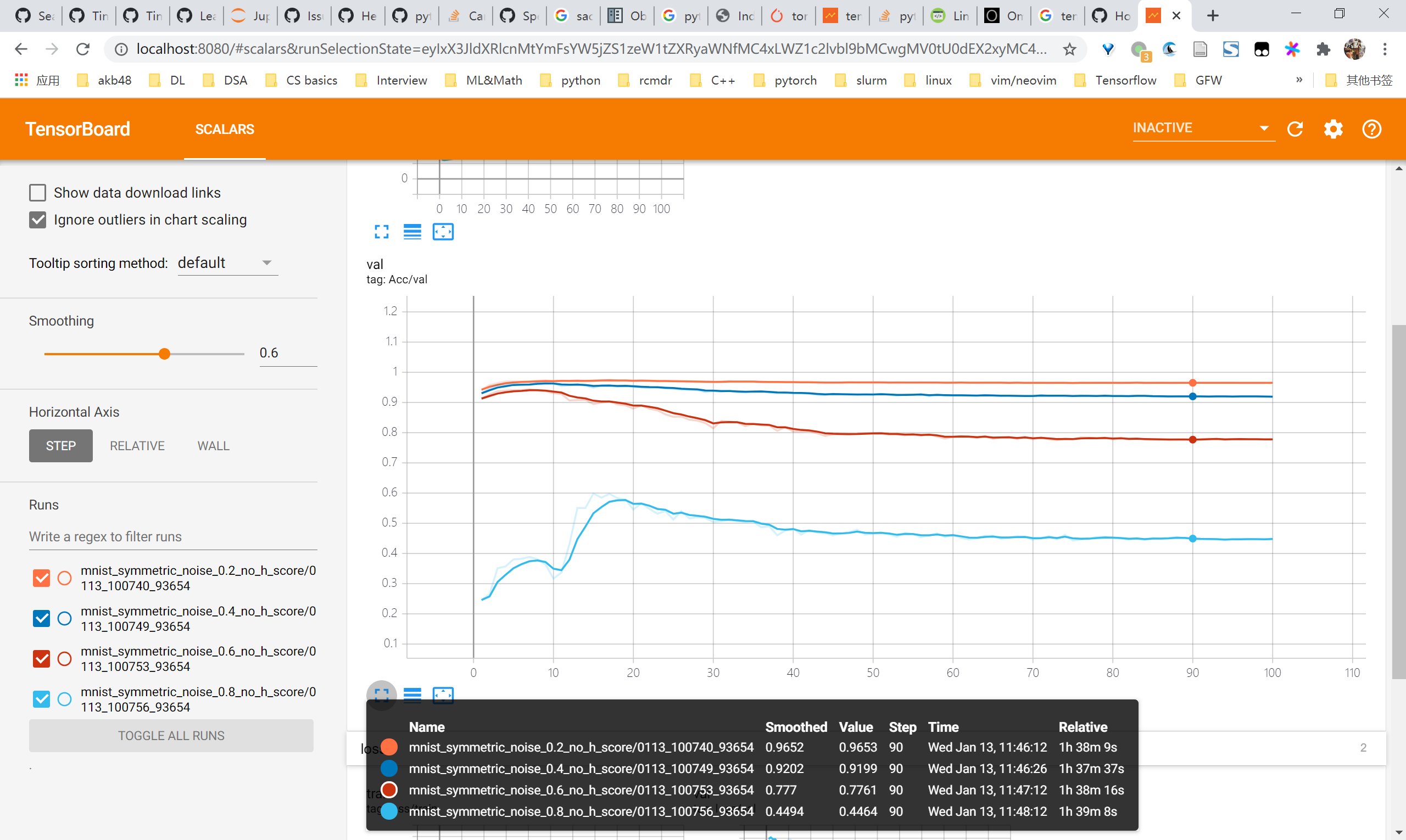
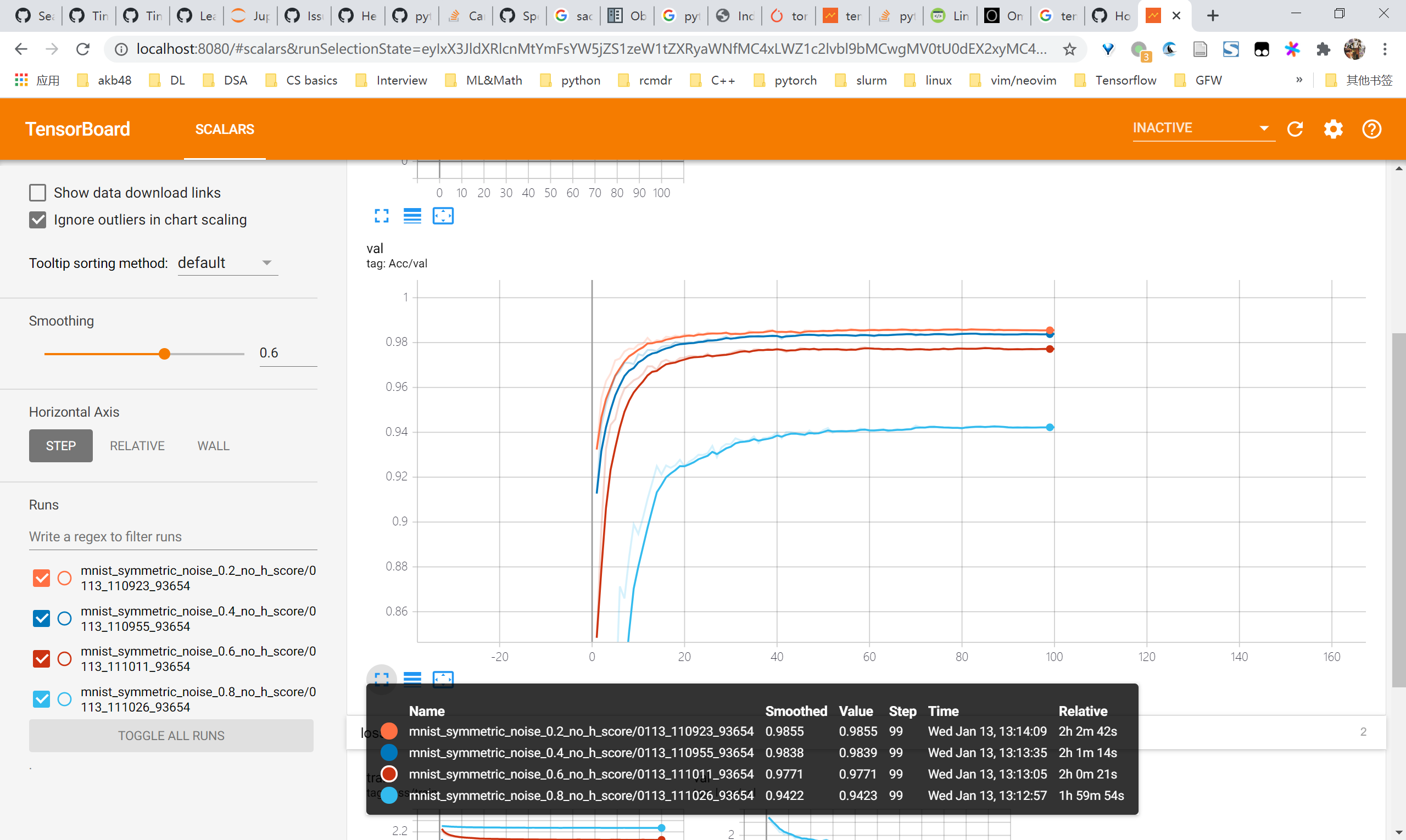
复现MINIST的learn clean patterns first的现象
一言蔽之:不是非常明显,很难像A closer look at … 中如此明显。MLP有所体现,CNN干脆就没有先上升后下降的趋势
2-layer MLP
- clean val
CNN
- clean val
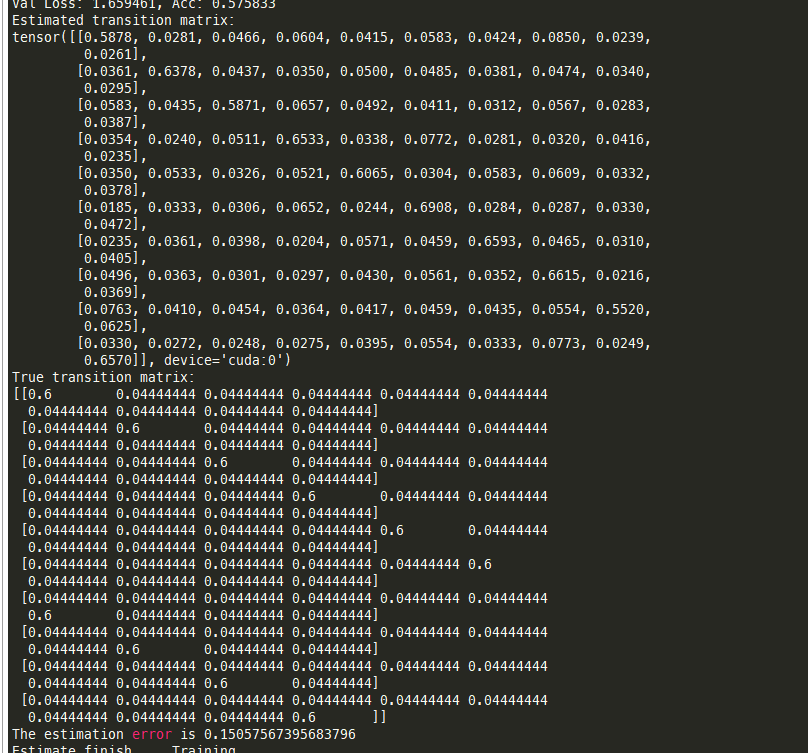
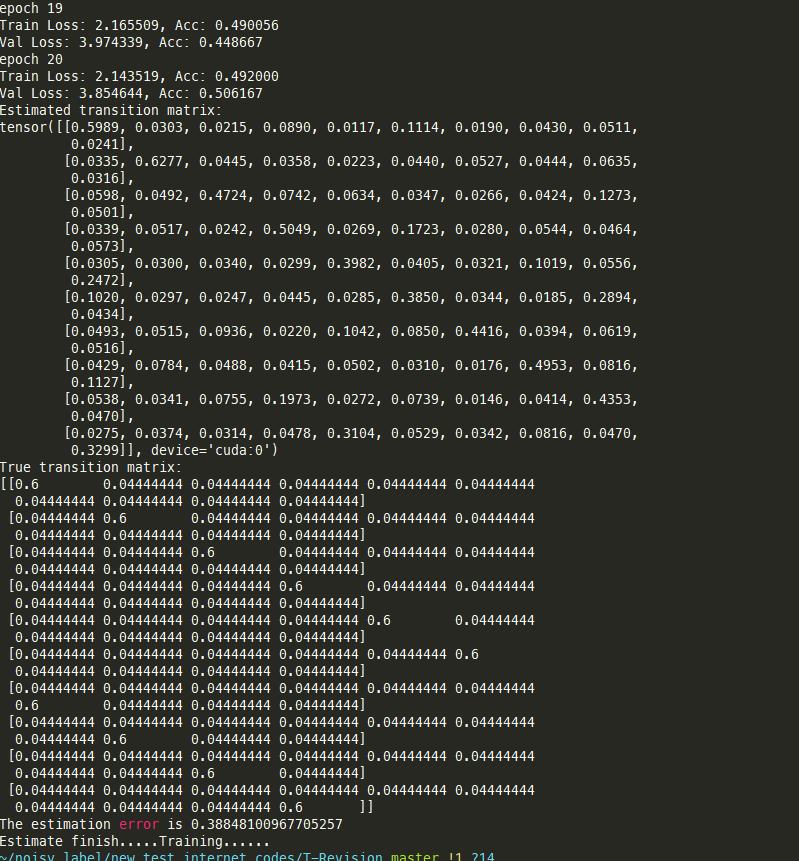
T Revision ravdess尝试
总体来看,是有效果的,特别是单一模态时,error更小。因此可以考虑先单模态pretrain,再基于pretrain的结果进行训练!
除此之外,可以看到epoch较小时的checkpoint对应的T更准确,因此一开始pretrain不用太久!!
symmetric总体估计得不如asymmetric准,可以推测noise rate越大越难估计(估计越不准)
实验设置:从epoch 5 ~ 30每5个epoch的ckpt载入,打印error最小的matrix以及对应的epoch checkpoint
image
- trial 1
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [01:53<00:00, 5.97s/it]
Found better revision t with err:0.392519 with ckpt:
/home/weitaotang/multimodal/results_temp/image_single_frame/models/ravdess_symmetric_noise_0.4_image_single_frame_no_h_score/0113_220659_93722/checkpoint-epoch5.pth
[[7.37014813e-01 5.49748095e-02 1.91551456e-02 1.06802471e-02
7.75371623e-03 1.70421249e-01]
[1.49264102e-02 7.05651750e-01 1.33411816e-01 2.91340008e-02
7.21719406e-02 4.47040626e-02]
[1.69836739e-01 5.79755422e-02 5.83608894e-01 3.76570563e-02
5.09809138e-02 9.99408390e-02]
[5.90787815e-03 6.60515847e-02 3.96423090e-04 7.94890272e-01
4.54765739e-03 1.28206202e-01]
[5.04207044e-02 3.06661356e-02 6.10200234e-02 3.16125759e-02
8.15995386e-01 1.02851814e-02]
[1.68665471e-02 2.29821654e-01 2.43432482e-03 6.61020219e-02
1.24099067e-02 6.72365573e-01]]
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [01:59<00:00, 6.30s/it]
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [01:55<00:00, 6.05s/it]
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [01:55<00:00, 6.06s/it]
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [01:54<00:00, 6.04s/it]
--------------------------------------------------------------------------------
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [01:55<00:00, 6.07s/it]
Found better revision t with err:0.077368 with ckpt:
/home/weitaotang/multimodal/results_temp/image_single_frame/models/ravdess_asymmetric_noise_0.4_image_single_frame_no_h_score/0114_014042_93722/checkpoint-epoch5.pth
[[9.99978390e-01 4.24855948e-08 4.22028800e-06 7.55608108e-09
1.72387464e-05 1.00746411e-07]
[5.97121342e-05 6.31816556e-01 7.50882308e-03 3.53185713e-01
6.74934108e-03 6.79860689e-04]
[1.92773897e-08 2.28556597e-05 5.49387958e-01 1.72671389e-05
4.50389371e-01 1.82462852e-04]
[3.87757505e-06 4.13954102e-01 5.28141591e-04 5.85183560e-01
2.97371327e-04 3.29412852e-05]
[1.75910082e-07 2.36618023e-04 2.86706670e-01 4.47445345e-05
7.12622216e-01 3.89617483e-04]
[1.74123657e-04 2.17408124e-03 8.70988746e-04 2.19455221e-03
1.13185740e-03 9.93454396e-01]]
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [01:58<00:00, 6.23s/it]
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [01:57<00:00, 6.19s/it]
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [02:01<00:00, 6.40s/it]
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [01:57<00:00, 6.17s/it]- trail 2
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [02:15<00:00, 7.14s/it]
Found better revision t with err:0.340032 with ckpt:
/home/weitaotang/multimodal/results_temp/image_single_frame/models/ravdess_symmetric_noise_0.4_image_single_frame_no_h_score/0113_220659_93722/checkpoint-epoch5.pth
[[0.74072658 0.01935282 0.07026559 0.00596408 0.01678354 0.14690741]
[0.03586634 0.71411037 0.12696856 0.01515382 0.02747697 0.08042397]
[0.06790715 0.15041716 0.58079056 0.05768638 0.02814293 0.1150558 ]
[0.04842931 0.04216269 0.00557405 0.80087784 0.0454859 0.05747022]
[0.02076734 0.08967834 0.03257319 0.02381871 0.80996074 0.02320168]
[0.05548994 0.07312605 0.01950351 0.04691109 0.12951871 0.6754507 ]]
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [02:09<00:00, 6.82s/it]
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [02:09<00:00, 6.83s/it]
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [02:14<00:00, 7.06s/it]
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [02:11<00:00, 6.93s/it]
--------------------------------------------------------------------------------
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [02:12<00:00, 6.98s/it]
Found better revision t with err:0.071826 with ckpt:
/home/weitaotang/multimodal/results_temp/image_single_frame/models/ravdess_asymmetric_noise_0.4_image_single_frame_no_h_score/0114_014042_93722/checkpoint-epoch5.pth
[[9.99978176e-01 8.94074767e-08 3.23012549e-07 1.69097617e-07
3.21461266e-07 2.09213347e-05]
[2.55739884e-08 6.30913114e-01 1.07774438e-04 3.68945120e-01
3.26208051e-05 1.32215717e-06]
[5.65324598e-06 7.42724068e-03 5.52161788e-01 4.20391930e-03
4.35413689e-01 7.87712614e-04]
[4.74741598e-06 4.17344832e-01 2.14540049e-04 5.82112667e-01
9.40623789e-05 2.29176453e-04]
[5.60341346e-08 3.45309488e-04 2.88416076e-01 1.09513552e-04
7.11108615e-01 2.04272590e-05]
[1.81705001e-03 2.85893997e-03 2.13714621e-04 1.92421779e-03
2.76464435e-04 9.92909613e-01]]
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [02:10<00:00, 6.88s/it]
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [02:16<00:00, 7.17s/it]
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [02:19<00:00, 7.32s/it]
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [02:16<00:00, 7.20s/it]audio
- trail 1
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [00:18<00:00, 1.04it/s]
Found better revision t with err:0.415975 with ckpt:
/home/weitaotang/multimodal/results_temp/audio/models/ravdess_symmetric_noise_0.4_audio_no_h_score/0113_215056_93711/checkpoint-epoch5.pth
[[0.25389571 0.09228479 0.20698934 0.27409103 0.09113397 0.08160515]
[0.08750636 0.51496097 0.0436491 0.10722706 0.17794909 0.06870737]
[0.15156065 0.07283055 0.35790298 0.07674008 0.29612027 0.04484543]
[0.24321621 0.06782876 0.12313364 0.49200456 0.04399101 0.02982585]
[0.06249942 0.11504411 0.2359151 0.01695025 0.52651856 0.04307259]
[0.13342992 0.10467964 0.05116186 0.06034019 0.08603964 0.56434879]]
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [00:13<00:00, 1.38it/s]
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [00:13<00:00, 1.40it/s]
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [00:17<00:00, 1.09it/s]
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [00:14<00:00, 1.31it/s]
--------------------------------------------------------------------------------
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [00:13<00:00, 1.40it/s]
Found better revision t with err:0.128727 with ckpt:
/home/weitaotang/multimodal/results_temp/audio/models/ravdess_asymmetric_noise_0.4_audio_no_h_score/0113_232736_93711/checkpoint-epoch5.pth
[[9.94958350e-01 1.78187583e-03 3.13801594e-04 1.89794601e-03
9.41193957e-04 1.06832134e-04]
[7.20291405e-03 5.80317192e-01 8.54483371e-04 4.06137146e-01
5.16415342e-03 3.24093753e-04]
[9.26777205e-04 2.19786319e-04 4.24290703e-01 1.18924458e-04
5.74408175e-01 3.56532273e-05]
[9.01317605e-02 3.95732577e-01 2.24156240e-06 5.10228427e-01
5.46904859e-06 3.89954887e-03]
[3.46361430e-04 3.27936719e-04 3.12342425e-01 3.77159894e-04
6.86280551e-01 3.25555057e-04]
[1.31755906e-03 4.51953487e-05 8.15807118e-04 6.51472547e-05
1.80661353e-03 9.95949677e-01]]
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [00:17<00:00, 1.09it/s]
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [00:15<00:00, 1.19it/s]
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [00:15<00:00, 1.23it/s]
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [00:16<00:00, 1.17it/s]- trail 2
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [00:16<00:00, 1.17it/s]
Found better revision t with err:0.478438 with ckpt:
/home/weitaotang/multimodal/results_temp/audio/models/ravdess_symmetric_noise_0.4_audio_no_h_score/0113_215056_93711/checkpoint-epoch5.pth
[[0.25386552 0.02816301 0.09211877 0.6069223 0.01289129 0.00603905]
[0.08574092 0.52417734 0.04768458 0.10971049 0.15698343 0.07570327]
[0.21533155 0.06798532 0.35652673 0.10144213 0.12699098 0.1317233 ]
[0.15600043 0.18612409 0.03740445 0.48830468 0.06292662 0.06923976]
[0.06397119 0.06777771 0.29985431 0.00756286 0.52437398 0.03645993]
[0.16910183 0.04342578 0.11727054 0.06100427 0.03611601 0.57308157]]
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [00:14<00:00, 1.28it/s]
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [00:14<00:00, 1.32it/s]
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [00:14<00:00, 1.28it/s]
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [00:16<00:00, 1.17it/s]
--------------------------------------------------------------------------------
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [00:14<00:00, 1.29it/s]
Found better revision t with err:0.132613 with ckpt:
/home/weitaotang/multimodal/results_temp/audio/models/ravdess_asymmetric_noise_0.4_audio_no_h_score/0113_232736_93711/checkpoint-epoch5.pth
[[9.95695854e-01 6.25396754e-07 4.48640111e-04 7.03666878e-07
6.73638844e-04 3.18053830e-03]
[2.93859078e-03 5.79728069e-01 2.81209447e-05 4.16929769e-01
2.67289118e-04 1.08146436e-04]
[2.07288345e-02 1.81161874e-02 4.22044809e-01 1.34290555e-02
5.08058915e-01 1.76222138e-02]
[1.08152351e-02 4.81431427e-01 2.01069297e-04 5.06482765e-01
9.92116654e-04 7.74050277e-05]
[9.88331764e-05 9.43107348e-03 3.02070525e-01 3.79505090e-03
6.84582485e-01 2.20230922e-05]
[2.28925497e-03 4.81048368e-04 1.09156753e-04 7.81982182e-04
1.99329388e-04 9.96139228e-01]]
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [00:14<00:00, 1.30it/s]
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [00:14<00:00, 1.30it/s]
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [00:16<00:00, 1.17it/s]
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [00:15<00:00, 1.25it/s]fusion
- trail 1
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [02:27<00:00, 7.78s/it]
Found better revision t with err:0.245888 with ckpt:
/home/weitaotang/multimodal/results_temp/fusion_no_h_score/models/ravdess_symmetric_noise_0.4_fusion_no_h_score/0111_034422_93107/checkpoint-epoch5.pth
[[0.69146853 0.04797358 0.07543566 0.0422144 0.0418038 0.10110403]
[0.06336676 0.67239938 0.04360678 0.06516055 0.06039333 0.09507321]
[0.02475316 0.22107349 0.59225173 0.08914785 0.03218814 0.04058563]
[0.11797382 0.08672993 0.0874175 0.56456794 0.11069051 0.03262029]
[0.08571974 0.04161564 0.08419766 0.04760431 0.70514424 0.03571841]
[0.19450805 0.11750432 0.02888204 0.01387309 0.0077209 0.63751161]]
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [02:09<00:00, 6.80s/it]
noisy_train dataset with 24180 samples
42%|███████████████████████████████████████████████████████████████████████▏ | 8/19 [01:01<00:32, 2.97s/it]
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [02:08<00:00, 6.75s/it]
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [02:09<00:00, 6.80s/it]
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [02:04<00:00, 6.55s/it]
--------------------------------------------------------------------------------
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [02:06<00:00, 6.65s/it]
Found better revision t with err:0.118717 with ckpt:
/home/weitaotang/multimodal/results_temp/fusion_no_h_score/models/ravdess_asymmetric_noise_0.4_fusion_no_h_score/0111_060526_93108/checkpoint-epoch5.pth
[[9.99985077e-01 3.33303029e-09 1.19833905e-05 9.64756076e-11
1.57460504e-06 1.36118361e-06]
[9.70278939e-03 4.84771640e-01 4.20865655e-03 4.39756108e-01
3.93429270e-03 5.76265214e-02]
[5.33318368e-03 1.10967220e-03 6.32902630e-01 4.49600731e-04
3.57397716e-01 2.80720290e-03]
[7.46599467e-07 2.64882552e-01 4.20716284e-05 7.35061120e-01
6.29869710e-06 7.20326376e-06]
[4.85154986e-05 1.44868214e-03 3.41783826e-01 4.48218386e-04
6.56216939e-01 5.38136212e-05]
[1.01609887e-03 1.56412889e-03 1.38539968e-04 2.01553172e-03
2.38128770e-04 9.95027572e-01]]
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [02:12<00:00, 6.98s/it]
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [02:15<00:00, 7.12s/it]
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [02:14<00:00, 7.08s/it]
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [02:11<00:00, 6.93s/it]- trail 2
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [02:41<00:00, 8.47s/it]
Found better revision t with err:0.269013 with ckpt:
/home/weitaotang/multimodal/results_temp/fusion_no_h_score/models/ravdess_symmetric_noise_0.4_fusion_no_h_score/0111_034422_93107/checkpoint-epoch5.pth
[[0.69253284 0.01924669 0.16257553 0.08773406 0.01293883 0.02497208]
[0.04376511 0.67207418 0.10325625 0.03216256 0.07928783 0.06945408]
[0.07502832 0.09878149 0.58612365 0.20223092 0.02060406 0.01723154]
[0.11923723 0.04975081 0.12028455 0.56648084 0.03154257 0.11270397]
[0.07270622 0.03229545 0.12604801 0.05031482 0.70455036 0.01408514]
[0.10690363 0.08137329 0.1370423 0.01977044 0.01520107 0.63970925]]
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [02:31<00:00, 7.99s/it]
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [02:38<00:00, 8.36s/it]
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [02:44<00:00, 8.68s/it]
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [02:05<00:00, 6.59s/it]
--------------------------------------------------------------------------------
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [02:06<00:00, 6.68s/it]
Found better revision t with err:0.121845 with ckpt:
/home/weitaotang/multimodal/results_temp/fusion_no_h_score/models/ravdess_asymmetric_noise_0.4_fusion_no_h_score/0111_060526_93108/checkpoint-epoch5.pth
[[9.99986581e-01 6.27810544e-08 1.22991693e-05 1.14747236e-08
9.95566532e-07 5.01988354e-08]
[6.52518578e-07 4.85241528e-01 4.11671817e-05 5.14657624e-01
3.47765738e-05 2.42646967e-05]
[2.75373673e-04 3.39331788e-07 6.35205075e-01 1.25685331e-08
3.64508174e-01 1.10258772e-05]
[1.24452450e-06 2.44520915e-01 1.56135444e-02 7.34597455e-01
5.13995242e-03 1.26881283e-04]
[2.60336132e-04 7.43004952e-04 3.45211557e-01 1.79845275e-04
6.53511809e-01 9.34460413e-05]
[4.71479600e-03 9.33652473e-05 5.41087780e-05 6.36025079e-05
7.86016301e-05 9.94995526e-01]]
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [02:05<00:00, 6.61s/it]
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [02:08<00:00, 6.76s/it]
noisy_train dataset with 24180 samples
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [02:06<00:00, 6.66s/it]
noisy_train dataset with 24180 samples
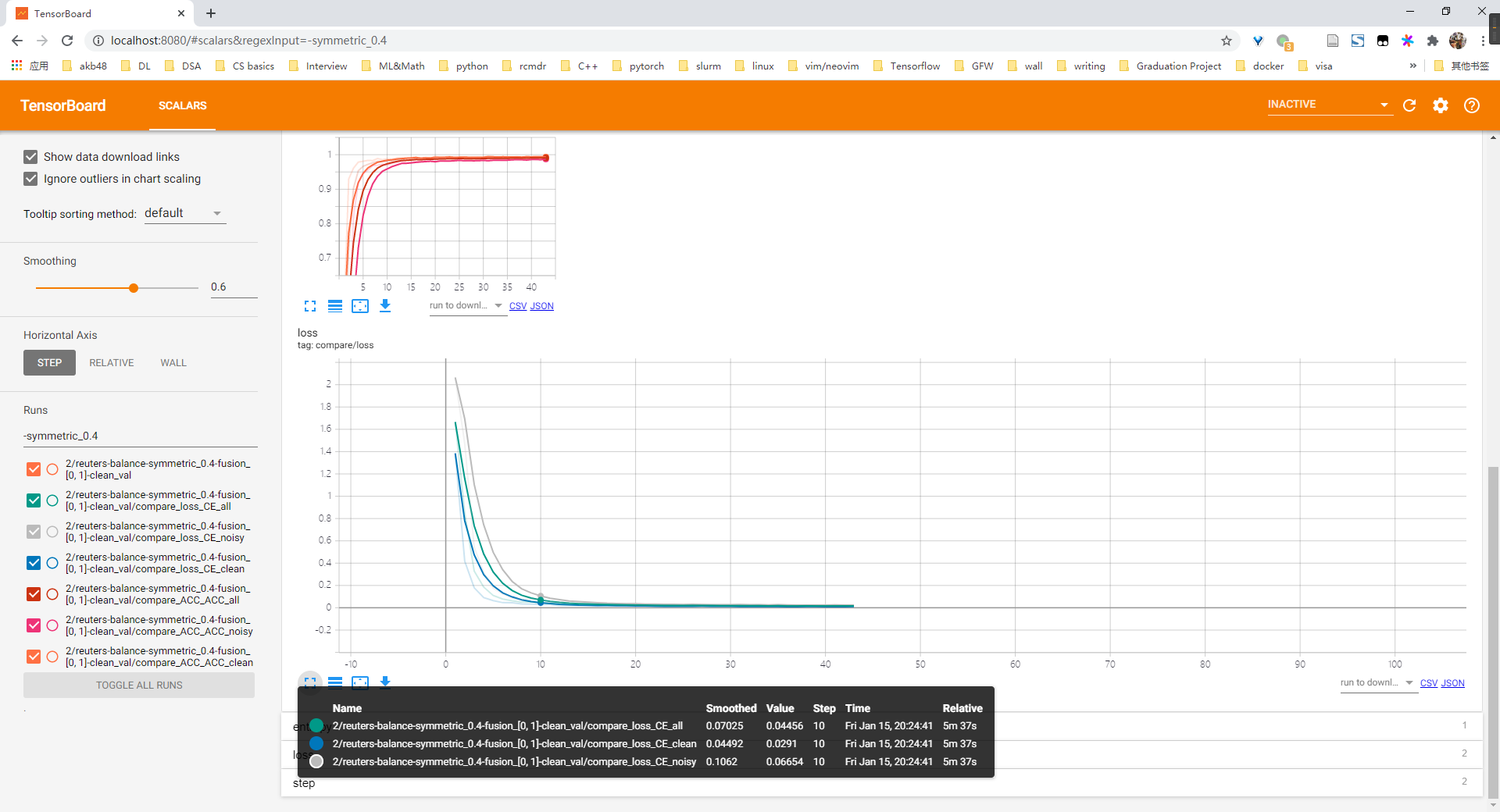
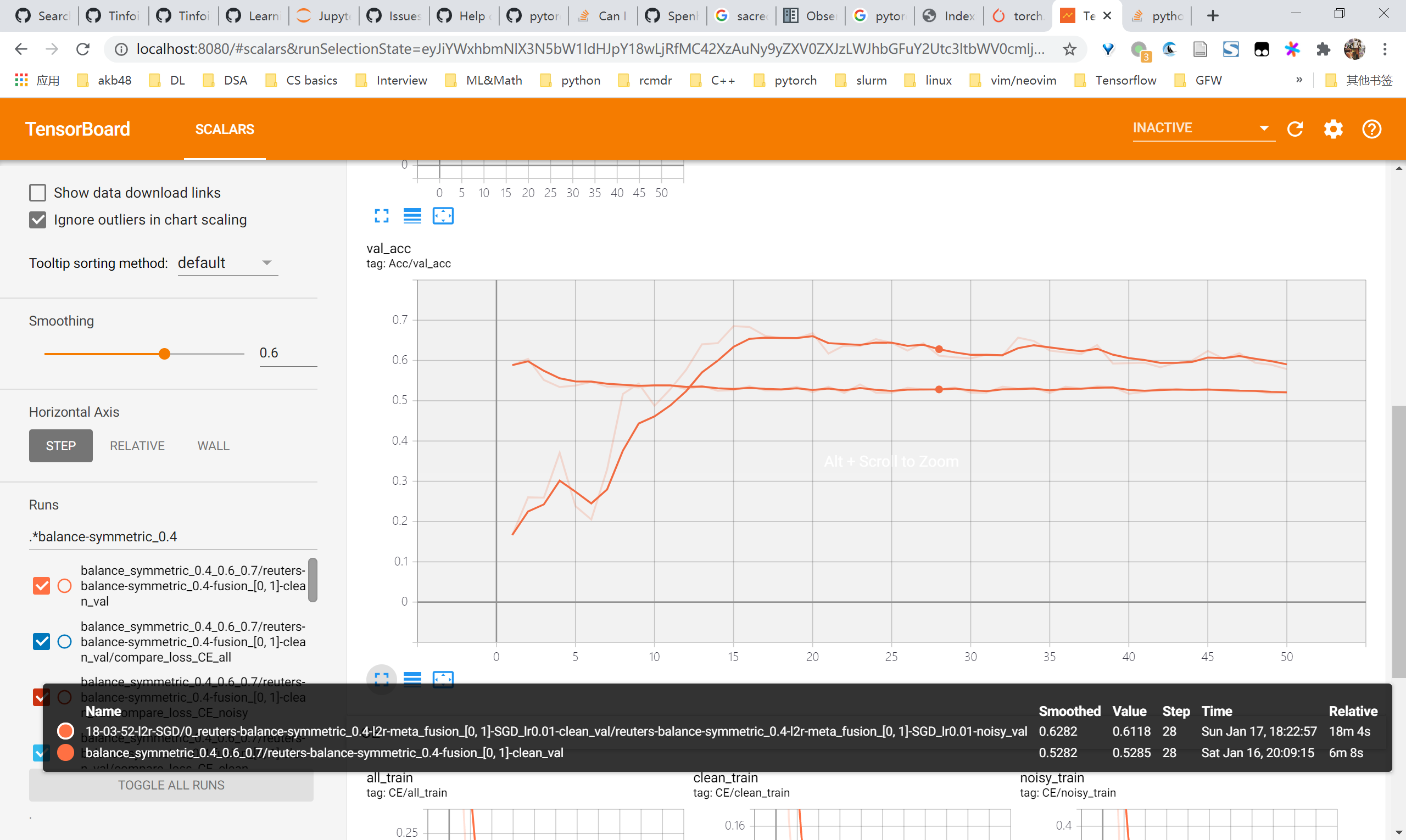
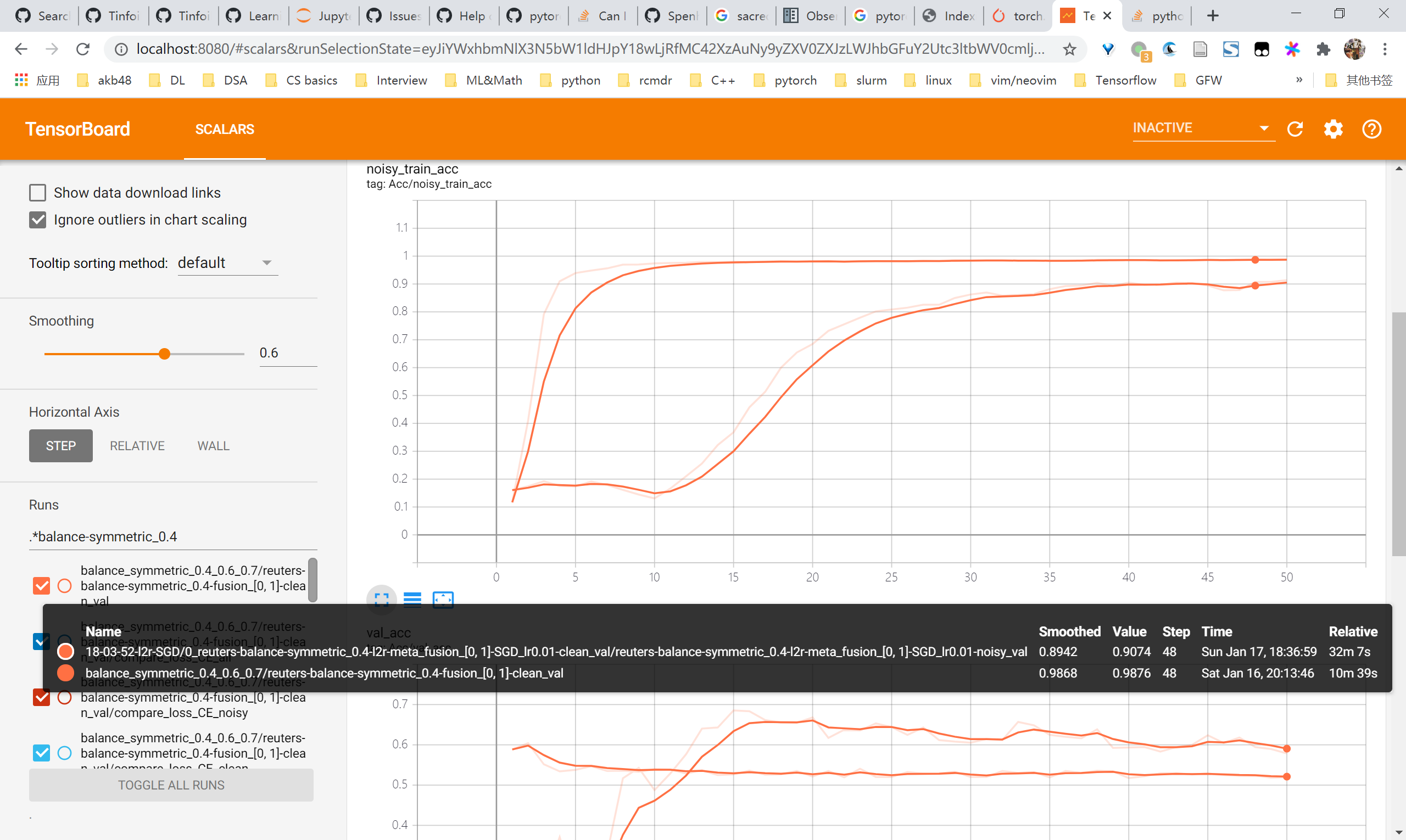
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [02:05<00:00, 6.58s/it]reuters 验证learn clean patterns first
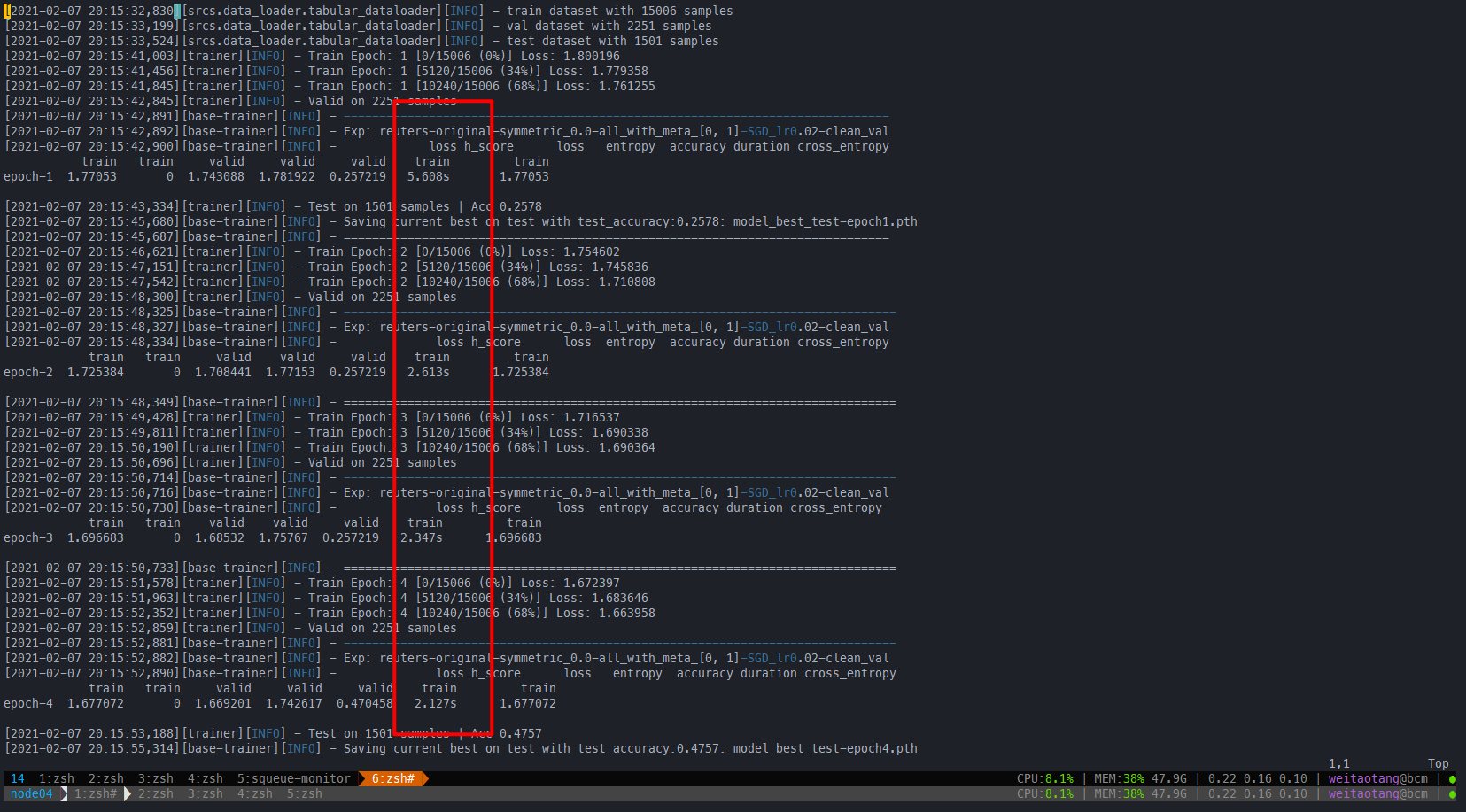
- 总体上来说是有learn clean pattern first的现象的,因为可以看到在前5~10个epochs内,clean acc始终比nosiy acc高,且clean ce loss 始终比 nosiy ce loss 高
- 因此可以考虑dividemix那一类方法
0模态
01模态
- loss
- accuracy
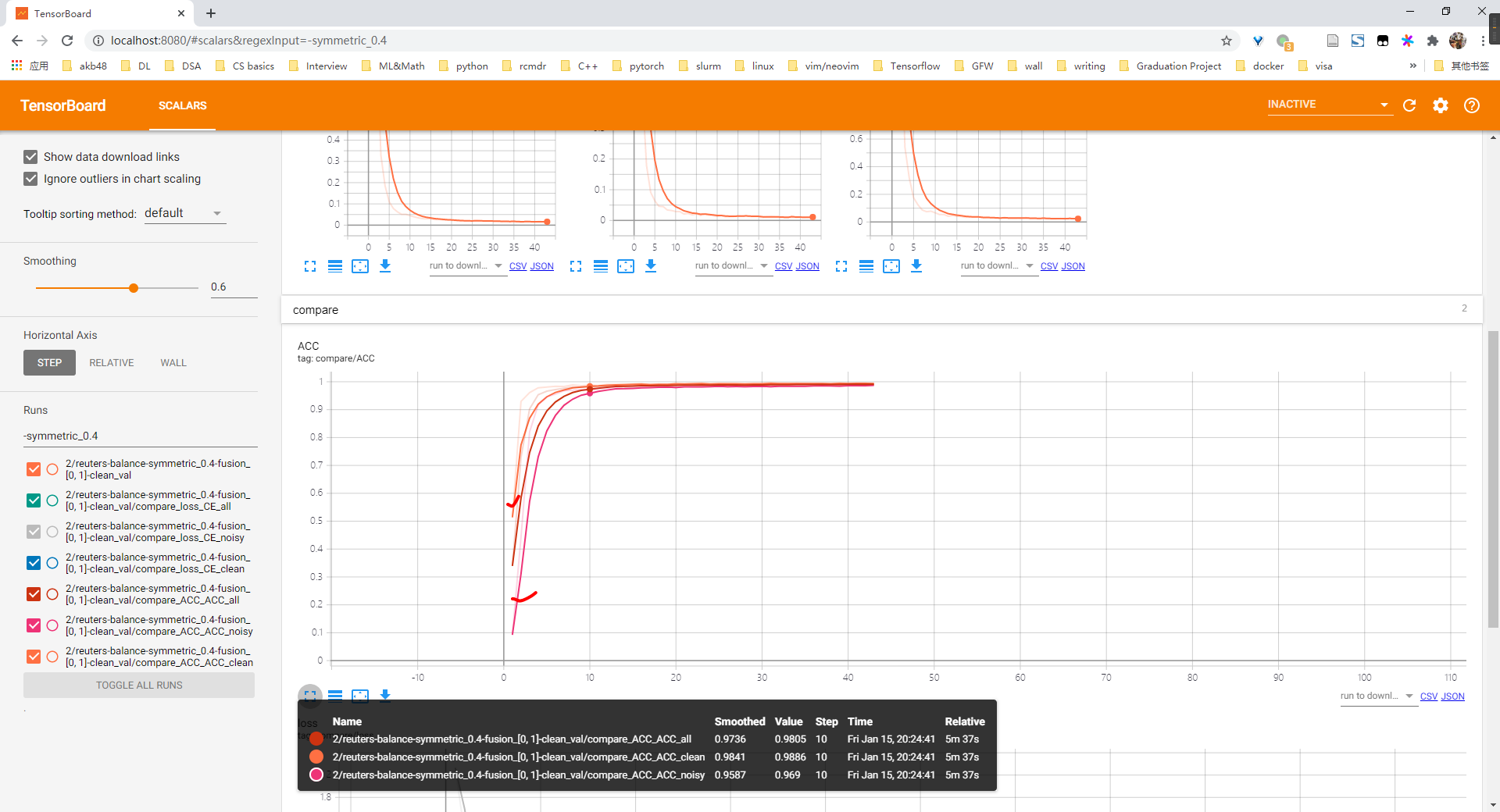
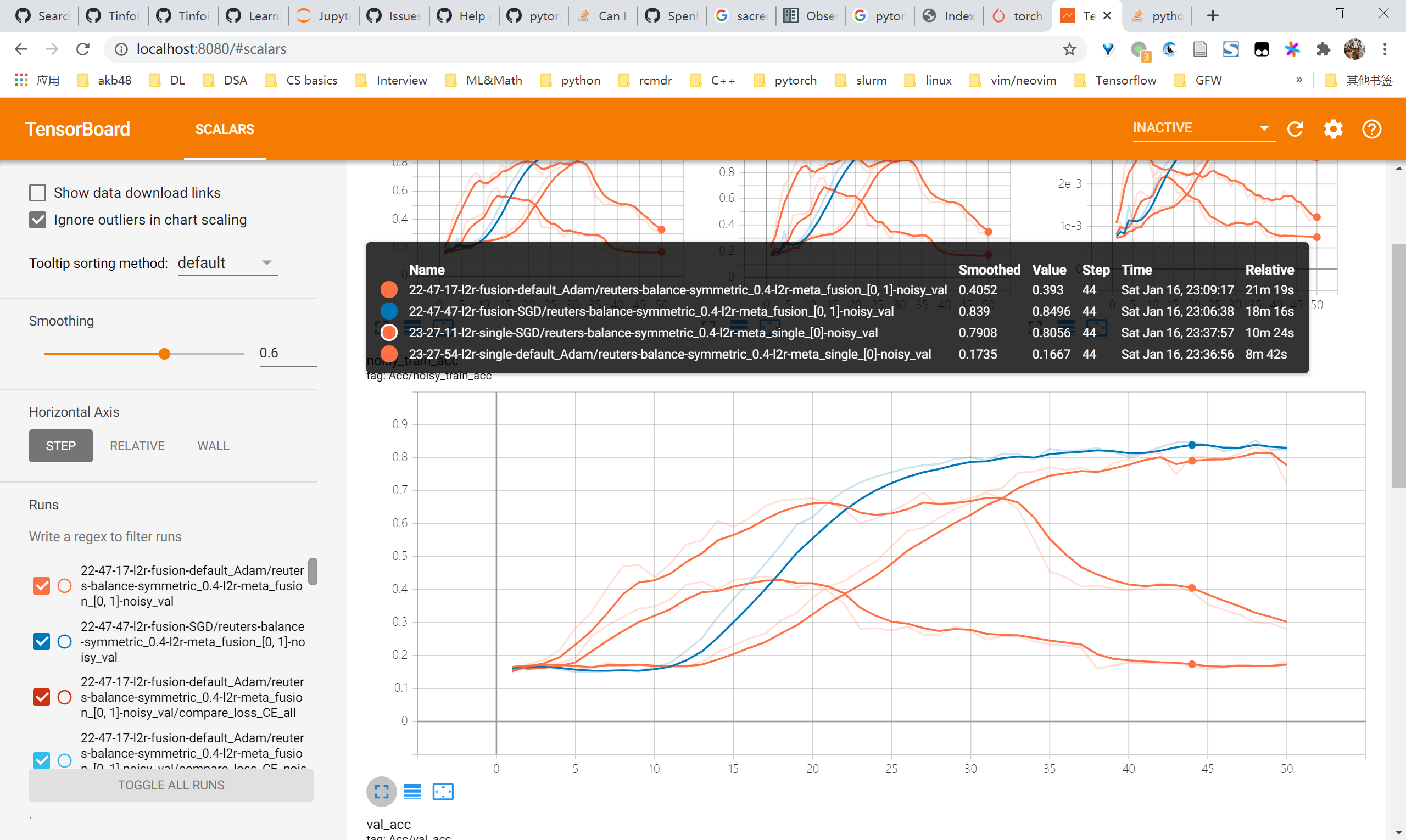
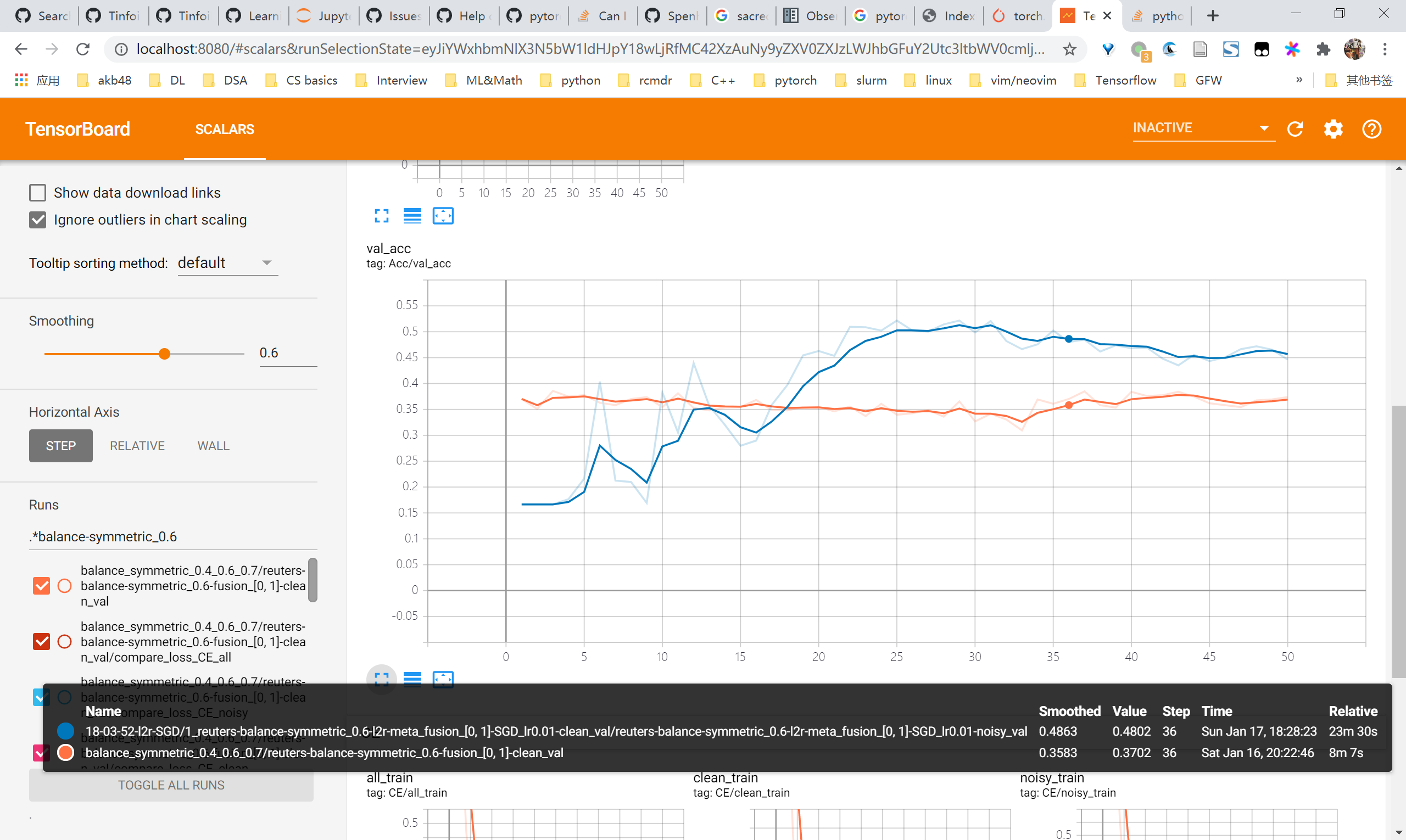
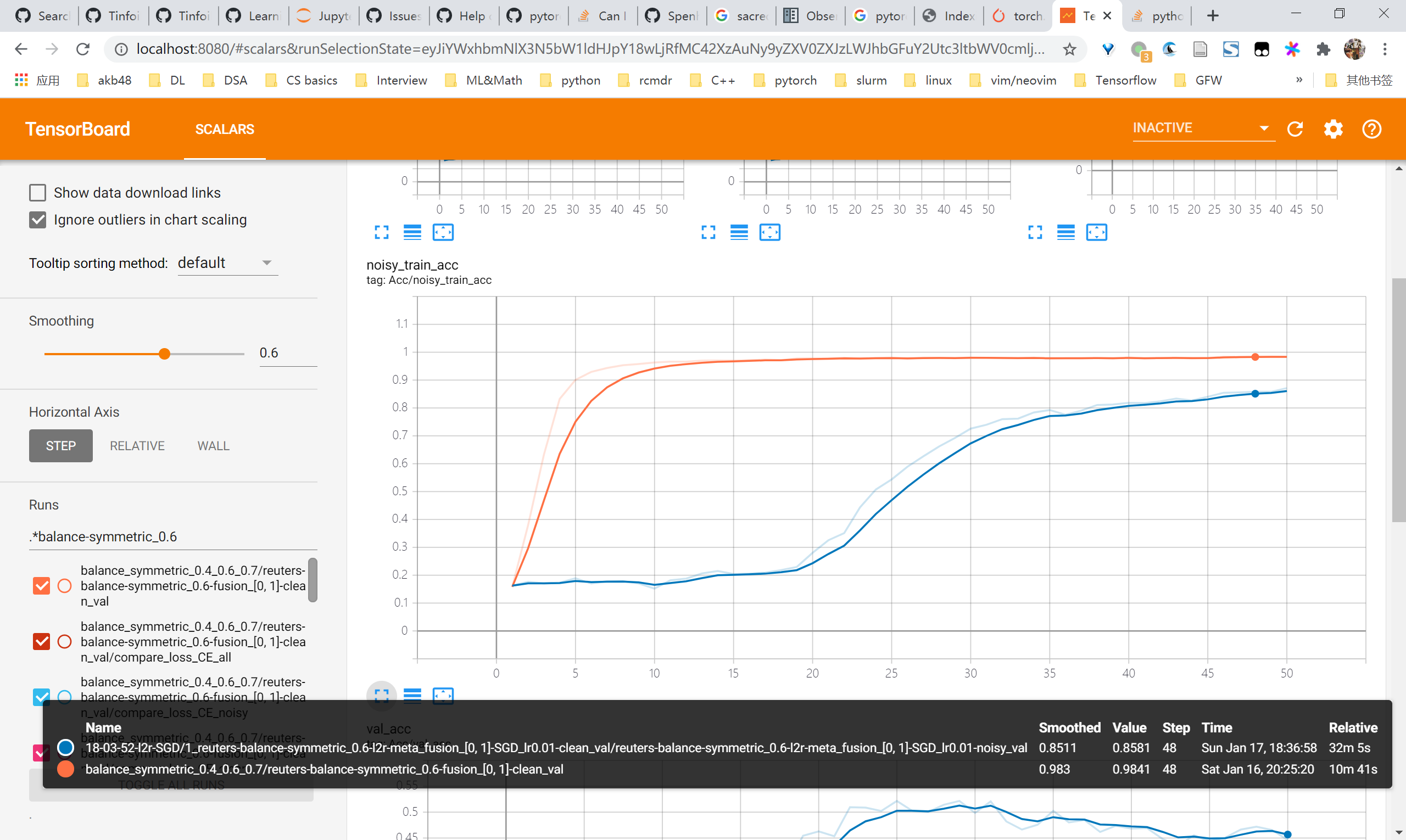
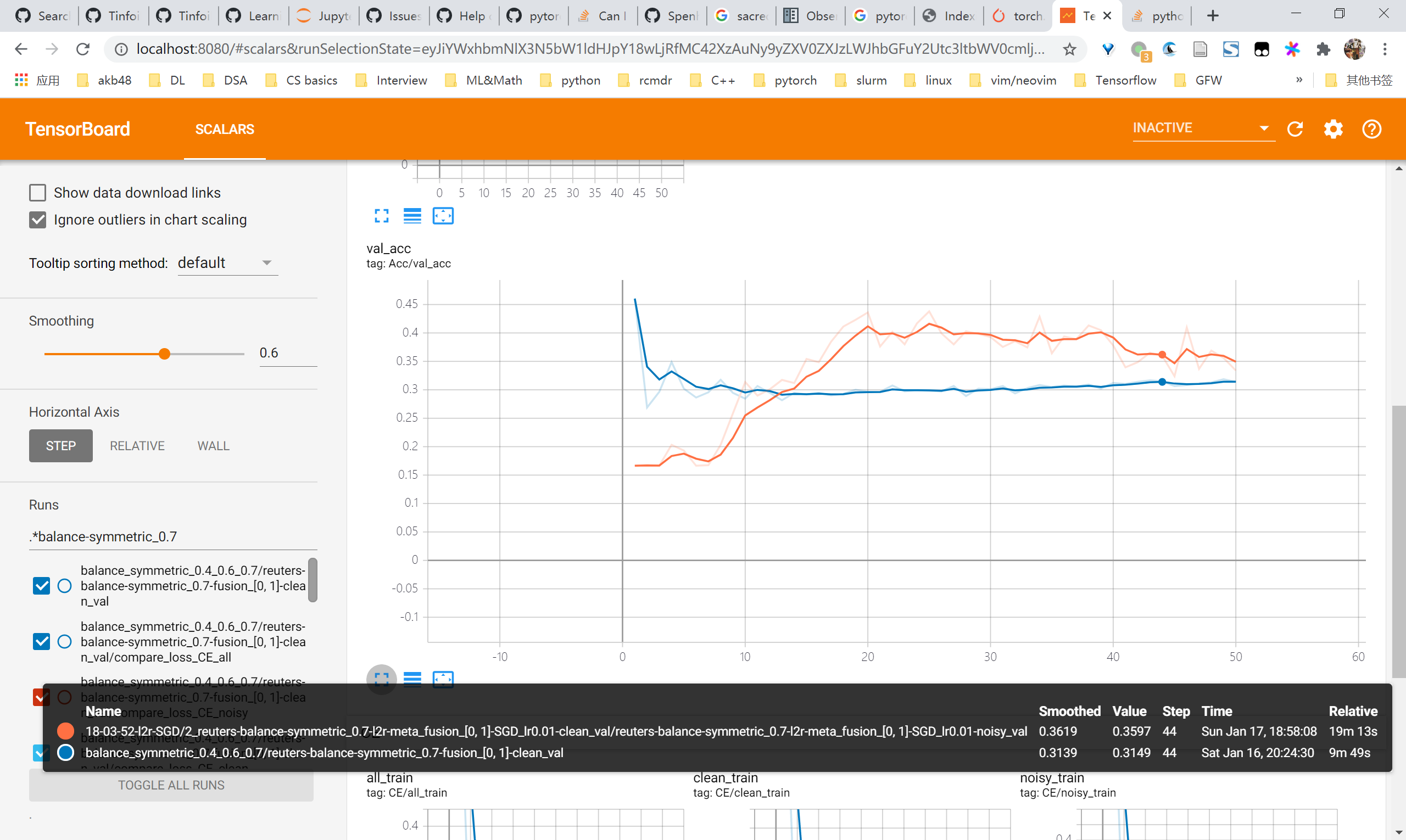
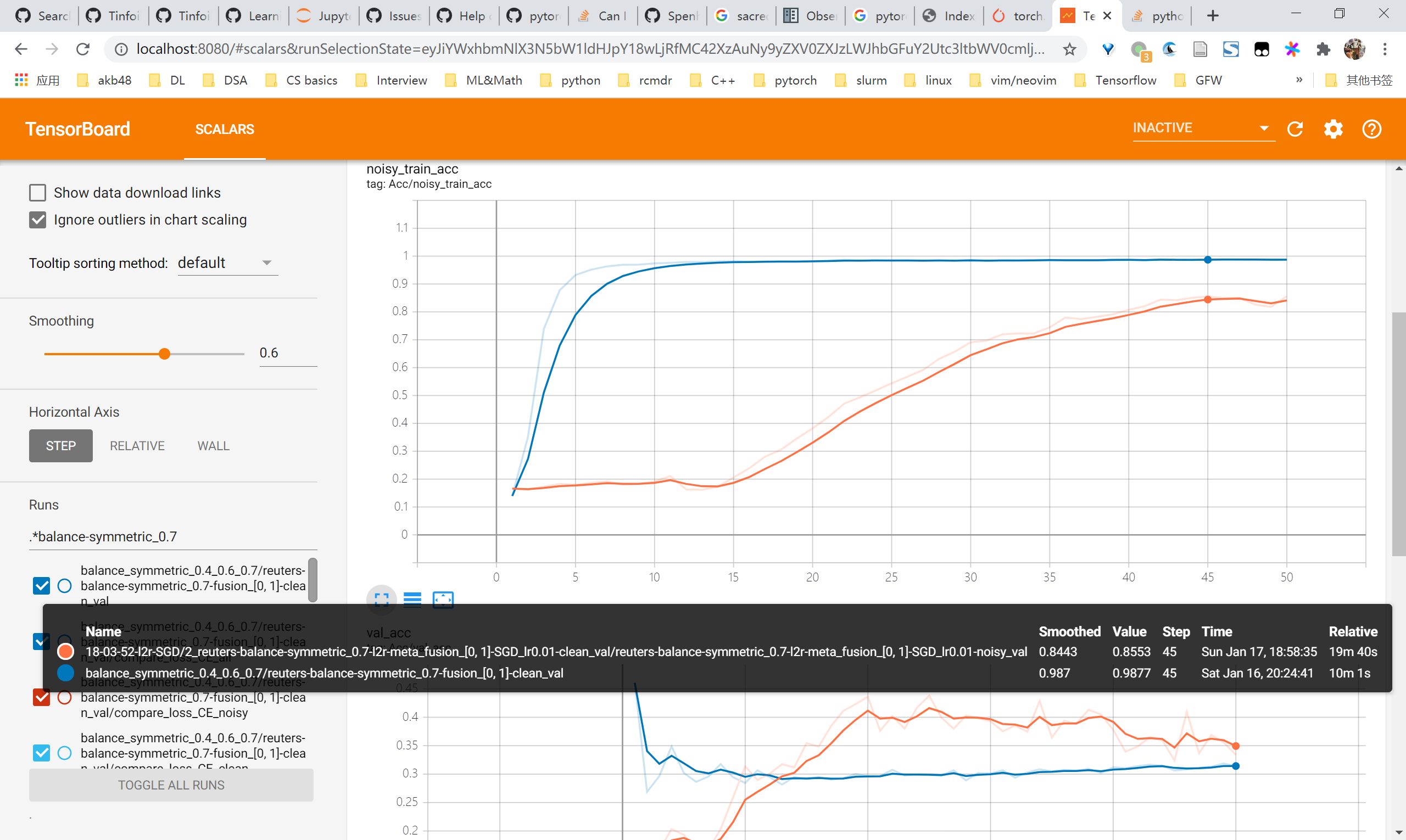
L2R reuters尝试
总体来看,用SGD优化的情况下是有效果的,在未调参的情况下能够对比baseline有4-5个点的提升乃至10个点的提升。但是观察曲线可以发现noisy acc始终还是在上升的,即仍然会对noisy samples过拟合,因此要尽快考虑regularization的方法比如mixup
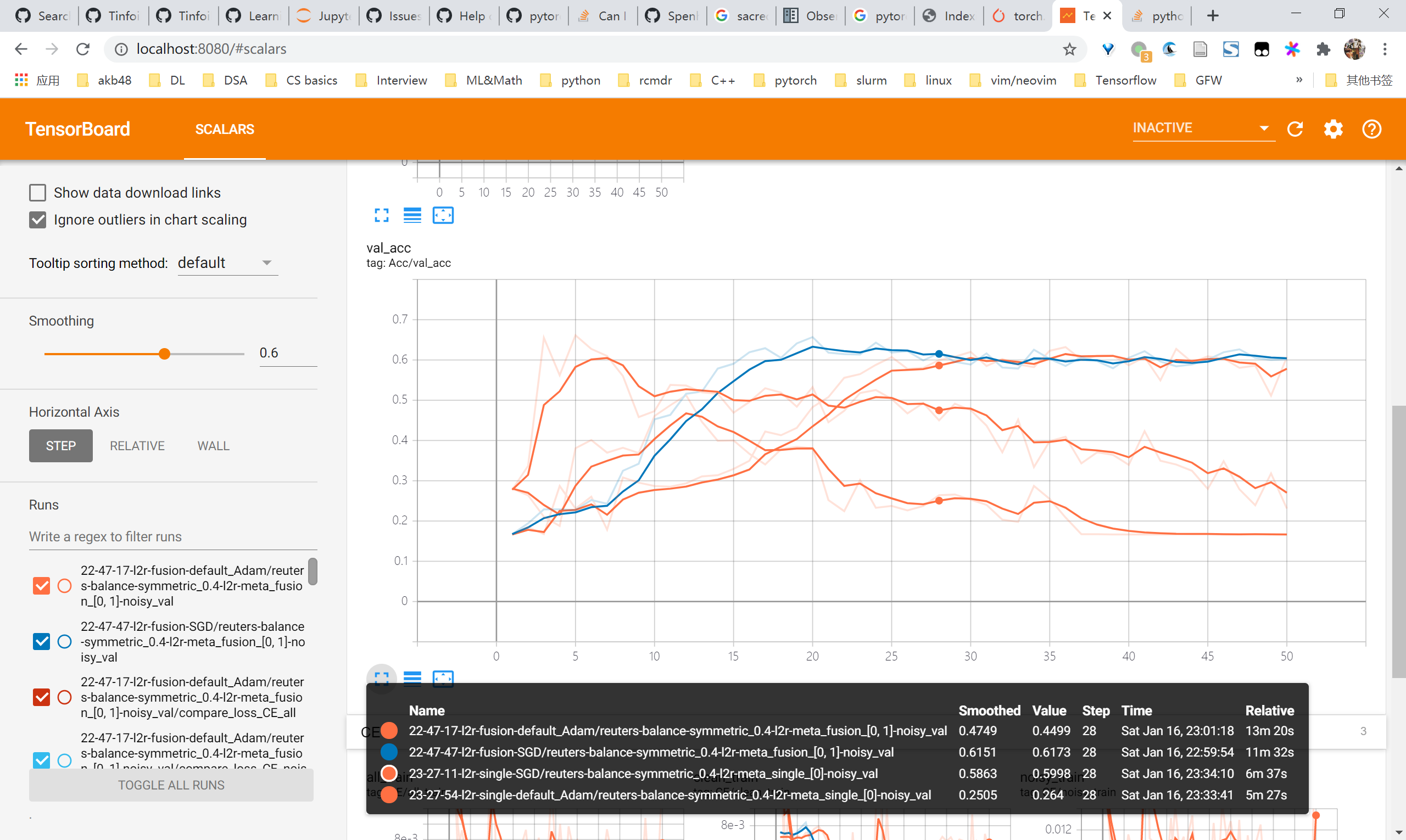
对比 baseline
- 0.4
- 0.6
- 0.7
DivideMix
sym 0.4
-------------------------------------------------------------------------------------------------------------------------------------------------------------
Exp: reuters-balance-symmetric_0.4-dividemix-fusion_[0, 1]-SGD_lr0.01-clean_val
h_score loss loss_2 label_loss_1 loss loss_1 entropy unlabeled_loss_1 unlabeled_loss_2 loss_2 label_loss_2 loss_1 duration accuracy
train valid valid train train valid valid train train train train train train valid
epoch-25 NaN NaN 1.177624 0.777585 NaN 1.060939 0.767858 0.008861 0.011454 1.231793 0.860347 1.097191 19.891s 0.660138
=============================================================================================================================================================
Best val epoch on run 2:11, test accuracy: 0.6828
=============================================================================================================================================================
3 runs avg accuracy: 0.6897/0.0051. Each run test accuracy:
['0.6914', '0.6948', '0.6828']
sym 0.6
-------------------------------------------------------------------------------------------------------------------------------------------------------------
Exp: reuters-balance-symmetric_0.6-dividemix-fusion_[0, 1]-SGD_lr0.01-clean_val
entropy loss_1 h_score unlabeled_loss_2 label_loss_2 loss_2 label_loss_1 accuracy loss_1 unlabeled_loss_1 loss duration loss
valid train train train train valid train train valid valid train train train valid
epoch-25 0.753669 1.4467 NaN 0.007444 0.23004 2.827142 1.358757 0.354897 0.165899 2.842674 0.016391 NaN 23.219s NaN
=============================================================================================================================================================
Best val epoch on run 2:11, test accuracy: 0.1672
=============================================================================================================================================================
3 runs avg accuracy: 0.3029/0.0976. Each run test accuracy:
['0.3931', '0.3483', '0.1672']
sym 0.7
-------------------------------------------------------------------------------------------------------------------------------------------------------------
Exp: reuters-balance-symmetric_0.7-dividemix-fusion_[0, 1]-SGD_lr0.01-clean_val
entropy loss_1 h_score unlabeled_loss_2 label_loss_2 loss_2 label_loss_1 accuracy loss_1 unlabeled_loss_1 loss duration loss
valid train train train train valid train train valid valid train train train valid
epoch-25 0.897166 1.642383 NaN 0.007334 0.228026 2.936547 1.381694 0.562114 0.167051 2.332163 0.029605 NaN 14.290s NaN
=============================================================================================================================================================
Best val epoch on run 2:17, test accuracy: 0.3069
=============================================================================================================================================================
3 runs avg accuracy: 0.3397/0.0283. Each run test accuracy:
['0.3759', '0.3362', '0.3069']
IEG
可能尝试的点(DONE)
无法augment的数据
- 对于reuters这种难以augment的数据,主要会影响的点在于原版中的pseudo label部分,因此可以考虑:
- 按照K=1的情况进行,即直接用iteration output作为pseudo label,然后也去除掉KL loss,剩下原来的四部分
- 类似于ICT这种用同一个batch内的unlabelled sample进行mixup然后算一个unsupervised loss,代替KL loss,这么做等价于5个loss中有三个mixup loss
- 根据noisy student的观点:noise可以分为两类:input noise和model noise。前者主要指的是data augmentation,后者则是dropout和stochastic depth
- mixmatch及其变种中大多数是利用了data augmentation即input noise,但是很多数据比如像reuters这种直接提取好特征找不到元数据的数据集,是没办法直接进行augment的。
- 因此对于这种情况,只能考虑后面的model noise。但是显然model noise并不是对sample进行处理的,直接套并不现实。并且model noise和input noise在theory上是否等同?这个点也是需要考虑的。如果不等同,显然不是一个好主意。
- mixmatch中用到的data augmentation大多数还是为了保证consistency regularization,而consistency regularization在ICT的文章中说的也挺清楚的,最核心要把握的点就是保证在low density region中的样本有consistency regularization,即small perturbation不会让模型的输出发生变化
hard weights和percentile的影响
当前的实现是使用归一化后的weight(-min / max - min)来实现的,但是实际上可能更好的方式直接利用torch.quantile找出对应的分位数,然后用这个作为阈值直接去卡weights。当前实测两种方法筛选出来的样本有一定差异(7/256),总体差异可能不是太大,待实验
注意TensorFlow的实现中是没有使用threshold的
原文中的Algorithm的step 4有提到说有一个threshold的设置,只有低于threshold的才认为是possibly mislabeled的samples,需要用guessed labels去代替。但是注意看Appendix B,里面最后提到了:
Algorithm 1 step 4 uses a weight threshold T to divide the training batch to possibly clean set and possibly mislabeled set. In our experiments, we find setting T to be highest is optimal in terms of training stability, i.e. all data is treated as possibly mislabeled, because it makes the batch size fixed to compute other losses that use data with pseudo labels
这里可以理解为:对于 Sec 4.4里面的两个CE loss,如果不是按照原文那样的设置,将会导致这两个loss对应的样本始终在变化,也即导致loss的大小可能变化地很剧烈。
具体实验的时候还要具体考虑一下。可能需要还原回原文的设置
注意batch size对meta_valid_data_loader的影响
默认是使用下面这个inf_loop来实现无穷枚举
def inf_loop(data_loader):
''' wrapper function for endless data loader. '''
for loader in repeat(data_loader):
yield from loader但这种方式有两个问题:
- 由于默认
drop_last=False,因此如果len(dataset)不能被batch_size整除,则最后一小部分会被单独取出(因为这里本质上就是不断把一个个batch从data_loader中循环取出)。导致batch_size不是恒定的。 - 如果整个
len(dataset)默认就比batch_size小,则每次取出的batch必然都会比设定的batch_size小
特别上面,下面这种做法在meta_valid_data_loader.dataset的大小比默认的batch_size小的时候,每次取出的meta_data必然是不足的;如果不能被整除,则末尾那个meta_batch的大小也不正常。
for batch_idx, (batch_data, meta_data) in enumerate(zip(self.data_loader, self.meta_valid_data_loader)):正确做法可以用类似下面这种思路:
def g(x, size=8):
all_res = []
for t in cycle(range(x)):
if len(all_res) >= size:
yield all_res
all_res = [t]
else:
all_res.append(t)
iter_1 = iter(g(5))
for i in range(2):
print(next(iter_1))[0, 1, 2, 3, 4, 0, 1, 2]
[3, 4, 0, 1, 2, 3, 4, 0]这里需要做的是改一下merge的逻辑
def inf_loop_v2(data_loader, batch_size):
''' wrapper function for endless data loader. Fix batch_size bug for torch only'''
merged_batch = [torch.tensor([])]
for idx, batch in enumerate(cycle(data_loader)):
if idx == 0:
merged_batch = list(batch)
else:
merged_batch = [torch.cat([data, cur_data], 0) for data, cur_data in zip(merged_batch, batch)]
if merged_batch[0].size(0) >= batch_size:
return_data = [data[:batch_size] for data in merged_batch]
yield return_data
merged_batch = [data[batch_size:] for data in merged_batch]unsupervised loss中对probe image的permutation操作
n_probe_to_mix = tf.shape(aug_images)[0]
probe = tf.tile(tf.constant([[10.]]), [1, tf.shape(probe_images)[0]])
idx = tf.squeeze(tf.random.categorical(probe, n_probe_to_mix))上面这段操作本质上应该是不需要的,推测的原因可能是为了MixMode中不同mixup操作方式的需要。故可以考虑保留
augmented samples的labels
总体来说都是和未增强前的samples共用label
- 对于possibly clean samples来说,就是未增强前的label,即一个hard label
- 对于possibly mislabeled samples来说,就是用g,即一个soft label
pytorch实验尝试
sym0.4
最好的尝试:固定mis_threshold=1.1即如原文那样
2021-01-26/16-47-27-None/
====================================================================================================================================================
==========================================
Best val epoch on run 0:13, test accuracy: 0.7655
====================================================================================================================================================
==========================================
1 runs avg accuracy: 0.7655/0.0000. Each run test accuracy:
['0.7655']
2021-01-26/16-51-09-None
===================================================================================================================================================
=========================================
Best val epoch on run 0:18, test accuracy: 0.7655
====================================================================================================================================================
=========================================
1 runs avg accuracy: 0.7655/0.0000. Each run test accuracy:
['0.7655']
尝试用动态ce_factor的方法:不太好,不如固定的
2021-01-26/19-51-01-None/
2021-01-26/19-51-01-None/reuters_ieg_train.log:1619:[2021-01-26 20:03:53,889][base-trainer][INFO] - Best val epoch on run 0:14, test accuracy: 0.6948
sym 0.6
同样是固定ce_factor
2021-01-26/19-50-32-None/reuters_ieg_train.log:3923:[2021-01-26 20:24:25,578][base-trainer][INFO] - Best val epoch on run 0:16, test accuracy: 0.6241
尝试fake augment(两次mixup)
效果不大
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Exp: reuters-balance-symmetric_0.4-ieg-meta_fusion_[0, 1]-SGD_lr0.01-clean_val
meta_acc weight_acc meta_loss accuracy h_score unlabeled_loss loss eps_loss ... ema_loss unlabeled_u_loss loss unlabeled_kl_loss eps_acc duration w_loss unlabeled_l_loss
train train train valid train train valid train ... valid train train train train train train train
epoch-25 0.004568 0.402382 0.035882 0.704598 NaN 2.032226 0.856156 0.713818 ... 0.953503 0.343933 2.463873 0.00215 0.732781 41.601s 0.149475 0.310409
[1 rows x 17 columns]
=======================================================================================================================================================================================================
Best val epoch on run 0:10, test accuracy: 0.7534
=======================================================================================================================================================================================================
1 runs avg accuracy: 0.7534/0.0000. Each run test accuracy:
['0.7534']
Save at /home/weitaotang/multimodal/pytorch_hydra_results_temp/debug/2021-01-27/16-15-34-None
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Exp: reuters-balance-symmetric_0.4-ieg-meta_fusion_[0, 1]-SGD_lr0.01-clean_val
unlabeled_l_loss duration loss unlabeled_loss h_score meta_acc meta_loss ... eps_acc w_loss eps_loss ema_loss accuracy weight_acc ema_accuracy unlabeled_u_loss
train train valid train train train train train ... train train train valid valid train valid train
epoch-20 0.454691 41.396s 0.78376 3.406944 2.877247 NaN 0.004635 0.035477 ... 0.749871 0.152077 0.907316 0.982341 0.751724 0.402382 0.710345 0.479111
[1 rows x 17 columns]
Normal model test on 580 samples | Acc 0.7431
==================================================================================================================================================================================================
Best val epoch on run 0:20, test accuracy: 0.7431
==================================================================================================================================================================================================
1 runs avg accuracy: 0.7431/0.0000. Each run test accuracy:
['0.7431']
Save at /home/weitaotang/multimodal/pytorch_hydra_results_temp/debug/2021-01-27/16-40-22-None
0128 调参记录:暂时是效果最好的,acc能到0.81637
IEG + DivideMix
可能可以尝试的点
- inconsistency error?就是KL,不过不是minimize而是maximize
尝试1: IEG + 仅仅加入weighted guessed labels
基本是IEG的底子,两个模型,同时是step-based的更新方式,计算所有loss都是用自己所挑选出来的那一份数据。区别在使用了weighted labels作为最后的unlabelled部分的输出。
mis_threshold=1.1因此默认所有samples都是unlabelled samples,因此直接使用weighted_guess_labels的时候能够很方便地直接相加
有一定效果(取平均,大概2-3个点)
================================================================================================================================================================================================
Best val epoch on run 0:17, test accuracy: 0.8121
================================================================================================================================================================================================
1 runs avg accuracy: 0.8121/0.0000. Each run test accuracy:
['0.8121']
核心代码部分:
mis_logits_1, mis_inputs_1, all_c_inputs_1, all_c_labels_1, mis_idx_1 = self._get_mis_c(hard_weight_1,
logits_1,
inputs,
meta_inputs_1,
meta_clean_labels_1,
labels)
mis_logits_2, mis_inputs_2, all_c_inputs_2, all_c_labels_2, mis_idx_2 = self._get_mis_c(hard_weight_2,
logits_2,
inputs,
meta_inputs_2,
meta_clean_labels_2,
labels) def _weighted_guess_label(self, batch_logits_1, w1, batch_logits_2, w2):
# K = batch_logits.size(0)
with torch.no_grad():
# old_w1, old_w2 = w1.clone().detach(), w2.clone().detach()
invalid_index = torch.logical_and(w1 == 0.0, w2 == 0.0)
w1[invalid_index], w2[invalid_index] = 1e-8, 1e-8
reweight_w1 = (w1 / (w1 + w2)).reshape(-1, 1)
reweight_w2 = (w2 / (w1 + w2)).reshape(-1, 1)
# expected K x batch x num_feat
all_u_logits_1 = torch.unbind(batch_logits_1, dim=0)
norm_logits_1 = [logit_norm(x) * reweight_w1 for x in all_u_logits_1]
p_model_y_1 = torch.cat([torch.unsqueeze(torch.softmax(logits, dim=1), 0) for logits in norm_logits_1])
p_model_y_1 = torch.mean(p_model_y_1, dim=0)
all_u_logits_2 = torch.unbind(batch_logits_2, dim=0)
norm_logits_2 = [logit_norm(x) * reweight_w2 for x in all_u_logits_2]
p_model_y_2 = torch.cat([torch.unsqueeze(torch.softmax(logits, dim=1), 0) for logits in norm_logits_2])
p_model_y_2 = torch.mean(p_model_y_2, dim=0)
p_model_y = reweight_w1 * p_model_y_1 + reweight_w2 * p_model_y_2
p_target = torch.pow(p_model_y, 1.0 / self.config.T)
p_target /= torch.sum(p_target, dim=1, keepdim=True)
return p_targetema_decay: 0.999
meta_momentum: 0.9
grad_eps_init: 0.9
ce_factor: 9
consistency_factor: 20
T: 0.5
beta: 0.5
meta_lr: 1e-4
mis_threshold: 1.1 # 1.1 means treat all to be mislabel
learning_rate: 0.03
use_fake_aug: false
fake_aug_lambda: 0.95
use_scheduler: false
use_penalty: false尝试2:进一步交换二者信息
效果差不多
参数设置同样设置mis_threshold=1.1(即最后两个weighted_guessed_labels是相同的),ce_factor=5, learning_rate=0.01,其实和尝试1是差不多的参数,发现效果和1其实差不多
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Exp: reuters-balance-symmetric_0.4-ieg_dividemix-meta_fusion_[0, 1]-SGD_lr0.03-clean_val
loss_2 loss_1 acc_1 eps_acc_1 w_loss_2 duration accuracy ... unlabeled_loss_1 weight_acc_2 meta_loss_1 w_loss_1 meta_acc_1 unlabeled_l_loss_2 meta_acc_2 meta_loss_2
valid train valid valid train train train valid ... train train train train train train train train
epoch-20 0.688819 6.708918 0.684294 0.777011 0.842914 0.302043 71.749s 0.793103 ... 6.392279 0.402382 0.044373 0.337714 0.004645 0.376796 0.004645 0.033203
[1 rows x 30 columns]
Test on 580 samples | Merged acc 0.8052 | Acc_1 0.8000 | Acc_2 0.8000
Saving current best with max accuracy/valid:0.7931: model_best.pth ...
=======================================================================================================================================================================================================
Best val epoch on run 0:20, test accuracy: 0.8052
=======================================================================================================================================================================================================
1 runs avg accuracy: 0.8052/0.0000. Each run test accuracy:
['0.8052']
核心代码如下:可以看到几乎整个输入都交换了
weight_1, hard_weight_1, eps_1, meta_loss_1, meta_acc_1 = self.meta_optimize(self.model, self.optimizer,
meta_inputs_1,
meta_clean_labels_1,
labels,
inputs,
init_guessed_labels_1)
weight_2, hard_weight_2, eps_2, meta_loss_2, meta_acc_2 = self.meta_optimize(self.model2,
self.optimizer2,
meta_inputs_2,
meta_clean_labels_2,
labels,
inputs,
init_guessed_labels_2)
exchange = True
if exchange:
weight_1, weight_2 = weight_2, weight_1
hard_weight_1, hard_weight_2 = hard_weight_2, hard_weight_1
meta_inputs_1, meta_inputs_2 = meta_inputs_2, meta_inputs_1
meta_clean_labels_1, meta_clean_labels_2 = meta_clean_labels_2, meta_clean_labels_1
mis_logits_1, mis_inputs_1, all_c_inputs_1, all_c_labels_1, mis_idx_1 = self._get_mis_c(weight_1,
hard_weight_1,
logits_1,
inputs,
meta_inputs_1,
meta_clean_labels_1,
labels)
mis_logits_2, mis_inputs_2, all_c_inputs_2, all_c_labels_2, mis_idx_2 = self._get_mis_c(weight_2,
hard_weight_2,
logits_2,
inputs,
meta_inputs_2,
meta_clean_labels_2,
labels)
# TODO: try co_guessed_labels
# co_guessed_labels = self._guess_label(torch.cat([logits_1, logits_2], 0))
# weighted_guessed_labels = self._weighted_coguess_label(torch.unsqueeze(mis_logits_1, 0), weight_1,
# torch.unsqueeze(mis_logits_2, 0), weight_2)
weighted_guessed_labels_1 = self._weighted_single_guess_labels(torch.unsqueeze(mis_logits_1, 0),
mis_idx_1, weight_1,
torch.unsqueeze(logits_2, 0),
weight_2)
weighted_guessed_labels_2 = self._weighted_single_guess_labels(torch.unsqueeze(mis_logits_2, 0), mis_idx_2,
weight_2, torch.unsqueeze(logits_1, 0),
weight_1)
assert (weighted_guessed_labels_1 == weighted_guessed_labels_2).all()
l_loss_1, u_loss_1, consistency_loss_1 = self.single_unsupervised_loss(self.model, mis_logits_1,
mis_inputs_1, all_c_inputs_1,
all_c_labels_1,
weighted_guessed_labels_1)
l_loss_2, u_loss_2, consistency_loss_2 = self.single_unsupervised_loss(self.model2, mis_logits_2,
mis_inputs_2, all_c_inputs_2,
all_c_labels_2,
weighted_guessed_labels_2)
if exchange:
weight_1, weight_2 = weight_2, weight_1
w_loss_1, eps_loss_1 = self.lambda_weight_loss(logits_1, labels, eps_1, weight_1,
weighted_guessed_labels_1)
w_loss_2, eps_loss_2 = self.lambda_weight_loss(logits_2, labels, eps_2, weight_2,
weighted_guessed_labels_2)
un_loss_1 = l_loss_1 + self.config.ce_factor * u_loss_1 + self.config.consistency_factor * consistency_loss_1
un_loss_2 = l_loss_2 + self.config.ce_factor * u_loss_2 + self.config.consistency_factor * consistency_loss_2
loss_1 = (w_loss_1 + eps_loss_1) / 2. + un_loss_1
loss_2 = (w_loss_2 + eps_loss_2) / 2. + un_loss_2bug 1:RuntimeError: cannot sample n_sample <= 0 samples
Traceback (most recent call last):
File "/home/weitaotang/.conda/envs/multimodal/lib/python3.7/site-packages/hydra/_internal/utils.py", line 347, in _run_hydra
lambda: hydra.run(
File "/home/weitaotang/.conda/envs/multimodal/lib/python3.7/site-packages/hydra/_internal/utils.py", line 201, in run_and_report
raise ex
File "/home/weitaotang/.conda/envs/multimodal/lib/python3.7/site-packages/hydra/_internal/utils.py", line 198, in run_and_report
return func()
File "/home/weitaotang/.conda/envs/multimodal/lib/python3.7/site-packages/hydra/_internal/utils.py", line 350, in <lambda>
overrides=args.overrides,
File "/home/weitaotang/.conda/envs/multimodal/lib/python3.7/site-packages/hydra/_internal/hydra.py", line 112, in run
configure_logging=with_log_configuration,
File "/home/weitaotang/.conda/envs/multimodal/lib/python3.7/site-packages/hydra/core/utils.py", line 128, in run_job
ret.return_value = task_function(task_cfg)
File "srcs/entry_points/reuters_ieg_dividemix_train.py", line 145, in main
res = trainer.train()
File "/home/weitaotang/multimodal/hydra_templates/srcs/trainer/base.py", line 99, in train
result = self._train_epoch(epoch)
File "/home/weitaotang/multimodal/hydra_templates/srcs/trainer/reuters_ieg_dividemix_trainer.py", line 197, in _train_epoch
weighted_guessed_labels_1)
File "/home/weitaotang/multimodal/hydra_templates/srcs/trainer/reuters_ieg_dividemix_trainer.py", line 338, in single_unsupervised_loss
idx = m.sample((mis_logits.size(0),))
File "/home/weitaotang/.conda/envs/multimodal/lib/python3.7/site-packages/torch/distributions/categorical.py", line 107, in sample
samples_2d = torch.multinomial(probs_2d, sample_shape.numel(), True).T
RuntimeError: cannot sample n_sample <= 0 samplesHYDRA_FULL_ERROR=1 python srcs/entry_points/reuters_ieg_dividemix_train.py status=debug re_split_ratio=1.0 mis_threshold=0.2 learning_rate=0.005 ce_factor=9 meta_momentum=0.9 meta_lr=0.001 exchange_weigh
ts=True noise_rate=0.4 val_type=clean use_penalty=True trainer.save_ckpt=False trainer.epochs=25 trainer.test_on_best=True n_splits=2
查看发现是因为 mis_threshold太小,导致分位点恰好是最小值,因此是不存在比他小的idx,也就导致了mis_logits为empty tensor。导致sample_shape.numel()=0
一个可以考虑的方法:拿不到idx时取等
def _get_mis_c(self, weights, hard_weight, logits, inputs, meta_inputs, meta_clean_labels, labels):
if self.config.mis_method == "hard_weights" or self.config.mis_threshold >= 1.0:
mis_idx = hard_weight < self.config.mis_threshold
if mis_idx.sum() == 0: # 拿不到idx时取等
mis_idx = hard_weight <= self.config.mis_threshold
elif self.config.mis_method == "quantile":
mis_idx = weights < torch.quantile(weights, self.config.mis_threshold)
if mis_idx.sum() == 0:
mis_idx = weights <= torch.quantile(weights, self.config.mis_threshold)
else:
raise ValueError(f"Invalid mislabeled samples judgment method:{self.config.mis_method}")关于exchange weights的一些思考
其实单纯exchange weights或者exchange weights + eps意义不大:
- weights由于使用了weights co-guessing labels,因此其实交换前后真正受影响就是计算weight loss的部分,然而这部分显然还是不要交换会更稳定
- eps部分,同理受影响的只有eps loss部分,这部分同样还是不要交换会更加稳定
每个batch都进行hard weights或者weights sum to 1其实不是非常合理
强行把整个weights normalized到[0, 1]区间其实不合理,然后再按照一定的值进行截取(hard cut),会导致一定会有那么多数量的样本认为是clean,但是实际上是存在说整个batch都是noisy samples的情况。
同理把weights sum to 1,只是稍微好点,比如全部的samples的权重都比较小,此时强行让其sum to 1,就会使得有一部分的weight相对于原来有所增加。
可能比较好的做法是把所有weights都收集起来之后再进行normalized。然而这种做法不现实,因为这样等价于要全部都过一遍存下来,然后再forward一遍,无形中等价于多了一次forward的过程,时间太长
20210208 update(待实验)
所有weights都收集起来之后再进行normalized
对于上述这种做法,step-based的更新不是很好,还是要用epoch-based的方法来实验
Hydra复现
在代码不变的情况下,直接载入config文件,才能保证一致
比如下面这种方式,直接载入保存的config文件:
@hydra.main(
config_path='/home/weitaotang/multimodal/pytorch_hydra_results_temp/multirun/2021-02-01/01-00-04-dividemix_tuning_sym0.6_rerun/26_reuters-balance-symmetric_0.6-dividemix-optuna-fusion_N_[0, 1]-SGD_lr0.02-clean_val',
config_name='config')原来的实验:

复现的实验结果:

但是缺点就是还要单独定制输出的文件夹,否则会很难看,比如下面这个实验就是会直接保存到当前目录的outputs下面
[2021-02-01 11:39:25,075][base-trainer][INFO] - Exp: reuters-balance-symmetric_0.6-dividemix-optuna-fusion_N_[0, 1]-SGD_lr0.02-clean_val
[2021-02-01 11:39:25,115][base-trainer][INFO] - loss unlabeled_loss_2 accuracy unlabeled_loss_1 loss_2 label_loss_2 duration loss_2 entropy h_score label_loss_1 loss loss_1
train train valid train valid train train train valid train train valid valid train
epoch-25 NaN 0.005178 0.542002 0.005377 1.43616 0.751425 28.738s 0.979027 0.949788 NaN 0.784438 NaN 1.546014 1.011149
[2021-02-01 11:39:25,119][base-trainer][INFO] - =============================================================================================================================================================
=
[2021-02-01 11:39:25,119][base-trainer][INFO] - Best val epoch on run 1:14, test accuracy: 0.6448
[2021-02-01 11:39:25,119][base-trainer][INFO] - =============================================================================================================================================================
=
[2021-02-01 11:39:25,814][train][INFO] - 2 runs avg accuracy: 0.6198/0.0250. Each run test accuracy:
['0.5948', '0.6448']
[2021-02-01 11:39:25,815][train][INFO] - Save at /home/weitaotang/multimodal/hydra_templates/outputs/2021-02-01/10-59-35
如果直接使用超参,效果是一样的,不过就是要单独配置参数,稍微有点麻烦
HYDRA_FULL_ERROR=1 python srcs/entry_points/reuters_dividemix_train.py status=train warm_up_epochs=8 p_threshold=0.6000000000000001 alpha=4 lambda_u=30 weight_decay=1e-05 learning_rate=0.02 fusion=sum rank=3 noise_rate=0.6 val_type=clean trainer.save_ckpt=False trainer.epochs=25 trainer.test_on_best=True notes=dividemix_tuning_sym0.6_rerun n_splits=2 model=reuters_fusion_N
/home/weitaotang/multimodal/pytorch_hydra_results_temp/train/2021-02-01/12-09-21-dividemix_tuning_sym0.6_rerun/config.yaml

Profiling IEG Train
命令:
HYDRA_FULL_ERROR=1 python srcs/entry_points/profile_entries/profiling_reuters_ieg_train.py model=reuters_meta_fusion_N notes="test_fast_dl" trainer.epochs=1 trainer.save_ckpt=false trainer.test_on_best=
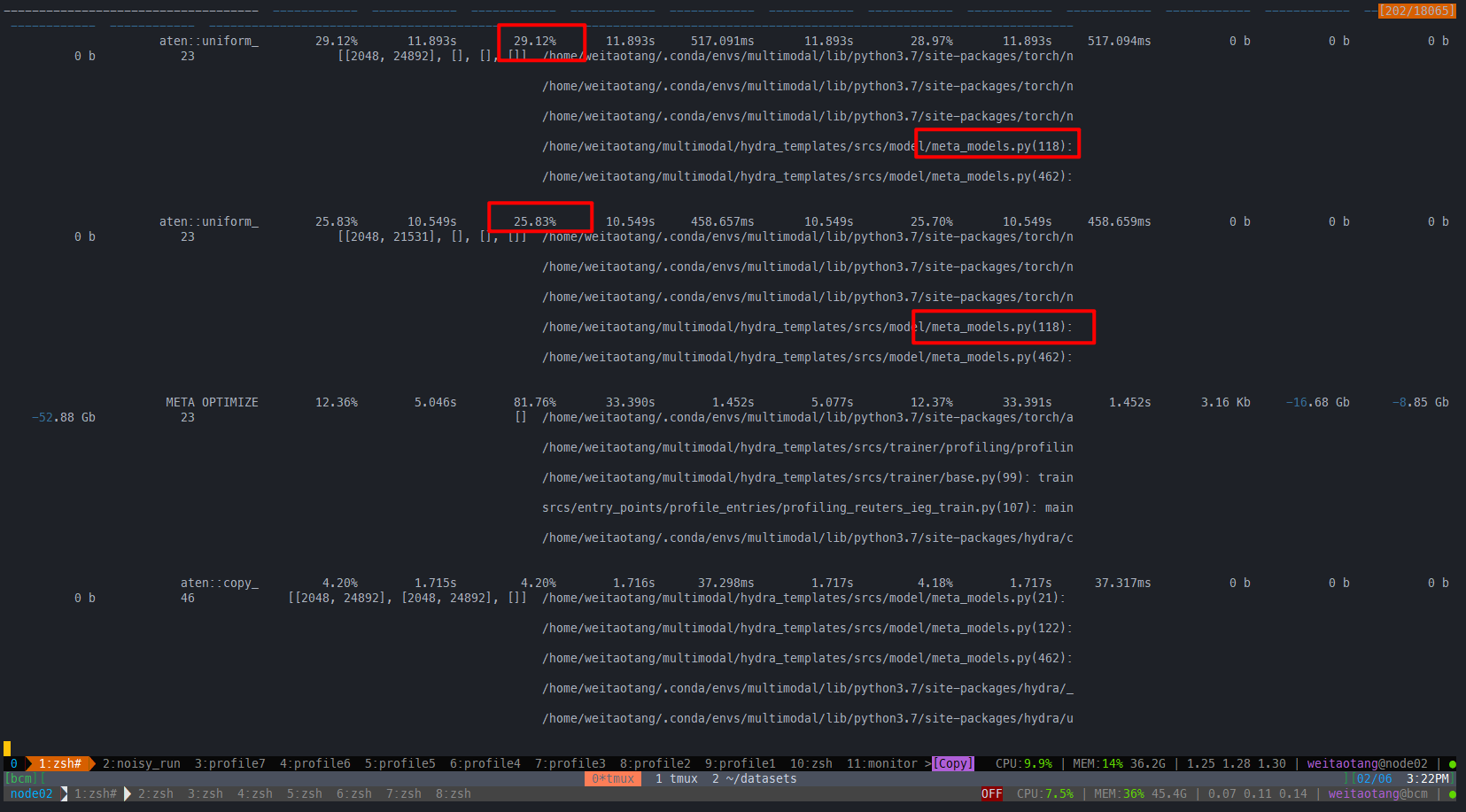
true balance=balance noise_rate=0.4 n_splits=1 data=reuters_all_cv_ieg_dividemix_train可以看到两个大头始终是创建meta model这块
reuters直接上all cuda也是不太合适的
依然爆显存
xrmb和reuters 三种DataLoader的对比
reuters
Initialized train Reuters
train dataset with 15006 samples
Original fast dataloader finish with:15.5962 second
Prefetcher BackgroundGenerator + fast dataloader finish with:16.0180 second
DataPrefetcher + fast dataloader finish 59 its/1 with:3.7941 second
DataPrefetcher + fast dataloader finish 59 its/2 with:3.8048 second
DataPrefetcher + fast dataloader finish 59 its/3 with:3.7636 second
DataPrefetcher + fast dataloader finish 59 its/4 with:3.8045 second
DataPrefetcher + fast dataloader finish with:15.5066 second
Initialized train Reuters
train dataset with 15006 samples
Original fast dataloader finish with:15.3795 second
Prefetcher BackgroundGenerator + fast dataloader finish with:15.3820 second
DataPrefetcher + fast dataloader finish 59 its/1 with:3.6750 second
DataPrefetcher + fast dataloader finish 59 its/2 with:3.6984 second
DataPrefetcher + fast dataloader finish 59 its/3 with:3.6271 second
DataPrefetcher + fast dataloader finish 59 its/4 with:3.7781 second
DataPrefetcher + fast dataloader finish with:15.1373 second
Initialized train Reuters
train dataset with 15006 samples
Original fast dataloader finish with:15.2086 second
Prefetcher BackgroundGenerator + fast dataloader finish with:15.8317 second
DataPrefetcher + fast dataloader finish 59 its/1 with:3.7164 second
DataPrefetcher + fast dataloader finish 59 its/2 with:3.7532 second
DataPrefetcher + fast dataloader finish 59 its/3 with:3.7519 second
DataPrefetcher + fast dataloader finish 59 its/4 with:3.8027 second
DataPrefetcher + fast dataloader finish with:15.3566 second
Initialized train Reuters
train dataset with 15007 samples
Original fast dataloader finish with:15.3415 second
Prefetcher BackgroundGenerator + fast dataloader finish with:15.7691 second
DataPrefetcher + fast dataloader finish 59 its/1 with:3.9011 second
DataPrefetcher + fast dataloader finish 59 its/2 with:3.8108 second
DataPrefetcher + fast dataloader finish 59 its/3 with:3.8389 second
DataPrefetcher + fast dataloader finish 59 its/4 with:3.7030 second
DataPrefetcher + fast dataloader finish with:15.6202 second
Initialized train Reuters
train dataset with 15007 samples
Original fast dataloader finish with:15.4841 second
Prefetcher BackgroundGenerator + fast dataloader finish with:15.9197 second
DataPrefetcher + fast dataloader finish 59 its/1 with:3.7280 second
DataPrefetcher + fast dataloader finish 59 its/2 with:3.7924 second
DataPrefetcher + fast dataloader finish 59 its/3 with:3.7113 second
DataPrefetcher + fast dataloader finish 59 its/4 with:3.8488 second
DataPrefetcher + fast dataloader finish with:15.4055 second
xrmb
DataPrefetcher + fast dataloader finish 644 its/19 with:0.2231 second [23/9811]
DataPrefetcher + fast dataloader finish with:4.0225 second
train dataset with 329312 samples
Original fast dataloader finish with:2.4979 second
Prefetcher BackgroundGenerator + fast dataloader finish with:2.5478 second
DataPrefetcher + fast dataloader finish 644 its/1 with:0.2043 second
DataPrefetcher + fast dataloader finish 644 its/2 with:0.2065 second
DataPrefetcher + fast dataloader finish 644 its/3 with:0.2066 second
DataPrefetcher + fast dataloader finish 644 its/4 with:0.2056 second
DataPrefetcher + fast dataloader finish 644 its/5 with:0.2080 second
DataPrefetcher + fast dataloader finish 644 its/6 with:0.2032 second
DataPrefetcher + fast dataloader finish 644 its/7 with:0.2027 second
DataPrefetcher + fast dataloader finish 644 its/8 with:0.2055 second
DataPrefetcher + fast dataloader finish 644 its/9 with:0.2063 second
DataPrefetcher + fast dataloader finish 644 its/10 with:0.2052 second
DataPrefetcher + fast dataloader finish 644 its/11 with:0.2046 second
DataPrefetcher + fast dataloader finish 644 its/12 with:0.2053 second
DataPrefetcher + fast dataloader finish 644 its/13 with:0.2062 second
DataPrefetcher + fast dataloader finish 644 its/14 with:0.2065 second
DataPrefetcher + fast dataloader finish 644 its/15 with:0.2088 second
DataPrefetcher + fast dataloader finish 644 its/16 with:0.2072 second
DataPrefetcher + fast dataloader finish 644 its/17 with:0.2063 second
DataPrefetcher + fast dataloader finish 644 its/18 with:0.2057 second
DataPrefetcher + fast dataloader finish 644 its/19 with:0.2051 second
DataPrefetcher + fast dataloader finish with:3.9212 second
train dataset with 329312 samples
Original fast dataloader finish with:2.5407 second
Prefetcher BackgroundGenerator + fast dataloader finish with:2.5722 second
DataPrefetcher + fast dataloader finish 644 its/1 with:0.2071 second
DataPrefetcher + fast dataloader finish 644 its/2 with:0.2055 second
DataPrefetcher + fast dataloader finish 644 its/3 with:0.2021 second
DataPrefetcher + fast dataloader finish 644 its/4 with:0.2035 second
DataPrefetcher + fast dataloader finish 644 its/5 with:0.2055 second
DataPrefetcher + fast dataloader finish 644 its/6 with:0.2061 second
DataPrefetcher + fast dataloader finish 644 its/7 with:0.2042 second
DataPrefetcher + fast dataloader finish 644 its/8 with:0.2052 second
DataPrefetcher + fast dataloader finish 644 its/9 with:0.2064 second
DataPrefetcher + fast dataloader finish 644 its/10 with:0.2053 second
DataPrefetcher + fast dataloader finish 644 its/11 with:0.2057 second
DataPrefetcher + fast dataloader finish 644 its/12 with:0.2070 second
DataPrefetcher + fast dataloader finish 644 its/13 with:0.2101 second
DataPrefetcher + fast dataloader finish 644 its/14 with:0.2064 second
DataPrefetcher + fast dataloader finish 644 its/15 with:0.2057 second
DataPrefetcher + fast dataloader finish 644 its/16 with:0.2052 second
DataPrefetcher + fast dataloader finish 644 its/17 with:0.2044 second
DataPrefetcher + fast dataloader finish 644 its/18 with:0.2038 second
DataPrefetcher + fast dataloader finish 644 its/19 with:0.2065 second
DataPrefetcher + fast dataloader finish with:3.9167 second
train dataset with 329312 samples
Original fast dataloader finish with:2.5503 second
Prefetcher BackgroundGenerator + fast dataloader finish with:2.6478 second
DataPrefetcher + fast dataloader finish 644 its/1 with:0.2074 second
DataPrefetcher + fast dataloader finish 644 its/2 with:0.2052 second
DataPrefetcher + fast dataloader finish 644 its/3 with:0.2072 second
DataPrefetcher + fast dataloader finish 644 its/4 with:0.2066 second
DataPrefetcher + fast dataloader finish 644 its/5 with:0.2058 second
DataPrefetcher + fast dataloader finish 644 its/6 with:0.2084 second
DataPrefetcher + fast dataloader finish 644 its/7 with:0.2064 second
DataPrefetcher + fast dataloader finish 644 its/8 with:0.2050 second
DataPrefetcher + fast dataloader finish 644 its/9 with:0.2063 second
DataPrefetcher + fast dataloader finish 644 its/10 with:0.2062 second
DataPrefetcher + fast dataloader finish 644 its/11 with:0.2052 second
DataPrefetcher + fast dataloader finish 644 its/12 with:0.2042 second
DataPrefetcher + fast dataloader finish 644 its/13 with:0.2054 second
DataPrefetcher + fast dataloader finish 644 its/14 with:0.2045 second
DataPrefetcher + fast dataloader finish 644 its/15 with:0.2064 second
DataPrefetcher + fast dataloader finish 644 its/16 with:0.2043 second
DataPrefetcher + fast dataloader finish 644 its/17 with:0.2052 second
DataPrefetcher + fast dataloader finish 644 its/18 with:0.2068 second
DataPrefetcher + fast dataloader finish 644 its/19 with:0.2051 second
DataPrefetcher + fast dataloader finish with:3.9231 second
可以看到DataPrefecther并没有明显的优势,甚至说fast dataloader已经是最优了
实测也的确不太好
fast dataloader
DataPrefetcher
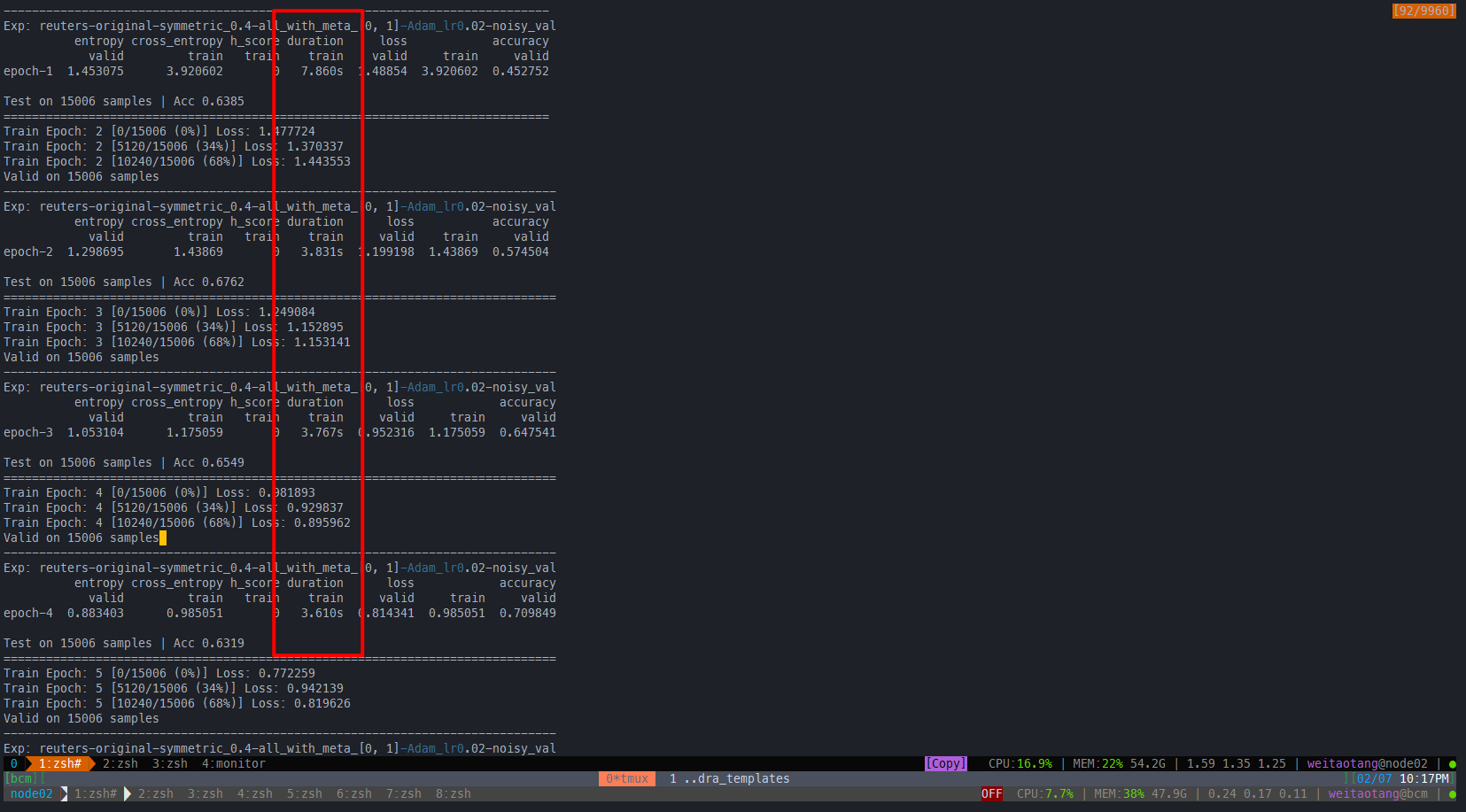
也许要在ravdness这一类audio visual数据集上才能体现优势
使用train_test_split或者StratifyKFold等Stratify split时要注意如果出现某个类别样本只有一个情况
即如下的错误:

ValueError: The least populated class in y has only 1 member, which is too few. The minimum number of groups for any class cannot be less than 2.很容易忽略的一个情况,可以用如下的异常捕捉处理
if stratify:
try:
stratify = self.raw_obj.labels.numpy()[self.indices]
train_idx, valid_idx = train_test_split(idx_full, test_size=validation_split, stratify=stratify)
except Exception as e:
traceback.print_exc(file=sys.stdout)
logger.warning(f"Stratify splits failed due to \"{e}\".\nreturn to random splits")
np.random.shuffle(idx_full)
valid_idx = idx_full[0:len_valid]
train_idx = np.delete(idx_full, np.arange(0, len_valid))
else:
np.random.shuffle(idx_full)
valid_idx = idx_full[0:len_valid]
train_idx = np.delete(idx_full, np.arange(0, len_valid))对于ravdess来说prefetcher有用
一个augmentation:
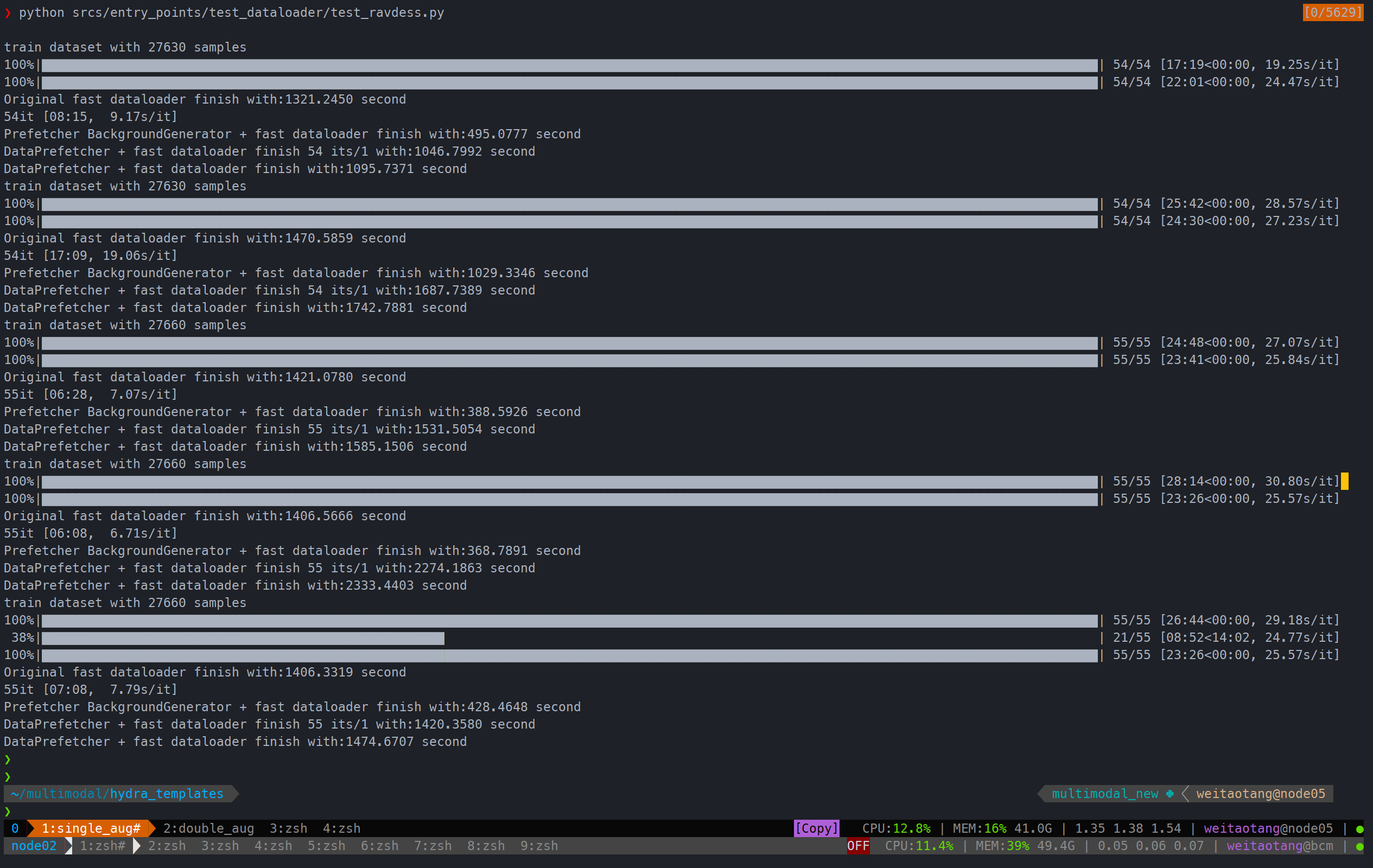
两个augmentation:
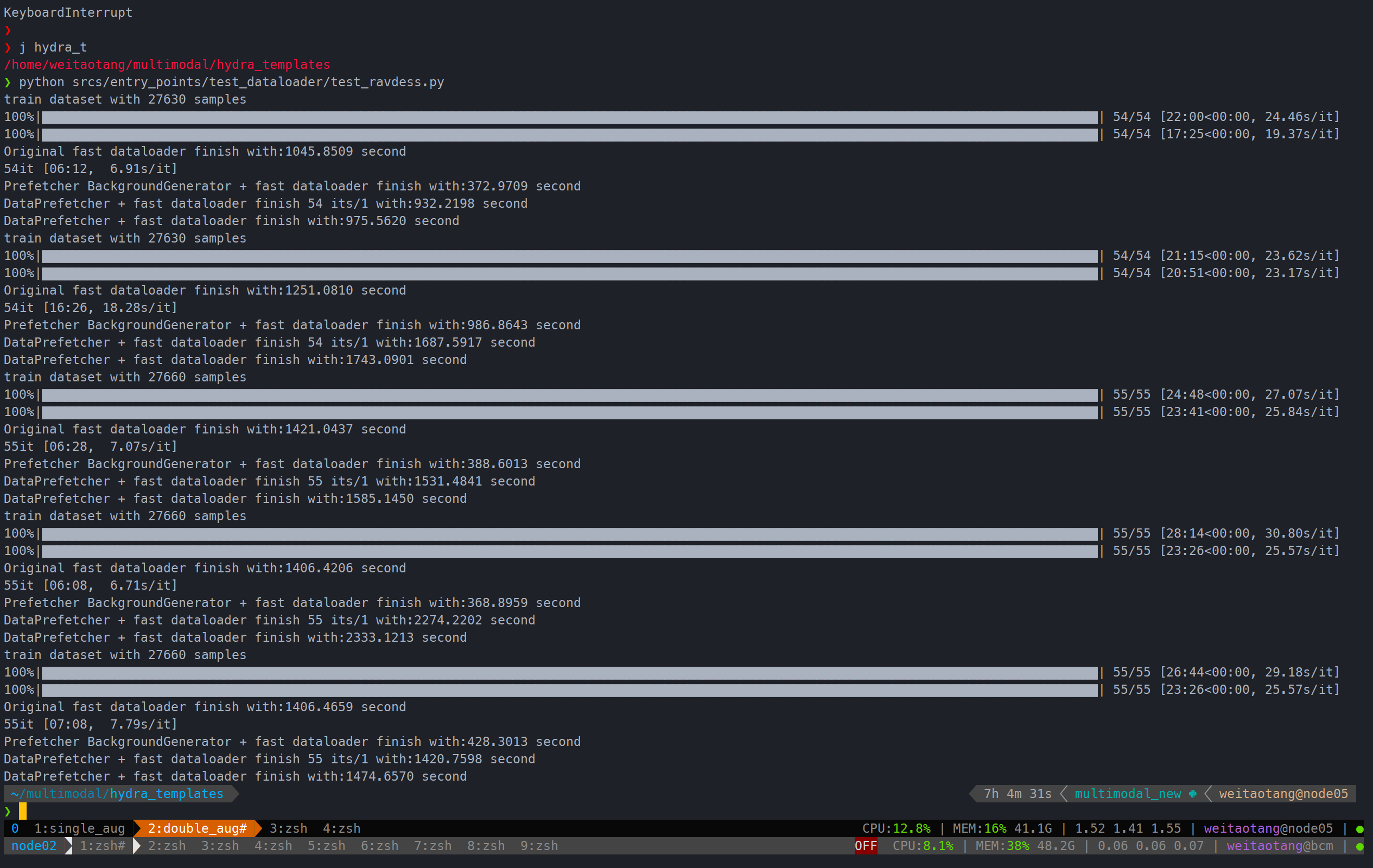
可以看到都缩短了不少
submitit.core.utils.UncompletedJobError解决
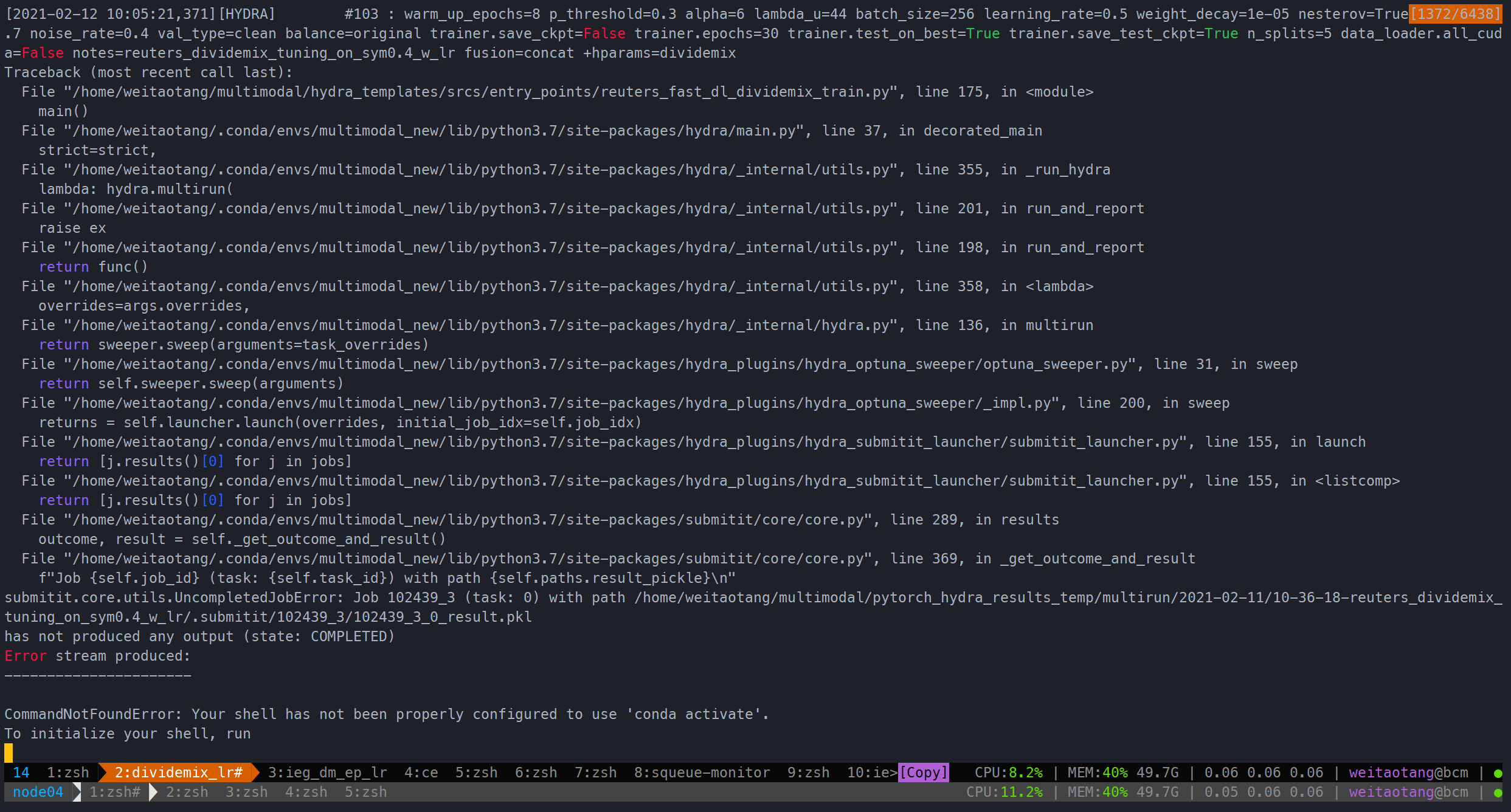
阅读源码发现大概率是保存的时间超时了,因为之后直接在ipython load进来是没问题的:
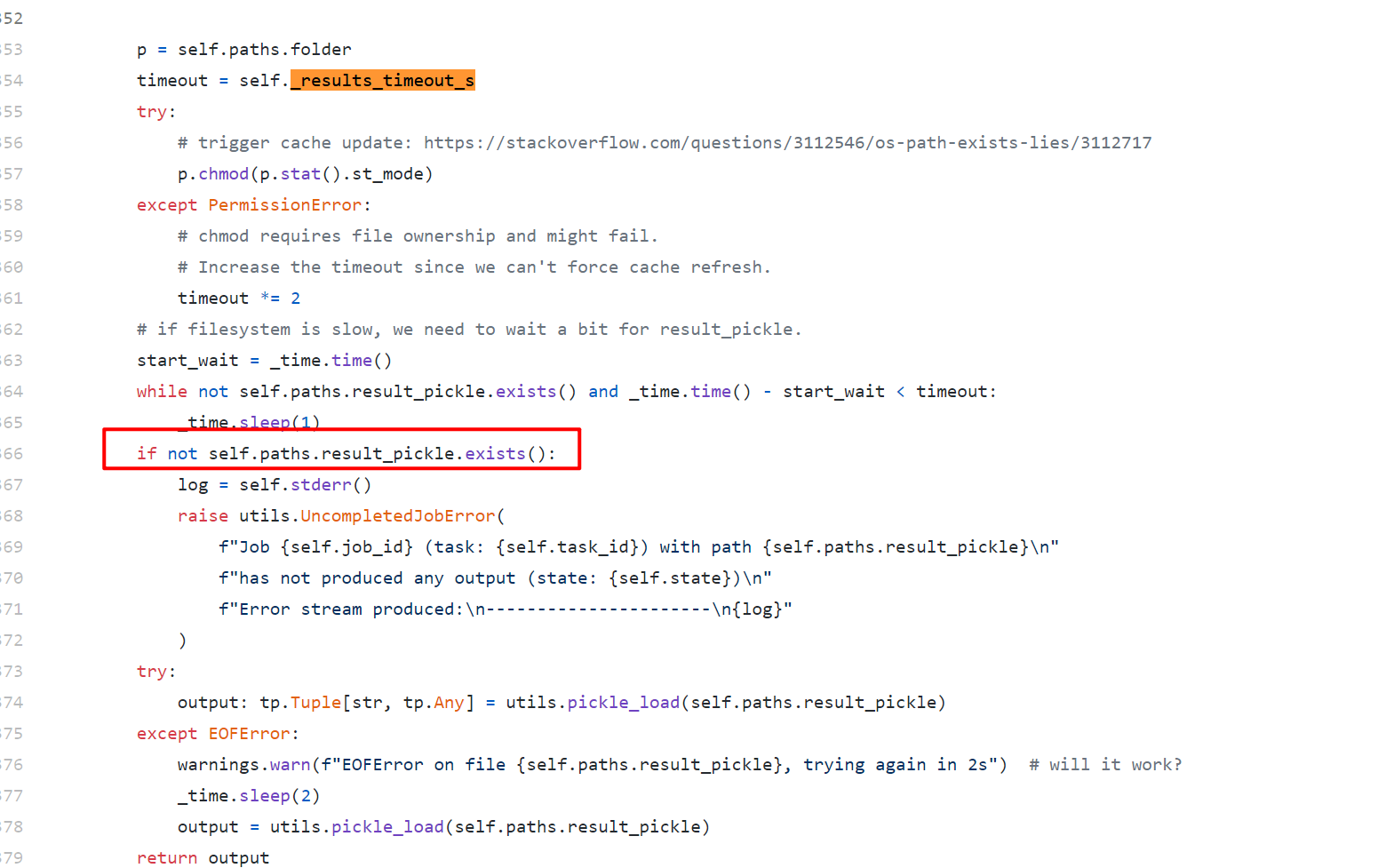
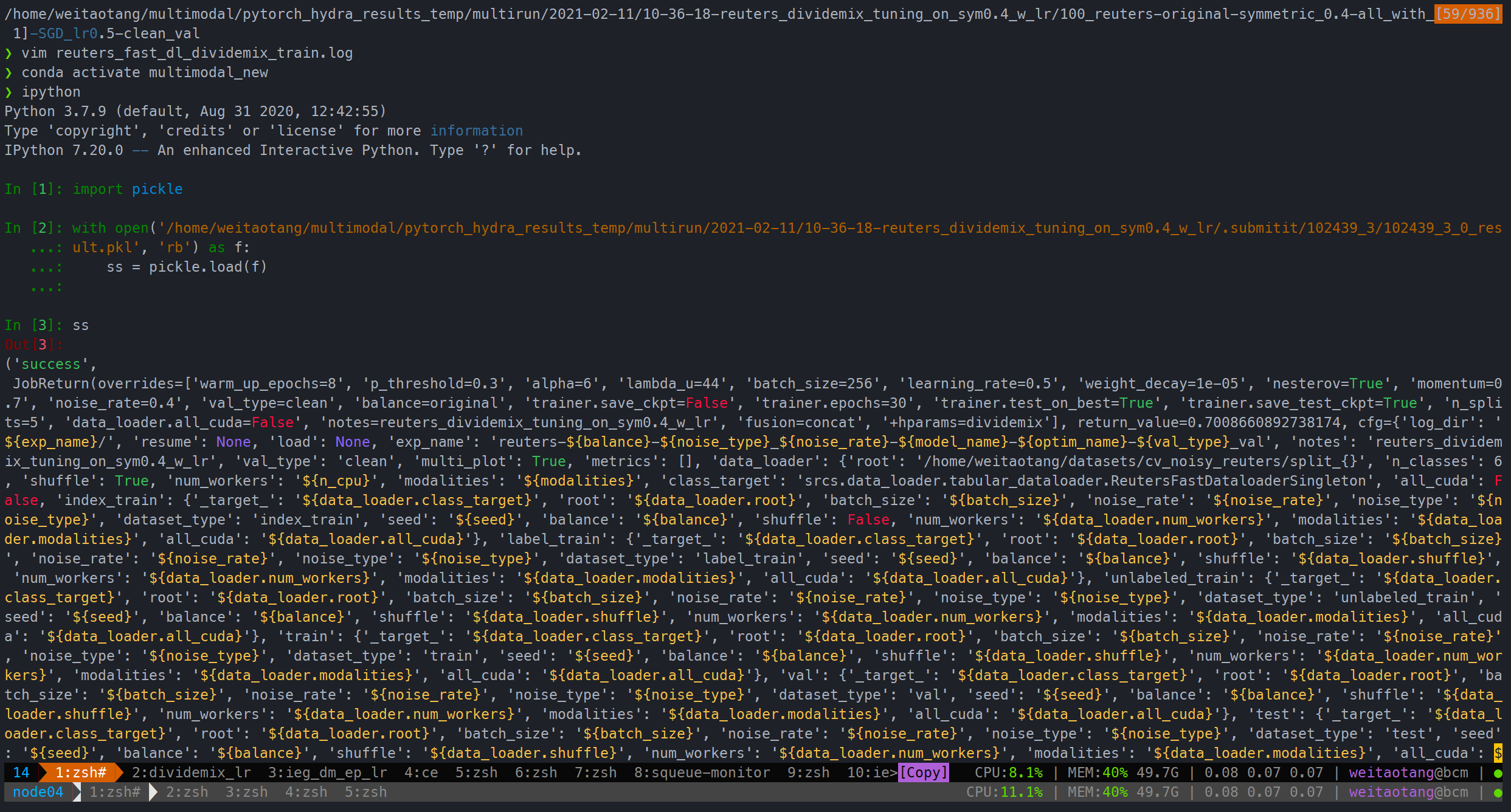
解决方法只能手动把这个阈值提高,从原来的15变为60
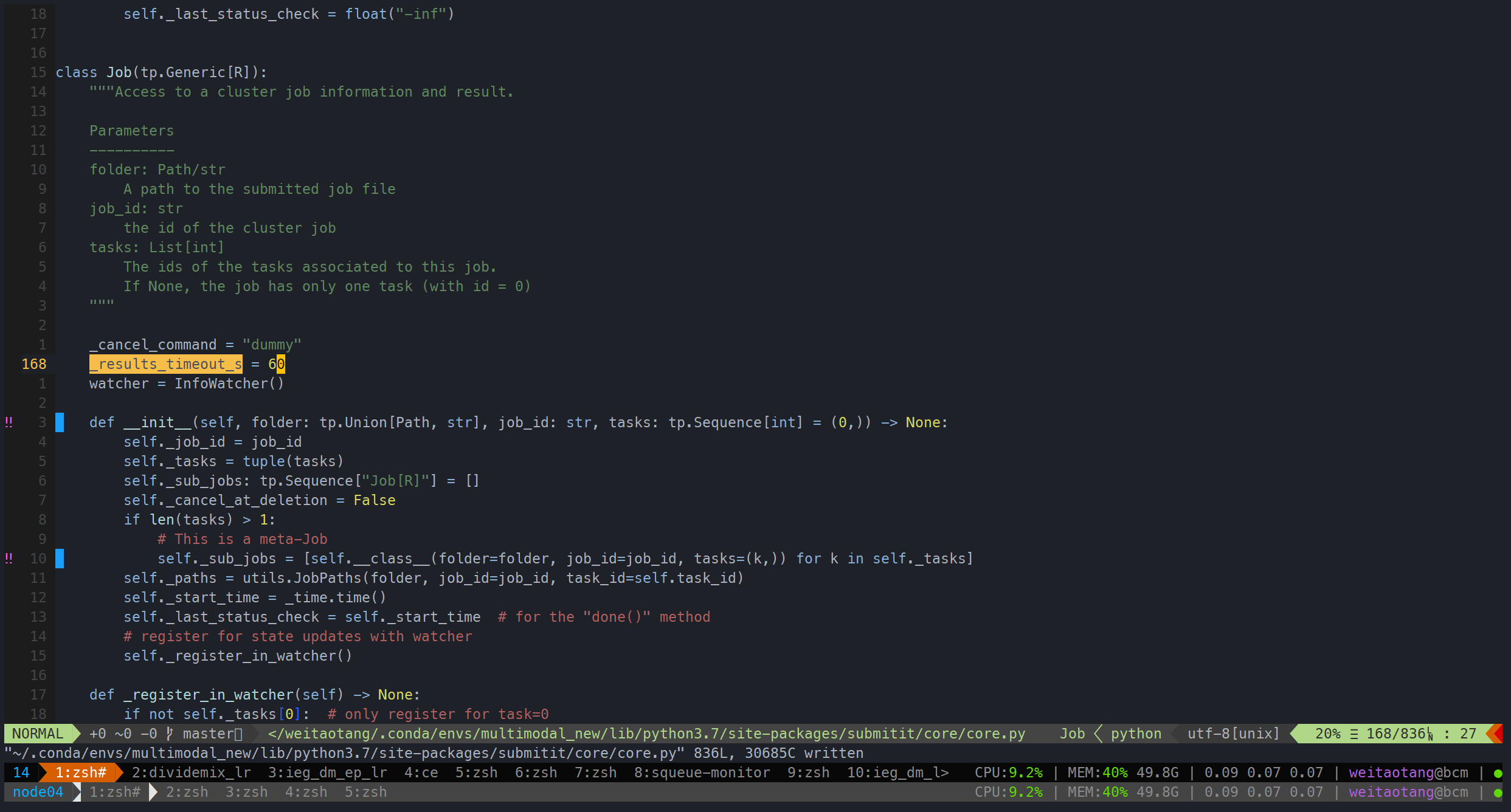
如果本次任务是optuna tuning,可以直接用会上一次的study,基本上能够保证出来的参数是上一次未完成的实验
ravdess num_workers尝试
从2-16都试了一次
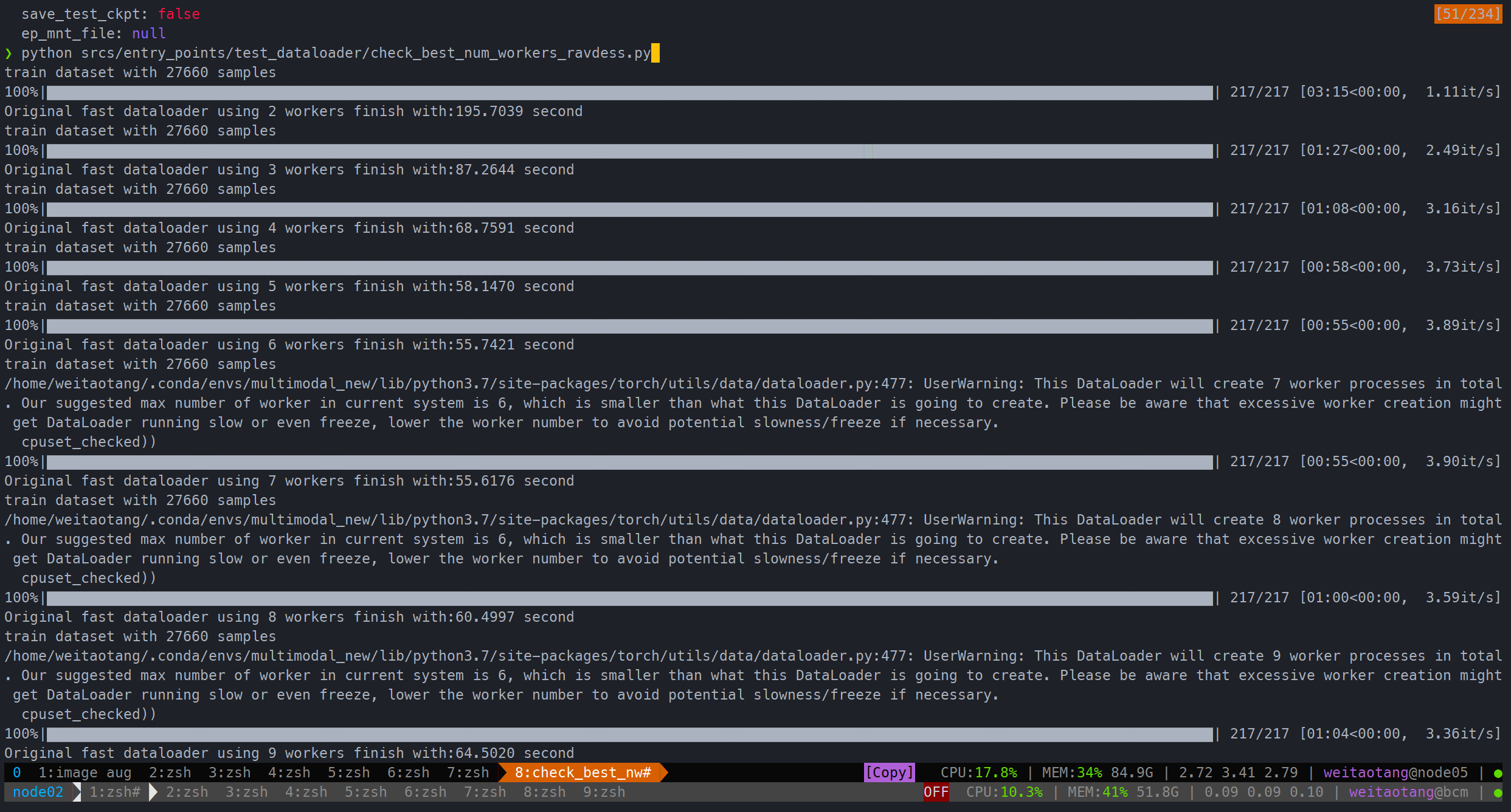
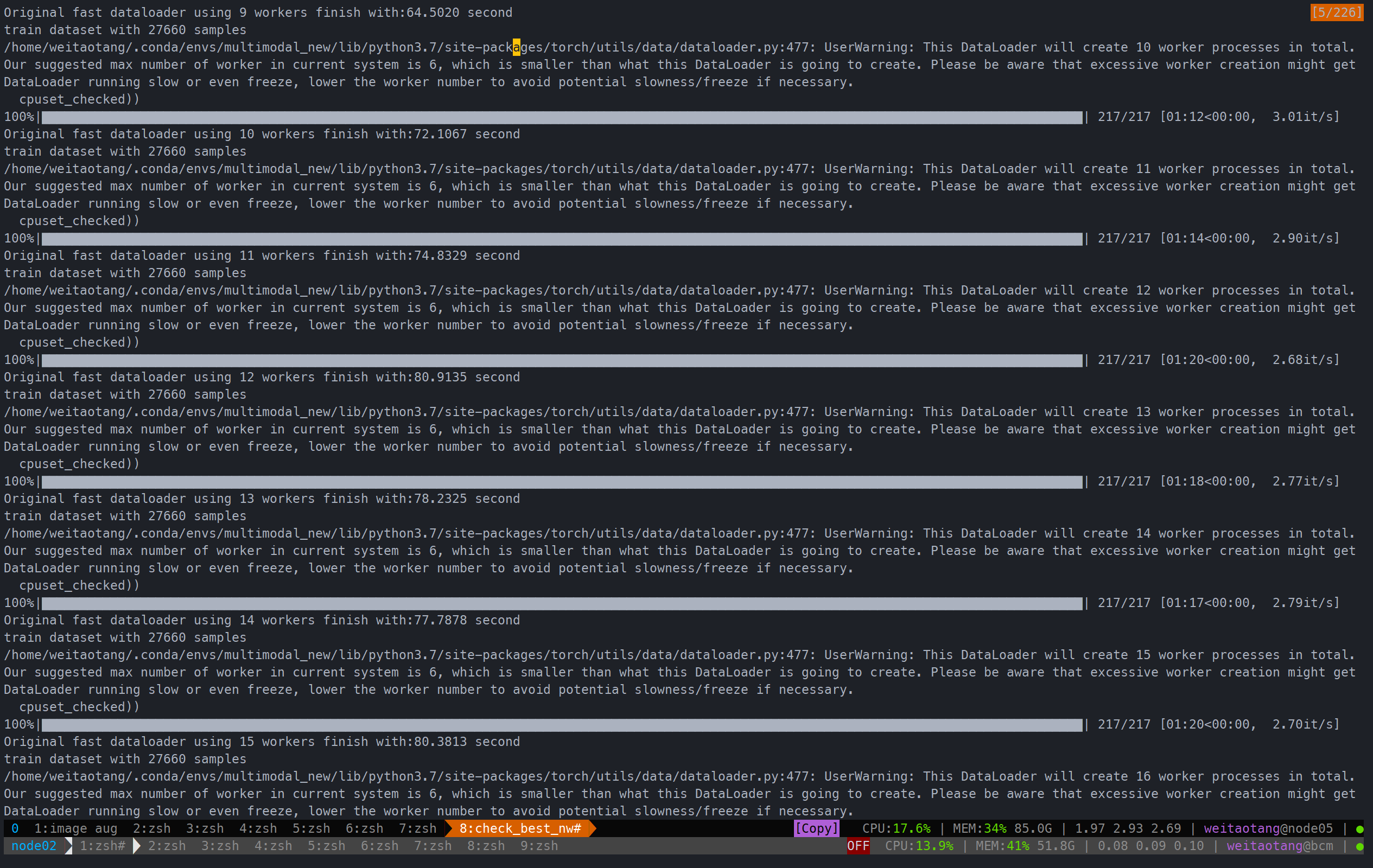
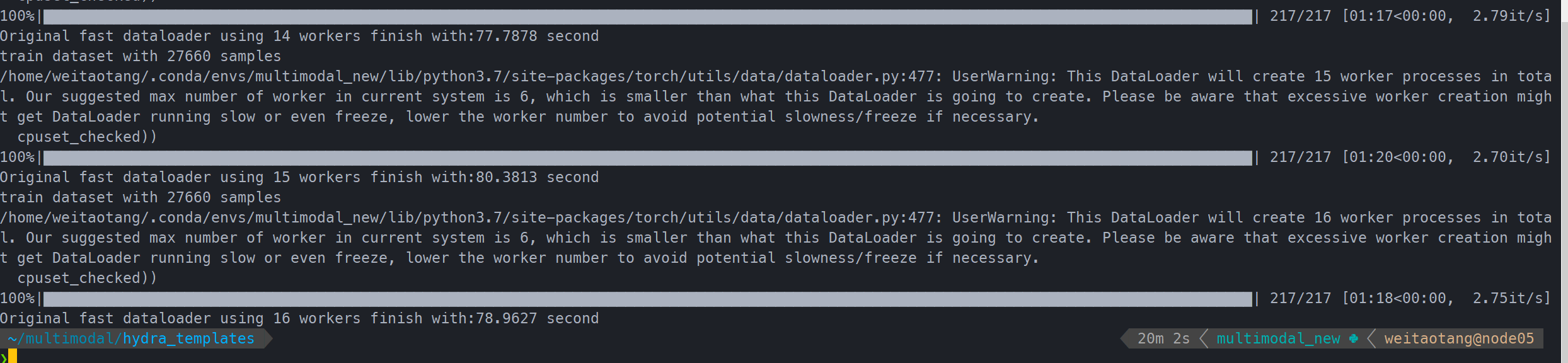
可以看到
- 能够比原来200s+提速很多,约4倍
- 在6-7的时候就差不多了
- 默认最大不应该超过6,因此设为6就够了
ravdess apex尝试
- 在ieg上进行尝试
- 由于实现问题,暂时无法优化meta optimize部分,所以实际上提速效果不是非常明显。显存占用只缩小了一点点(21000+ -> 19000+)
耗时几乎没变化:
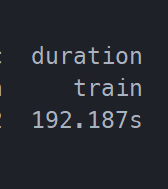
开启AMP前:
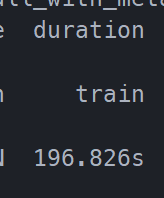
开启AMP后:
ravdess 相关论文所使用模型的调研
https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8644168
audio:仅仅使用MFCC 然后直接用一个LMT,没有用到visual feature
https://www.mdpi.com/1424-8220/20/1/183
同样是仅仅只使用audio的feature
we evaluated our SER model on IEMOCAP and RAVDESS datasets using
spectrograms. The performance of the proposed CNN models compares with recent CNNs architectures
for SER using spectrograms.
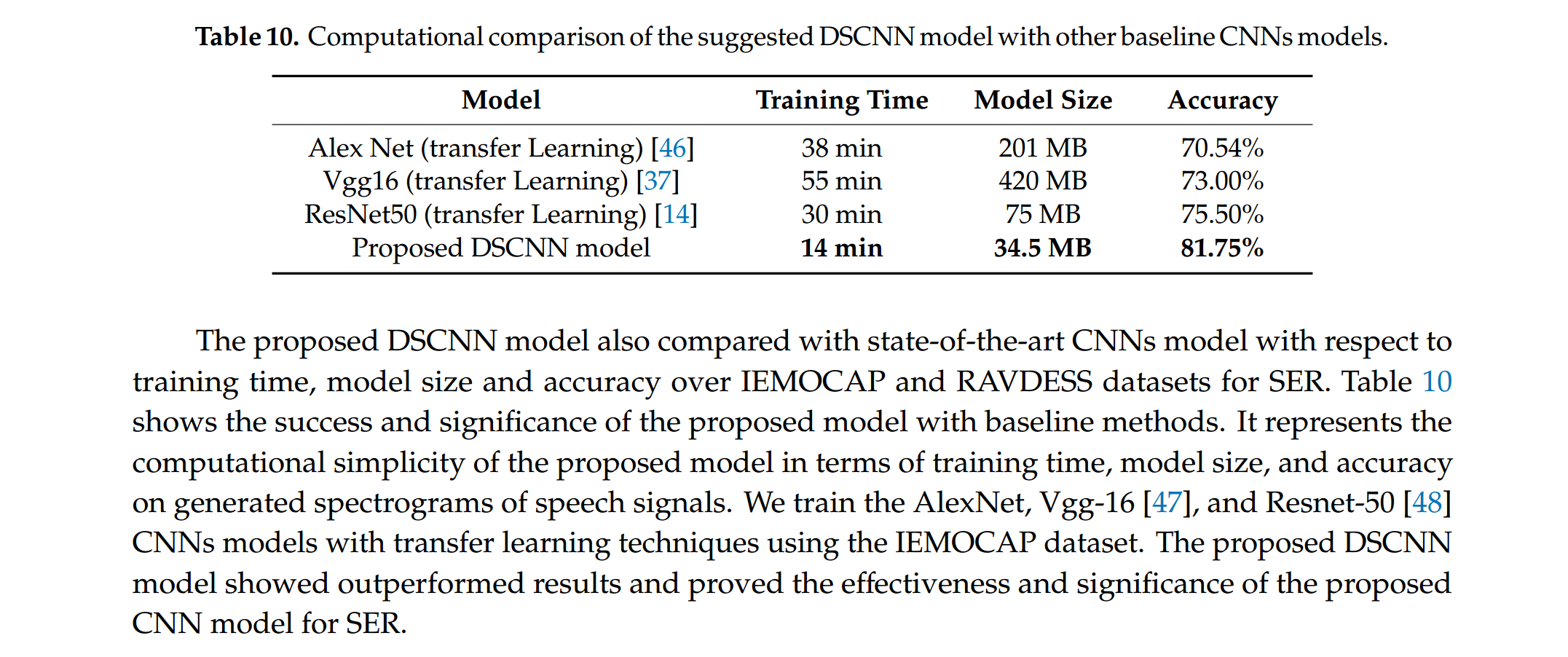
并且也在其中进行了比较,可以看到resnet50是很正常的
https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8925444
用LSTM multimodal
https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8682553
类似transfer learning
ravdess训练太慢:可能解决方法:transfer learning?
参考:
https://pytorch.org/tutorials/beginner/transfer_learning_tutorial.html#convnet-as-fixed-feature-extractor 官方的CNN transfer learning, 只train最后的FC layer
https://www.kaggle.com/pmigdal/transfer-learning-with-resnet-50-in-pytorch 同样只train最后的FC layer
https://balajikulkarni.medium.com/transfer-learning-using-resnet-e20598314427 提到了BN也要变成trainable,因为BN本质上是和数据集相关的,因此要让BN被训练
https://medium.com/@kenneth.ca95/a-guide-to-transfer-learning-with-keras-using-resnet50-a81a4a28084b 除了FC,resnet50的最后一个block也是trainable的
https://keras.io/api/applications/ keras 官方教程。里面对于inceptionv3的使用:同样是把前面部分的inception block冻结,后面的训练,从而减少参数,这个即fine tuning
# we chose to train the top 2 inception blocks, i.e. we will freeze # the first 249 layers and unfreeze the rest: for layer in model.layers[:249]: layer.trainable = False for layer in model.layers[249:]: layer.trainable = True
https://thedatafrog.com/en/articles/image-recognition-transfer-learning/ 非常详细的VGG16 fine tuning的教程,同样也是冻结前面所有层
hydra + basic local launcher 使用单例模式时要注意的点
在multirun的模式下,使用basic Launcher自动执行不同的参数时,要注意每次执行并没有重开一个新的进程,而仅仅是按照不同的参数重新执行一次main函数,即上一次run的数据并为完全消除,如果此时单例模式中所使用的key又没注意,比如下面这种不够区分度的:

会导致后面的run都会重复使用第一个run的参数,导致执行失败。
因此最佳的方法还是把所有的args都拼接起来,作为key
