linux使用基础
软连接
创建软连接: ln -s <source> <symbolic link>
删除软连接: rm/unlink <symbolic link>
参考:
How to Remove Symbolic Link in Linux with Example
软连接、硬链接的区别
参考:
linux中的文件都分成两部分:user data, meta data
文件的inode号才是linux系统查找文件用的。
在 Linux 中,元数据中的 inode 号(inode 是文件元数据的一部分但其并不包含文件名,inode 号即索引节点号)才是文件的唯一标识而非文件名。文件名仅是为了方便人们的记忆和使用,系统或程序通过 inode 号寻找正确的文件数据块。
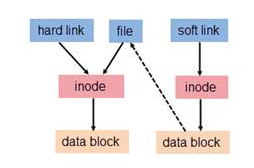
硬链接:若一个 inode 号对应多个文件名,则称这些文件为硬链接。换言之,硬链接就是同一个文件使用了多个别名。硬链接可由命令 link 或 ln 创建。其特点是:
- 文件有相同的 inode 及 data block
- 删除一个硬链接文件并不影响其他有相同 inode 号的文件
- 只能对已存在的文件进行创建
- 不能对目录进行创建,只可对文件创建
软链接:软链接与硬链接不同,若文件用户数据块(user data)中存放的内容是另一文件的路径名的指向,则该文件就是软连接。软链接就是一个普通文件,只是数据块内容有点特殊。
需要注意的是,软链接打开后,文件/文件夹的路径名并不是原来的那个,而是会变成新的(软链接自己的)
二者的联系可用下图表示:
tcgetattr: Invalid argument 的解决:取消pseudo-terminal
why is the tcgetattr error seen when ssh is used for dumping the backup file on another server?
The
tcgetattrfunction is used to look up the attributes of the pseudoterminal represented by a file descriptor; it takes a file descriptor and a pointer to a termios structure to store the terminal metadata in.
srun时取消--pty选项即可
查看、杀死进程
查看
htop -u user进入后用kill杀死ps -u [username]ps -ef | grep <username>
杀死
- htop中直接杀死
killall --user杀死所有用户进程kill [pid]
查看端口
查看进程占用端口
netstat -nap | grep <pid>查看端口占用
netstat -ntlp //查看当前所有tcp端口
netstat -ntulp | grep 80 //查看所有80端口使用情况
netstat -ntulp | grep 3306 //查看所有3306端口使用情况查看当前系统的版本号
cat /etc/os-releasedos2unix批量转换,解决^M问题
使用很简单,直接按照文中方法即可:
find public/components/ -name "*" | xargs dos2unixfind . -type f -print0 | xargs -0 dos2unix -f压缩,解压
.tar
解包:tar xvf FileName.tar
打包:tar cvf FileName.tar DirName
(注:tar是打包,不是压缩!)
tar解压到指定文件夹:要求 /path/to/dir存在,因此要提前用 mkdir创建好
tar -xvf FileName.tar -C /path/to/dirtar -xf FileName.tar -C /path/to/dir.gz
解压1:
gunzip FileName.gz解压2:
gzip -d FileName.gz压缩:
gzip FileName.tar.gz
解压:
tar zxvf FileName.tar.gz压缩:
tar zcvf FileName.tar.gz DirName.bz2
解压1:bzip2 -d FileName.bz2
解压2:bunzip2 FileName.bz2
压缩: bzip2 -z FileName
.tar.bz2
解压:tar jxvf FileName.tar.bz2
压缩:tar jcvf FileName.tar.bz2 DirName
.bz
解压1:bzip2 -d FileName.bz
解压2:bunzip2 FileName.bz
压缩:未知
.tar.bz
解压:tar jxvf FileName.tar.bz
压缩:未知
.Z
解压:uncompress FileName.Z
压缩:compress FileName
.tar.Z
解压:tar Zxvf FileName.tar.Z
压缩:tar Zcvf FileName.tar.Z DirName
.tgz
解压:
1 gunzip FileName.tgz | jar xvf FileName.tar
2 tar zxvf test.tgz -C path
压缩:
tar zxvf FileName.tgz
tar czvf FileName.tgz path
.tar.tgz
解压:tar zxvf FileName.tar.tgz
压缩:tar zcvf FileName.tar.tgz FileName
.zip
解压:unzip FileName.zip
压缩:zip FileName.zip DirName
.rar
解压:rar a FileName.rar
压缩:rar e FileName.rar
.lha
解压:lha -e FileName.lha
压缩:lha -a FileName.lha FileName
查看文件夹大小
Linux中查看各文件夹大小命令du -h –max-depth=1
du [-abcDhHklmsSx] [-L <符号连接>][-X <文件>][–block-size][–exclude=<目录或文件>] [–max-depth=<目录层数>][–help][–version][目录或文件]
常用参数:
-a或-all 为每个指定文件显示磁盘使用情况,或者为目录中每个文件显示各自磁盘使用情况。
-b或-bytes 显示目录或文件大小时,以byte为单位。
-c或–total 除了显示目录或文件的大小外,同时也显示所有目录或文件的总和。
-D或–dereference-args 显示指定符号连接的源文件大小。
-h或–human-readable 以K,M,G为单位,提高信息的可读性。
-H或–si 与-h参数相同,但是K,M,G是以1000为换算单位,而不是以1024为换算单位。
-k或–kilobytes 以1024 bytes为单位。
-l或–count-links 重复计算硬件连接的文件。
-L<符号连接>或–dereference<符号连接> 显示选项中所指定符号连接的源文件大小。
-m或–megabytes 以1MB为单位。
-s或–summarize 仅显示总计,即当前目录的大小。
-S或–separate-dirs 显示每个目录的大小时,并不含其子目录的大小。
-x或–one-file-xystem 以一开始处理时的文件系统为准,若遇上其它不同的文件系统目录则略过。
-X<文件>或–exclude-from=<文件> 在<文件>指定目录或文件。
–exclude=<目录或文件> 略过指定的目录或文件。
–max-depth=<目录层数> 超过指定层数的目录后,予以忽略。
–help 显示帮助。
–version 显示版本信息。
按照分目录的形式查看当前目录的大小:
du -h .总览整个文件夹的大小
du -sh .按照M查看文件大小
Linux查看文件大小的几种方法
linux下以M为单位显示文件大小
ls -lhls -l --block-size=Mpip.conf的位置
~/.pip/pip.conf~/.config/pip/pip.conf
安装FUSE的方法:
apt-get install kmodapt-get install fusemodprobe -v fuse
sed中的单引号使用
- 首先要注意 同一条命令中不能有空格
- 其次要注意如引用所说的,需要在外面单独转义,如
sed -i '$a alias nvim='\''/root/squashfs-root/usr/bin/nvim -u /root/.SpaceVim/init.vim'\' /root/.bashrc获取文件夹中文件数量
- 获取文件数量
find folder/* -type f | wc -l - 获取文件夹数量
find folder/* -type d | wc -l
统计文件行数
wc -l test1.txtawk '{print NR}' test1.txt | tail -n1docker中用pip安装neovim可能出现的问题
...
Couldn't find index page for pytest-runner
...因此手动安装pytest-runner就好了
pip instal pytest-runnerERROR: Could not install package due to an EnvironmentErropir更改文件所有者
参考
如何更改linux文件的拥有者及用户组(chown和chgrp)
-R表示迭代
chown [-R] 账号名称 文件或目录
chown [-R] 账号名称:用户组名称 文件或目录统计当前目录下文件的个数
统计当前目录下文件的个数(不包括目录)
ll | grep "^-" | wc -l统计当前目录下文件的个数(包括子目录)
ll -R | grep "^-" | wc -l查看某目录下文件夹(目录)的个数(包括子目录)
ll -R | grep "^d" | wc -l命令解析
ll长列表输出该目录下文件信息(注意这里的文件是指目录、链接、设备文件等),每一行对应一个文件或目录,ll -R 是列出所有文件,包括子目录。
grep "^-"过滤ll的输出信息,只保留一般文件,只保留目录是grep "^d"。
wc -l统计输出信息的行数,统计结果就是输出信息的行数,一行信息对应一个文件,所以就是文件的个数。
linux的通配符
“*”:匹配任意字符串,包括空字符串,不包含对“/”字符的匹配。
“?”:匹配任意单个字符,不能匹配“/”字符。
“[abc]”:匹配“a”或者“b”或者“c”字符。
“[!abc]”:匹配除了“a,b,c”这3个字符之外的任意一个字符。不包含对“/”字符的匹配。
linux解压zip分卷文件
例如linux.zip.001, linux.zip.002, linux.zip.003…
首先 cat linux.zip* > linux.zip #合并为一个zip包
然后 unzip linux.zip #解压zip包
linux解压rar分卷文件
用unrar命令
直接解压分卷文件
解压到当前文件夹下的images子文件夹
unrar x images.part01.rar ./images测试分卷文件是否损坏:
unrar t images.part01.rargrep使用
正则匹配
三种正则模式,最好还是用P(erl)的,因为支持的功能最多
普通的正则匹配: -n
不包含\d+的通配符,因此下面的语句并不正确
grep -n 'user=12:\d+\t' logs/output_ORACLE_log_hdfs正确的是:
grep -n 'user=12:[0-9]+\t' logs/output_ORACLE_log_hdfsPerl的正则匹配:-P
包含了\d+等
grep -P 'user=12:\d+' logs/output_ORACLE_log_hdfsExtend正则匹配: -E
同样也支持\d+等
只提取正则匹配的部分:-o
grep -P -o 'user=12:\d+' logs/output_ORACLE_log_hdfs | head -10 
根据正则匹配提取部分子串:(?<=prefix_pattern)extracted_string(?=sufix_pattern)
参考: How extract under linux some capturing groups using command line in a php/preg fashion?
GNU
grepsupports a-P(if built with perl compatible regex support) and-o. However its-ois limited to printing the whole matched portions. You can however use perl look-around operators to work around that:grep -iPo '(?<=something=")\w+(?=")' myfile.txt(that is, a regexp that matches sequence of word component characters provided it follows
something="and is followed by").
输入:

只提取user=12:之后的数字:
grep -oP '(?<=user=12:)\d+' logs/output_ORACLE_log_hdfs | head -10 
sed使用
用替换的思路提取正则匹配的部分字符串
How to use grep to extract multiple groups
In the meanwhile, I would use
sed:sed -r 's/^a=([0-9]+).*c=([0-9]+)$/\1 \2/' fileit catches the digits after
a=andc=, whenever this happens on lines starting witha=and not containing anything else afterc=digits.
提取字符串
echo here365test | sed 's/.*ere\([0-9]*\).*/\1/g' 1输出:
365 1s表示替换,\1表示用第一个括号里面的内容替换整个字符串,sed支持*,不支持?、+,不能用\d之类,正则支持有限。
按行输出某一个文本的范围
How can I extract a predetermined range of lines from a text file on Unix?
sed -n '14, 47p;48q' sampled_0.1_group_source_20200524_16.logls(hdfs dfs -ls)正则筛选在一个集合内的字符{}
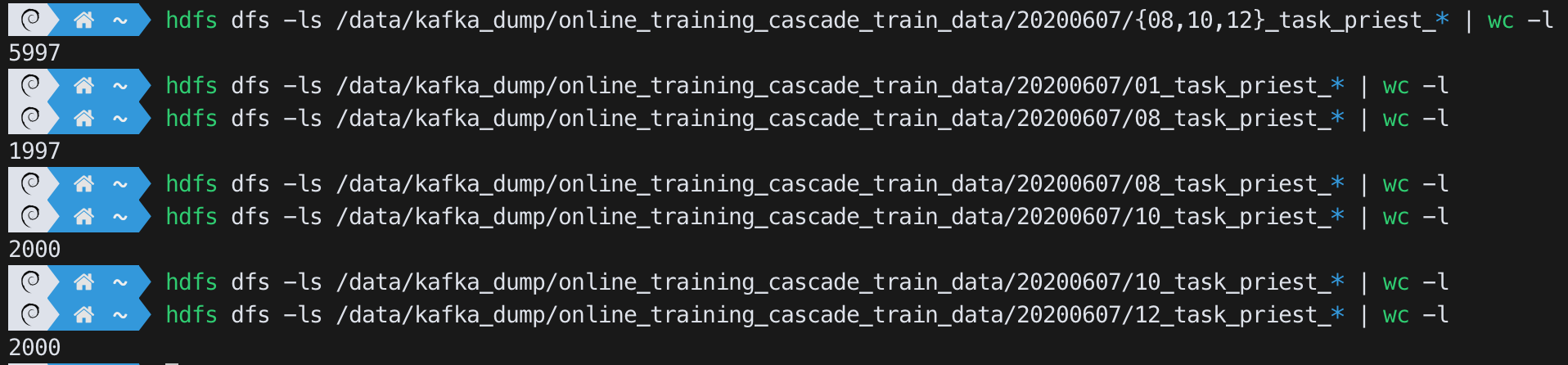
How to use regex to include/exclude some input files in sc.textFile?
解决 device or resource busy
How to get over “device or resource busy”?
# 找出正在占用文件的进程PID
lsof +D /path
# kill
kill -9nautilus彻底清空trash
rm -rf ~/.local/share/Trash