DGL使用基础
Builtin message passing functions
message function只能用在arguments里面明确指出了
message_func的函数中,因此若把一个builtin message function作为apply_node的arguments会报错:func = fn.u_add_v('nf','t','e') g.apply_nodes(func)--------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-16-629bfb5541ce> in <module> ----> 1 g.apply_nodes(func) ~/.conda/envs/ptpy_3/lib/python3.6/site-packages/dgl/graph.py in apply_nodes(self, func, v, inplace) 2094 apply_func=func, 2095 inplace=inplace) -> 2096 Runtime.run(prog) 2097 2098 def apply_edges(self, func="default", edges=ALL, inplace=False): ~/.conda/envs/ptpy_3/lib/python3.6/site-packages/dgl/runtime/runtime.py in run(prog) 9 for exe in prog.execs: 10 # prog.pprint_exe(exe) ---> 11 exe.run() ~/.conda/envs/ptpy_3/lib/python3.6/site-packages/dgl/runtime/ir/executor.py in run(self) 127 node_data = self.fdnode.data 128 if self.fdmail is None: --> 129 udf_ret = fn_data(node_data) 130 else: 131 mail_data = self.fdmail.data ~/.conda/envs/ptpy_3/lib/python3.6/site-packages/dgl/runtime/scheduler.py in _afunc_wrapper(node_data) 267 def _afunc_wrapper(node_data): 268 nbatch = NodeBatch(graph, v, node_data) --> 269 return apply_func(nbatch) 270 afunc = var.FUNC(_afunc_wrapper) 271 applied_feat = ir.NODE_UDF(afunc, v_nf) TypeError: 'BinaryMessageFunction' object is not callable使用builtin message function要注意dtype,如果是
torch.int64会报错,但是torch.float32就不会(如u_add_v)
src与dst的理解
u 代表source,v代表destination。直接用g.edges()查看,第一个向量对应u,第二个向量对应v(因为默认添加edge的时候是按照(u,v)的顺序添加,即从tuple中左边的node为source,右边的是destination
binary operation的arguments中的
lfs fieldrhs field指的是那个符号(比如add,div,mul两边分别是什么,比如u_add_v指的是左边lfs field对应的是source,rhs field对应的是destinations。反过来v_add_u则指的是lfs field对应destinations,rhs field对应的是source同理
u_add_e与e_add_u的理解,但要注意的是,这里面lfs field与rhs field不能随便互换,因为node features和edge features的维度一般不一样
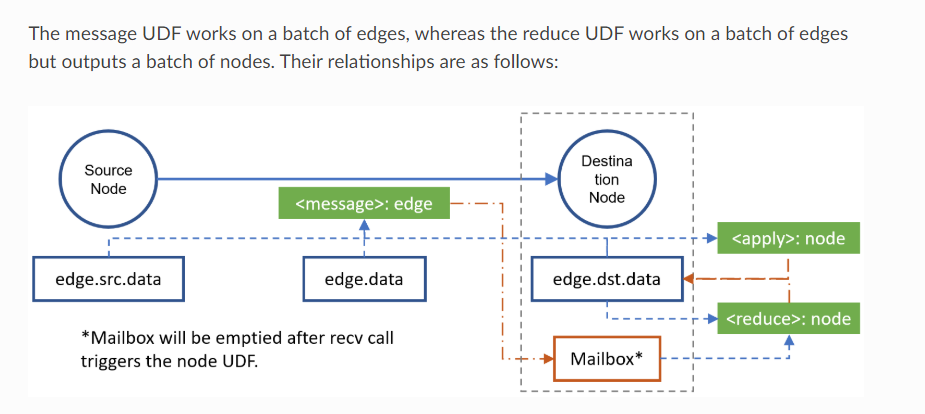
send与recv机制的理解
send需要一个message passing function(如u_add_v), recv需要一个reduce function(如sum)。前者直接输出到mailbox中(既不在edata也不再ndata,无法直接访问),后者则直接输出到ndata中。
mailbox 是储存在nodes的里面,使用完send之后是没办法直接直接访问mailbox的,必须用recv()再输出到ndata中
update_all相当于把以上两个步骤合二为一,直接传入两个func即可。
Node UDF, Edge UDF的理解
- 通常
message_func要求Edge UDF(即参数为EdgeBatch),reduce_func为Node UDF(参数为NodeBatch)
message_func(Edge UDF)
- 参数
EdgeBatch是包含 该graph全部edges的batch,因此只会执行一次 EdgeBatch.src是用graph.edges()[0]对应nodes得到的,EdgeBatch.dst是用graph.edges()[0]对应nodes得到的,他们各自包含对应顺序的data
reduce_func(Node UDF)
nodes.mailbox中的data为$N_{nodes} \times M_{dst}$ or $N \times \times M_{dst} \times dim_1 \times dim_2 \times … \times dim_k$, 其中$N_{nodes}$ 表示的是这个node batch中所包含的节点数,$M_{dst}$表示那个node 在EdgeBatch.dst中对应edge的message,即首先得到graph.edges[1] 该节点所对应的edges idx,然后用这个index list去获得对应的edge的message(经自定义的message_func或builtin),最后抽出来作为这个node的message,并在最前面添加一个维度以便collate一个node batch中每个node的degree应该是一样的
nodes.mailbox生成的思路是:
**按照degree或者在dst index(graph.edges()[1])中出现的顺序,把可能同degree的nodes抽出来作为一个batch,每个node的message的维度若是$M_{dst}$ (表示每条edge的message为一个scalar) 或者$M_{dst} \times dim_1 \times dim_2 \times … \times dim_k$**,
再在 最前面加一个维度,并collate成$N_{nodes} \times M_{dst}$ or $N \times \times M_{dst} \times dim_1 \times dim_2 \times … \times dim_k$
把collate好的tensor输入到mailbox中对应的位置。
reduce_func需要做的是 把 $N_{nodes} \times M_{dst}$ 或者 $N \times \times M_{dst} \times dim_1 \times dim_2 \times … \times dim_k$ 转化为 $N \times dim_{output}$ 的数据。需要注意mailbox中message,第一个维度对应这个NodeBatch中的nodes index,第二个维度对应以该node为dst的edge的另一个节点,之后才是各条edge的对应的message
当最后的结果为一个scalar的时候,也要保留一个维度, 即$N$,可通过
unsqueeze()实现。如下面的例子sum 不能把dim留空,否则报错,至少要有一个维度。:
def self_d_rduc(nodes): print('Nodes data:{}'.format(nodes.data)) print('Message:{}'.format(nodes.mailbox['m'])) r_msg = nodes.mailbox['m'].sum(-1) print('Output_message: {}'.format(r_msg)) return {'m_out':r_msg} g.recv(reduce_func=self_d_rduc)Nodes data:<dgl.utils.LazyDict object at 0x7fff2b8c5a58> Message:tensor([[ 182., 362., 542., 902., 1082., 1262., 1442., 1622.]]) Output_message: tensor([7396.])
dgl._ffi.base.DGLError:输入的点必须连续
从networkx graph生成的时候,**需要把原来不连续的node index变成连续的,从0开始的,为此需要做一个mapping(nx.relabel_nodes or `nx.convert_node_labels_to_integers)**,推荐后者,因为还可以把 原来的nodes index放到nx graph的nodes attributes中
把模型转移到gpu:.to(torch.device('cuda'))
直接DGLGraph.to(torch.device('cuda'))即可
Multi GPU训练:应该用Distributed
参考:
上面分别有两个例子,以及下面Pytorch官方的Distributed Training的教程
When will multi-gpu be supported
WRITING DISTRIBUTED APPLICATIONS WITH PYTORCH
batch的方法
参考:
直接使用pytorch的Dataloader,再加上自己写的collate function即可。