pytorch的基本操作
tensor转化为list
tensor.tolist即可。如果是一个scalar,则用tensor.item().
dilation的含义
参考:
查看梯度
用hook
参考:
how-to-print-models-parameters-with-its-name-and-requires-grad-value
先获取各层的parameter,然后逐层register_hook。
关键在于named_paramters(),这个能够返回各层参数的name。.paramters只能返回一个不带对应name的parameter generator。
def hook(grad, param_name): logger.debug('Paramter:{} | \n grad:{} '.format(param_name, grad.sum())) handle = [] for i, (name, param) in enumerate(model.named_parameters()): if param.requires_grad: def b_h(grad): return hook(grad, name) h = param.register_hook(b_h) handle.append(h) logger.debug('{} param needs grad'.format(i))
NLLLoss与CrossEntropyLoss
NLLLoss
输入应该是log softmax 的 $N \times C$ 的矩阵(或者更多),target应该是non one hot(categorical)的$N$维向量。
weight默认为none,即默认所有类的weight都是1,注意这里所指的weight不需要sum为1,因为最后求mean的时候回把weight.sum()作为分母。但若自己设定,则必须为$C$ 维的向量,每一个element对应那个类的weight,然后对应的weight会直接作用到对应位置的log prob上(直接相乘)。
a = torch.tensor([[1,2,3], [4,5,6], [7,8,9]], dtype=torch.float32) target = torch.tensor([0,1,2]) log_prob = F.log_softmax(a, 1) criterion = nn.NLLLoss(weight=torch.tensor([0.2, 0.4, 1], dtype=torch.float32) ,reduction = 'none') log_prob >>>tensor([[-2.4076, -1.4076, -0.4076], [-2.4076, -1.4076, -0.4076], [-2.4076, -1.4076, -0.4076]]) loss = criterion(log_prob, target) loss >>>tensor([0.4815, 0.5630, 0.4076])如果reduction为none,则输出应该是对应位置的-log prob(即变回正数),最小化这个正数,让其趋近于0,等价于让原来对应位置的prob趋近于1
如果reduction为mean,weight为none,则直接求mean。否则还要除于weight的和,然后在把weighted negative log loss加起来。
直接sum的话就是直接加起来
巧用
虽然要求的输入是log softmax的结果,但是 本质上就只是把input上target对应位置的量抽出来,然后添加负号,最后根据reduction得到最后的loss,因此下面的两段本质是一样的:
criterion = nn.NLLLoss(reduction='sum')
loss = criterion(logits[mask_selected_true], eval_label_rm[mask_selected_true])one_hot_eval_label = make_one_hot(eval_label_rm, num_class)
loss = -torch.mul(logits, one_hot_eval_label).sum(dim=1)[mask_selected_true]测试默认的reduction选项:
(loss / (0.2+.4+1)).sum()
>>>tensor(0.9076)
c2 = nn.NLLLoss(weight=torch.tensor([0.2, 0.4, 1], dtype=torch.float32))
l2 = c2(log_prob, target)
l2
>>>tensor(0.9076)CrossEntropyLoss
本质只是把log_softmax 和 NLLoss结合,参数的设置包括性质都和和NLLoss是一样的。只是输入可以直接输入logits
a = torch.tensor([[1,2,3], [4,5,6], [7,8,9]], dtype=torch.float32) target = torch.tensor([0,1,2]) log_prob = F.log_softmax(a, 1) criterion = nn.CrossEntropyLoss(weight=torch.tensor([0.2, 0.4, 1]), reduction = 'none') log_prob >>>tensor([[-2.4076, -1.4076, -0.4076], [-2.4076, -1.4076, -0.4076], [-2.4076, -1.4076, -0.4076]]) loss=criterion(a, target) loss >>>tensor([0.4815, 0.5630, 0.4076])默认的reduction选项和NLLoss的一样:
c2 = nn.CrossEntropyLoss(weight=torch.tensor([0.2, 0.4, 1], dtype=torch.float32)) l2 = c2(a, target) l2 >>>tensor(0.9076)
乘法
element-wise相乘:
torch.mul()ortorch.Tensor.mul()vector:
torch.matmul()ortorch.mul()matrix:
torch.matmul()带broadcasttorch.mm()ortorch.Tensor.mm()不带broadcasttorch.bmm()ortorch.Tensor.bmm()batch 的不带broadcast
torch.where() / torch.Tensor.where()
torch.where(condition, input, other)
- condition, input, other 可以不同size,只要可以broadcast就行了
- input if condition else other
获取idx: torch.nonzero
但是要记得squeeze(),因为最后获得的是和原来一样size的tensor
获得validation(切分dataset)
random_split
- 但是可能会导致数据不平衡
SubsetRandomSampler
- 需要自己重构
- 配合sklearn的StratifiedShuffleSplit
自己实现
- 配合sklearn的StratifiedShuffleSplit和StratifiedKFold参考 how-do-i-split-a-custom-dataset-into-training-and-test-datasets思路,因为StratifiedShuffleSplit只能得到两个set(train 和 test),因此可以通过split两次来得到三个balanced的set(即对train set再split一次)
torchvision中的transform
- 如果不用
transforms.Compose来把好几个transform拼接起来,则需要按照由class得到instance的方法先得到对应transform的instance,然后再使用。 - 除了
transforms.ToTensor()可以直接作用再ndarray上,其余很对均要求输入的PIL格式的image,如RandomCrop,RandomHorizontalFilp,Normalize等。
Dataloader同时输出batch 对应的index
通过更改Dataset的__getitem__
参考:
How to retrieve the sample indices of a mini-batch
from torchvision import datasets, transforms
from torch.utils.data import Dataset, DataLoader
class MyDataset(Dataset):
def __init__(self):
self.cifar10 = datasets.CIFAR10(root='YOUR_PATH',
download=False,
train=True,
transform=transforms.ToTensor())
def __getitem__(self, index):
data, target = self.cifar10[index]
# Your transformations here (or set it in CIFAR10)
return data, target, index
def __len__(self):
return len(self.cifar10)
dataset = MyDataset()
loader = DataLoader(dataset,
batch_size=1,
shuffle=True,
num_workers=1)
for batch_idx, (data, target, idx) in enumerate(loader):
print('Batch idx {}, dataset index {}'.format(
batch_idx, idx))
Infinite Dataloader
参考:
implementing-an-infinite-loop-dataset-dataloader-in-pytorch
本质上Dataloader输出的就是一个iterable的object,因此可以通过iter() + next() 来实现无限循环
但是更佳的方式是IterableDataset,但是这个Dataset就没有shuffle等内容,需要自己控制。**注意一定要重载
__iter__**,为实现infinite也是通过重载这个实现的,每一个epoch只会得到一个iterator。class FakeIterableDataset(IterableDataset): def __init__(self, data): self.data = data self.count = 0 def __iter__(self): print('Count:{}'.format(self.count)) self.count+=1 return iter(torch.cat([self.data, self.data])) fake_dataset = FakeIterableDataset(torch.arange(10)) ld = DataLoader(fake_dataset, batch_size=3) for item in ld: print(item)Count:0 tensor([0, 1, 2]) tensor([3, 4, 5]) tensor([6, 7, 8]) tensor([9, 0, 1]) tensor([2, 3, 4]) tensor([5, 6, 7]) tensor([8, 9])
当Dataset.__getitem__返回一个dict时
返回tuple的时候很好理解, batch就是等于zip起来
而当Dataset的
__getitem__返回dict的时候,则是返回一个dict,dict的key一样,只是value变成batch,而不是多个dictclass FakeDataset(Dataset): def __init__(self, data): self.data = data def __len__(self): return len(self.data) def __getitem__(self, index): return {'idx':index, 'data':self.data[index]*10} fake_dataset = FakeDataset(torch.arange(10)) ld = DataLoader(fake_dataset, batch_size=3) for item in ld: print(item){'idx': tensor([0, 1, 2]), 'data': tensor([ 0, 10, 20])} {'idx': tensor([3, 4, 5]), 'data': tensor([30, 40, 50])} {'idx': tensor([6, 7, 8]), 'data': tensor([60, 70, 80])} {'idx': tensor([9]), 'data': tensor([90])}
Softmax的dim
dim参数的作用,就是让 除了该dim以外的dim求和都为1。对于多维的数据$(S_1, S_2, S_3, \cdots, S_n)$,
softmax(dim=i)则等价于$(S_1 \times S_2 \times S_3, \cdots, S_i, \cdots,S_{i+1} \times \cdots \S_n)$ 除了第i维外其余两个维度的任意一个idx,求sum都等于1如一个 (J, K, L)维度的数据,若
softmax(dim=0)则(:, k, l) = 1, k, l为各自维度的index,可以理解为:三位的数据,使得对z轴求和各个数据,结果为1以下为`softmax(dim=)
```python
alpha.shape
Out[27]: torch.Size([10, 10, 2])
alpha[:,1,1]
Out[23]:
tensor([0.0875, 0.0865, 0.0935, 0.1091, 0.1013, 0.1169, 0.1084, 0.0963, 0.0961,
0.1045], grad_fn=)
alpha.view(10, -1).sum(0)
Out[26]:
tensor([1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000,
1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000,
1.0000, 1.0000], grad_fn=) ### 把index转化为对应的boolean array作为mask:直接索引即可 ```python idx = torch.tensor([3, 7, 2]) bool_mask = torch.zeros(10) bool_mask[idx] = 1 bool_mask = bool_mask.bool() bool_mask
tensor([False, False, True, True, False, False, False, True, False, False])获取tensor的device(GPU, CPU均可):tensor.device
参考:
Which device is model / tensor stored on?
cuda_check = my_tensor.is_cuda
if cuda_check:
get_cuda_device = my_tensor.get_device()- 如果是gpu的tensor,则会输出 对应的CUDA编号(如在CUDA:0的tensor则会返回0)
- 如果是cpu的tensor,则默认返回-1
torch.device的用法
直接
torch.device('cuda')等价于得到一个 当前cuda device的objects(有多个gpu时默认是第0个)a
torch.Tensorconstructed with device'cuda'is equivalent to'cuda:X'where X is the result oftorch.cuda.current_device()tensor的device可通过
Tensor.device获得对于cuda来说,以下两种写法都是等价的:
torch.device('cuda:0')torch.device('cuda')推荐用上面的写法,更清晰。
注意,**
torch.cuda.device是一个context -manager, 即需要通过with torch.cuda.device():**来使用(让context内的tensor都在这个cuda上)
pytorch_scatter报错:scatter_cpu undefined symbol: _ZN2at6detail20DynamicCUDAInterface10set_deviceE
原因是因为pytorch升级了,需要重新编译。但是当前还未支持1.3.0,所以需要重新为1.2.0
直接计算KL_divergence:torch.nn.KLDivLoss或者其对应的函数形式
- 注意具体计算的时候,输入的顺序:函数中的 p q 位置相反,即如果要D(p||q),则应该写成kl_div(q.log(),p)的形式,q要用F.log或者F.log_softmax。具体参考pytorch中的kl divergence计算问题
pytorch支持直接通过index逐个赋值
即当 index是一个list的时候,可以通过两边都用同样的list来实现逐个赋值,这个list既可以是离散的list,也可以是
:组成的slicing例子:离散的list,最后的结果的确tt的1,3,4行都改变了:
eval_ema_pred[:10] Out[116]: tensor([[0., 0., 0., 0., 1., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 1., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 1., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 1., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 1., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 1., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 1., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 1., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 1., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 1., 0., 0., 0., 0., 0.]]) tt = train_dataset.labels[:10].clone() tt Out[118]: tensor([[1., 0., 0., 0., 0., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 0., 0., 0., 0., 0., 1.], [0., 0., 0., 0., 0., 1., 0., 0., 0., 0.], [0., 0., 0., 0., 1., 0., 0., 0., 0., 0.], [0., 1., 0., 0., 0., 0., 0., 0., 0., 0.], [0., 0., 0., 1., 0., 0., 0., 0., 0., 0.], [0., 1., 0., 0., 0., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 0., 0., 0., 1., 0., 0.], [0., 0., 0., 0., 0., 0., 0., 0., 1., 0.], [0., 0., 0., 1., 0., 0., 0., 0., 0., 0.]]) tt[[1,3,4]]=eval_ema_pred[[1,3,4]] tt Out[122]: tensor([[1., 0., 0., 0., 0., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 1., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 0., 1., 0., 0., 0., 0.], [0., 0., 0., 0., 1., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 1., 0., 0., 0., 0., 0.], [0., 0., 0., 1., 0., 0., 0., 0., 0., 0.], [0., 1., 0., 0., 0., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 0., 0., 0., 1., 0., 0.], [0., 0., 0., 0., 0., 0., 0., 0., 1., 0.], [0., 0., 0., 1., 0., 0., 0., 0., 0., 0.]])例子:
:组成的slicing,一样可以,eval_ema_pred_2的最后三行的确改变值了:eval_ema_pred_2 = eval_ema_pred.clone() eval_ema_pred_2[-3:] Out[126]: tensor([[0., 0., 0., 0., 1., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 1., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 1., 0., 0., 0., 0., 0.]]) eval_ema_pred_2[-3:] = tt[-3:] eval_ema_pred_2[-3:] Out[129]: tensor([[0., 0., 0., 0., 0., 0., 0., 1., 0., 0.], [0., 0., 0., 0., 0., 0., 0., 0., 1., 0.], [0., 0., 0., 1., 0., 0., 0., 0., 0., 0.]])
learning rate paramter 调整
如下:
def adjust_learning_rate(optimizer, epoch):
"""Sets the learning rate to the initial LR decayed by 10 every 30 epochs"""
lr = args.lr * (0.1 ** (epoch // 30))
for param_group in optimizer.param_groups:
param_group['lr'] = lrReset model
手动初始化所有parameter
可以参考这个:
def weights_init(m):
if isinstance(m, nn.Conv2d):
torch.nn.init.xavier_uniform(m.weight.data, nn.init.calculate_gain('relu'))
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
...
model.apply(weights_init)
直接重建
- 注意:关键在于要保证原来的model的所有reference都被del了,这样model的那个空间才会被删除,因此下面两种做法各代表和会自动释放与不会自动释放
# model won't be deleted by python since model still refer to resourece on gpu
model_cpu = model.cpu()# This way original resource on gpu will be released by python
model = model.cpu()torch.tensor.to没有inplace version
因此每一次需要用原来的变量保存
data = data.to(torch.device('cuda'))使用DataParallel后再访问attribute:需要用module.module.attribute
参考:
how-to-reach-model-attributes-wrapped-by-nn-dataparallel
Allnet.module.test_forward()torch.nn.Module.state_dict()的一些特性
根据官方说明:
Returns a dictionary containing a whole state of the module.
Both parameters and persistent buffers (e.g. running averages) are included. Keys are corresponding parameter and buffer names.
- 返回的是一个Orderdict,包含了所有层的参数,和一些persistent buffer,如平均值等。
- 所返回的Orderdict都是默认没有梯度的
self.model.state_dict()['conv1.weight'].requires_grad Out[12]: False
clone model的方法
基于上述性质,可以直接把state_dict()保存到一个临时变量中,然后直接load_dict()
pytorch获取tensor占用大小
sys.getsizeof(tensor.storage())stack()和cat()的使用场景
- 主要区别就是,stack会增加一个维度,而cat不会。二者都要求除了被拼接的那个维度,其余维度都需要相同
- 因此,stack对于原本element维度为0的list,拼起来之后自然就变成了1d的tensor;而对于想把element为1d的list拼起来,则应该用cat
list of single item tensor: stack
>>>torch.cat([torch.tensor(1), torch.tensor(2),torch.tensor(3)])
>>>Traceback (most recent call last):
File "/home/weitaotang/.conda/envs/tfpt_py3_backup/lib/python3.6/site-packages/IPython/core/interactiveshell.py", line 3326, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File "<ipython-input-14-6589a900f85f>", line 1, in <module>
torch.cat([torch.tensor(1), torch.tensor(2),torch.tensor(3)])
RuntimeError: zero-dimensional tensor (at position 0) cannot be concatenated
>>>torch.tensor([torch.tensor(1), torch.tensor(2),torch.tensor(3)])
Out[15]: tensor([1, 2, 3])list of 1d tensor: cat(如果希望获得1d的tensor)
torch.stack([torch.tensor([1,2]), torch.tensor([3,4])])
Out[16]:
tensor([[1, 2],
[3, 4]])
torch.cat([torch.tensor([1,2]), torch.tensor([3,4])])
Out[17]: tensor([1, 2, 3, 4])torch.no_grad()和 model.eval()怎么用?
参考
Evaluating pytorch models: with torch.no_grad vs model.eval()
提及是否要重新进行torch.set_grad_enabled(True)的答案model_eval() vs with torch.no_grad()
最好两个一起用,因为二者的作用不同:
1.torch.no_grad()是切断autograd,保证没有梯度,并且能够让inference时所占用的内存更少(因为不需要保存gradients)
2.model.eval()则是让某些层的行为发生改变,比如dropou层在开启了eval()后就不再作用,batchnorm则是会在整个input上在
model.eval()完了之后并不用设置set_grad_enabled,参考第二个回答
TensorboardX对于Multiline的prettytable的处理:
参考:
TensorFlow: tf.summary.text and linebreaks
因此需要把空格和
\n替换 掉,如下:table.get_string().replace(' ', ' ').replace('\n', ' \n')
pytorch的GPU memory管理
pytorch的GPU管理类似python的,当没有引用指向那部分内存的时候,就能够通过torch.cuda.empty_cache()释放掉,因此要特别注意forward等函数中的中间变量的使用
My model reports “cuda runtime error(2): out of memory” 中提到了关于loss的处理,千万不要accumulate,否则很麻烦.
错误的做法:
loss中包含了grad,因此不断append会越来越大loss = criterion(output, targets) ... total_loss += loss正确的做法:用
item()loss = criterion(output, targets) ... total_loss += loss对于无需训练的部分(inference那部分),建议直接用
torch.no_grad()
查看显存占用情况
参考:
- pytorch 减小显存消耗,优化显存使用,避免out of memory 里面罗列了很多。
- 浅谈深度学习:如何计算模型以及中间变量的显存占用大小 这位大神有写一个具体的package来显示各个tensor占用的内存。
复制模型的结构,如Sequential
直接把原来的那个Sequential的module抽出来就好了。默认_modules是OrderedDict,因此再用values就可转化为list, nn.Sequential等价于一个新的Constructor
s1 = nn.Sequential(nn.Linear(4,10), nn.Linear(10, 2))
s2 = nn.Sequential(*s1._modules.values())解决RuntimeError: CUDA error: initialization error的问题
RuntimeError: CUDA error: initialization error
避免这个问题要注意两点:
- 当使用
num_workers这个参数时,要注意成为Dataset的数据必须在CPU上,不能在GPU上。 - Dataset的数据不能有梯度,可以通过
detach()来实现。
综上,当出现这样的问题的时候,可以尝试:
.detach().cpu()MSELoss初探
和其他loss类似,reduction选项有三个,分别是sum,mean,none。默认是mean。三者的区别如下:
- none;求完平方和之后不动,输出的维度和两个输入都相同
- sum: 求完平方和之后再加起来
- mean:在sum的基础上再除以len(如果是2d的输入,则除以$n \times m$
测试的输出结果如下:
In [4]: a1 = torch.randn(3,4)
In [5]: a1
Out[5]:
tensor([[-1.5009, 1.2292, -0.1333, -0.2095],
[ 0.6178, -0.9349, -1.8915, -1.4830],
[ 0.0462, -1.0175, -0.3017, -0.5426]])
In [6]: a2 = torch.randn(3, 4)
In [7]: a2
Out[7]:
tensor([[ 0.1398, 0.4038, -1.1434, -1.0798],
[ 0.1173, -0.3946, -0.4661, 0.2909],
[ 0.5324, -0.6149, -1.4386, -1.7462]])
In [8]: import torch.nn as nn
In [9]: mse = nn.MSELoss(reduction='none')
In [10]: mse(a1, a2)
Out[10]:
tensor([[2.6919, 0.6814, 1.0204, 0.7575],
[0.2505, 0.2920, 2.0318, 3.1468],
[0.2364, 0.1620, 1.2925, 1.4487]])
In [11]: mse = nn.MSELoss(reduction='sum')
In [12]: mse(a1, a2)
Out[12]: tensor(14.0119)
In [13]: mse = nn.MSELoss(reduction='mean')
In [14]: mse(a1, a2)
Out[14]: tensor(1.1677)
In [15]: 14.0119 / 12
Out[15]: 1.1676583333333335但是如果只是单纯算距离的话,就不应该用这个函数,这个本质上还是loss,而应该用下面详述的pdist
算p-norm用的函数:torch.nn.pdist()
实际就是把dist matrix的upper triangular part算了出来,因此当输入是$N \times M$的时候,输出会是$1/2 \times N \times N$,具体例子如下:
In [26]: b = torch.randint(10, size=(3,2)).float()
In [27]: b
Out[27]:
tensor([[3., 5.],
[4., 4.],
[6., 7.]])
In [28]: F.pdist(b)
Out[28]: tensor([1.4142, 3.6056, 3.6056])获得dist matrix的正确操作:torch.triu + 转置即可
transform the upper/lower triangular part of a symmetric matrix (2D array) into a 1D array and return it to the 2D format,按照这里面所说的,在numpy中直接triu_indices/tril_indices结合转置的操作即可。
What’s the most efficient way to convert a vector into a triangular matrix? 这里面有给很简单的例子
因此在pytorch中,具体的操作应该是如下:先通过triu_indices获得upper triangular part的indices,逐个赋值,然后转置,最后相加即可
In [26]: b = torch.randint(10, size=(3,2)).float()
In [27]: b
Out[27]:
tensor([[3., 5.],
[4., 4.],
[6., 7.]])
In [28]: F.pdist(b)
Out[28]: tensor([1.4142, 3.6056, 3.6056])
In [29]: dist = torch.zeros(b.size(0), b.size(0))
In [30]: dist
Out[30]:
tensor([[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]])
In [38]: dist[triu_indices[0], triu_indices[1]]=F.pdist(b)
In [39]: dist
Out[39]:
tensor([[0.0000, 1.4142, 3.6056],
[0.0000, 0.0000, 3.6056],
[0.0000, 0.0000, 0.0000]])
In [40]: dist.T
Out[40]:
tensor([[0.0000, 0.0000, 0.0000],
[1.4142, 0.0000, 0.0000],
[3.6056, 3.6056, 0.0000]])
In [41]: dist = dist + dist.T
In [42]: dist
Out[42]:
tensor([[0.0000, 1.4142, 3.6056],
[1.4142, 0.0000, 3.6056],
[3.6056, 3.6056, 0.0000]])
PS:如果想把上述的L2 norm距离(即euclidean distance)转化为similarity,可以考虑如下的操作:
(把其中操作换成inplace的也可行)
In [68]: dist_.add(1).pow(-1)
Out[68]:
tensor([[1.0000, 0.2500, 0.1161],
[0.2500, 1.0000, 0.0979],
[0.1161, 0.0979, 1.0000]])
model.eval() 和 model.train() 对同一个batch输出差异巨大的原因
最主要就是BatchNorm出问题了。根据官方文档
Also by default, during training this layer keeps running estimates of its computed mean and variance, which are then used for normalization during evaluation.
因此如果training的时候统计出来的mean和variance与test的时候差异巨大,就会导致最后输出的loss或者是prediction差异巨大。
因此这个问题的出现通常是batch size设置太大的缘故,为了保证精度,应该:
- 把batch size设置小一些,这样才能让这个统计更加准确,
- 不要逐个epoch都test一次,在训练了一定次数之后再开始test
参考如下
During training the current batch stats will be used to compute the output, so that the model might converge.
However, during evaluation the batchnorm layer tries to normalize both inputs with skewed running estimates, which yields the high loss values.
Usually we assume that all inputs are from the same domain and thus have approx. the same statistics
it is possible that your training in general is unstable, so BatchNorm’s running_mean and running_var dont represent true batch statistics.
即batch size太大,估计出来的variance和mean就不太准了。(因为train set和test set shuffle的方式通常不一样)
手动更新parameters/Autograd使用
参考:
- ‘NoneType’ object has no attribute ‘zero_’ 说的很清楚
- Autograd,一个pytorch的例子,也比较清楚
- PyTorch: Autograd很清晰的例子,推荐参考!
preliminary
- 创建一个新的
Tensor后,默认是require_grad=Truegrad为None,说明grad为全0。因此如果一开始直接grad.zero()_是会报错的
容易遇到的问题
- 不是
inplace操作:形如weight = weight - weight.grad*lr会导致创建一个新的变量,而新的变量会丢失之前变量的信息,包括grad。导致后面直接.grad.zero_()错误 - 没有把手动update这个操作放到
torch.no_grad()中:导致不必要的grad计算以及错误的结果
正确方法
for i in range(epochs):
predict = torch.mm(feature, weight) + bias.item()
loss = torch.sum(predict - label, dim=0)
loss.backward()
# Disable the autograd
with torch.no_grad():
# Inplace changes
weight.sub_(weight.grad*lr)
bias.sub_(bias.grad*lr) # A .grad is missing in your code here I think ;)
# Do the reset in no grad mode as well in case you do second order
# derivatives later (meaning that weight.grad will requires_grad)
weight.grad.zero_()
bias.grad.zero_()stuck in data loading:一直卡死在载入数据上
参考 Debugger freezes stepping forward when using pytorch with workers (multiprocessing)
原因:可能是num_workers的问题,设置为0!就解决了!
clone detach torch.tensor 的比较
参考:
- Pytorch张量(Tensor)复制,把
clone和detach的几种实验关系都说清楚了 - Why Tensor.clone().detach() is recommended when copying a tensor?,主要提及了默认的
torch.tensor在创建新变量的时候的默认属性 - torch.tensor:官方文档说明
- Pytorch preferred way to copy a tensor这个回答也说的很清楚
- Difference between detach().clone() and clone().detach(),本质二者没区别
创建一个新的leaf node
来自torch.tensor:
When data is a tensor x,
torch.tensor()reads out ‘the data’ from whatever it is passed, and constructs a leaf variable. Thereforetorch.tensor(x)is equivalent tox.clone().detach()andtorch.tensor(x, requires_grad=True)is equivalent tox.clone().detach().requires_grad_(True). The equivalents usingclone()anddetach()are recommended.
即最快的方法是:直接torch.tensor(x),而这等价于:
x.clone().detach()获取到一个内部的数据,且从计算图切断- 用上述获得的data(
item())创建一个新的torch.tensor
然而直接用上述的方法是不建议的,会有warning:
def new_tensor(x, requires_grad=True):
return torch.tensor(x, requires_grad=requires_grad, device='cuda') \
if torch.cuda.is_available() else torch.tensor(x, requires_grad=requires_grad, device='cpu')
The warning points to wrapping a tensor in torch.tensor, which is not recommended. Instead of torch.tensor(outputs) use outputs.clone().detach() or the same with .requires_grad_(True), if necessary.
据官方文档,最佳的还是x.clone().detach().requires_grad_(True)或者x.clone().detach().requires_grad_(False)
特别注意,如果是想从cpu创建到gpu上,需要保证先迁移到GPU上,然后再开启requires_grad_()(参考 【pytorch: can’t optimize a non-leaf Tensor】。否则会因为先开始记录grad,再迁移,导致GPU上的tensor多了个copyfnbackward,即在GPU上的不再是叶子节点:
# 错误做法,会导致 ValueError: can‘t optimize a non-leaf Tensor
new_x = x.clone.detach().requires_grad_(True).to(torch.device('cuda'))
# 正确做法
new_x = x.clone.detach().to(torch.device('cuda')).requires_grad_(True)nn.Parameters
A kind of Tensor that is to be considered a module parameter.
实际是torch.Tensor的子类,可以通过.data获取到对应的tensors。更多说明可以看上面的文档
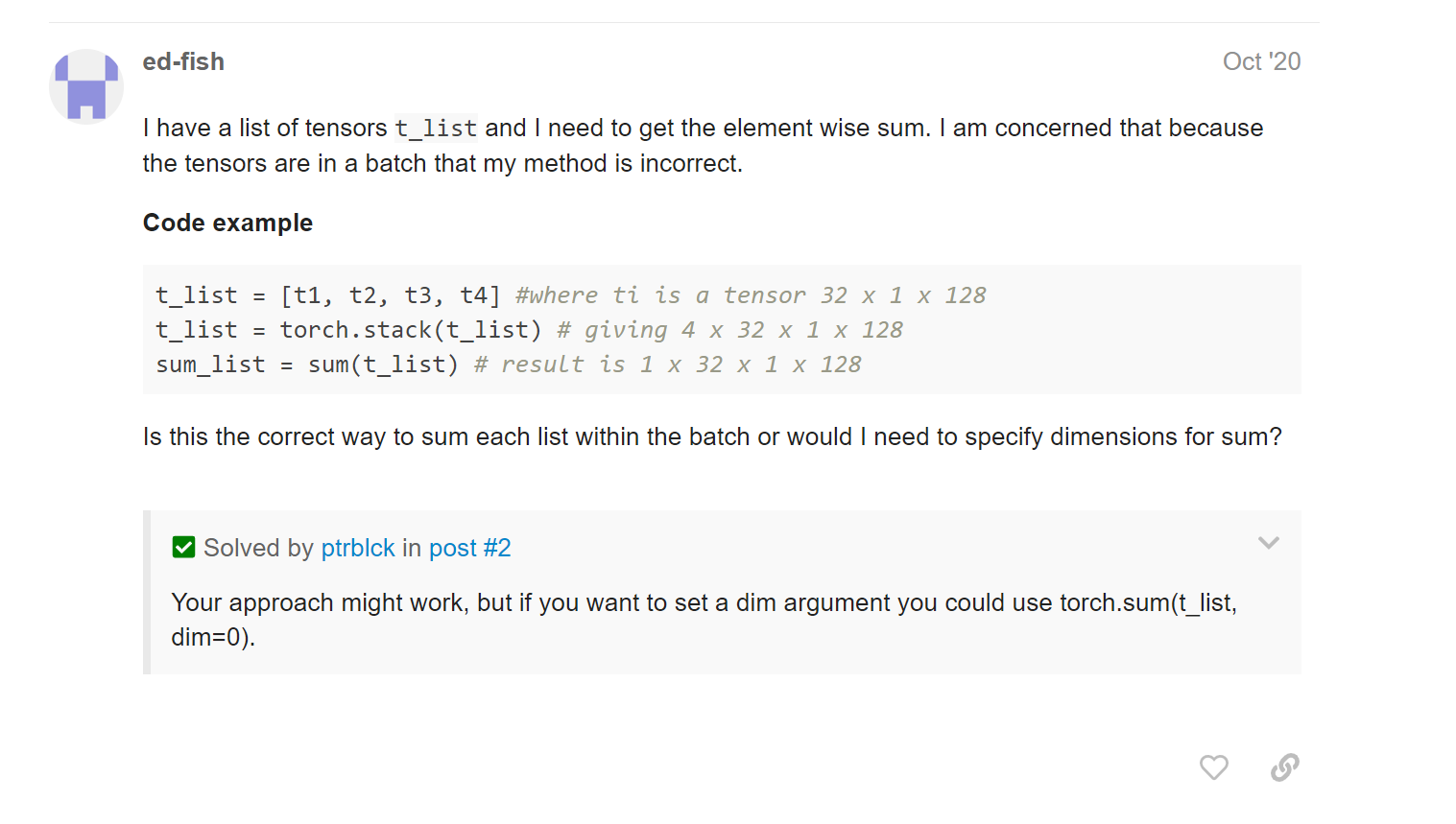
把多个N dim的tensor拼成N+1 dim的tensor
直接用torch.stack就可以了!!
Concatenates a sequence of tensors along a new dimension.
All tensors need to be of the same size.
还可以指定对出来的那个维度放在哪!(dim)
一个典型的应用就是 element-wise sum of a batched tensors
torch.as_tensor() 和torch.from_numpy()的区别
Yes, both approaches share the underlying memory.
torch.as_tensoraccepts a bit more thattorch.from_numpy, such aslistobjects, and might thus have a slightly higher overhead for these checks.
所以对于numpy.array()来说,几乎没差别
torch.nn.ModuleList()导致的UserWarning: Setting attributes on ParameterList is not supported.

把实现方式从
self.factors = nn.ParameterList(
[nn.Parameter(torch.Tensor(self.rank, 10 + 1, 6), requires_grad=True) for _ in
range(len(mds))])变为
for num_md in range(len(num_mds)):
self.factors.append(nn.Parameter(torch.Tensor(self.rank, 10 + 1, 6), requires_grad=True))
setattr(self, f"factor_{num_md}", self.factors[-1])这样打印model.name_parameters()时,就从
{'fusion_weights': None,
'fusion_bias': None,
'all_fcs.0.0.weight': None,
'all_fcs.0.0.bias': None,
'all_fcs.0.2.weight': None,
'all_fcs.0.2.bias': None,
'all_fcs.0.4.weight': None,
'all_fcs.0.4.bias': None,
'all_fcs.0.6.weight': None,
'all_fcs.0.6.bias': None,
'all_fcs.1.0.weight': None,
'all_fcs.1.0.bias': None,
'all_fcs.1.2.weight': None,
'all_fcs.1.2.bias': None,
'all_fcs.1.4.weight': None,
'all_fcs.1.4.bias': None,
'all_fcs.1.6.weight': None,
'all_fcs.1.6.bias': None,
'factors.0': None,
'factors.1': None}变为
{'factor_0': None,
'factor_1': None,
'fusion_weights': None,
'fusion_bias': None,
'fc_0.0.weight': None,
'fc_0.0.bias': None,
'fc_0.2.weight': None,
'fc_0.2.bias': None,
'fc_0.4.weight': None,
'fc_0.4.bias': None,
'fc_0.6.weight': None,
'fc_0.6.bias': None,
'fc_1.0.weight': None,
'fc_1.0.bias': None,
'fc_1.2.weight': None,
'fc_1.2.bias': None,
'fc_1.4.weight': None,
'fc_1.4.bias': None,
'fc_1.6.weight': None,
'fc_1.6.bias': None}

多个模型一起训练
Train multiple models on multiple GPUs
直接训练即可
I think in your current implementation you would indeed have to wait until the optimization was done on each GPU.
If you just have two models, you could push each input and targettensorto the appropriate GPU and call the forward passes after each other.
Since these calls are performed asynchronously, you could achieve a speedup in this way.
The code should look like this:
还可以把不同的模型放到不同的设备上,单独进行训练,参照上的链接Train multiple models on multiple GPUs
或者参考 Combining Trained Models in PyTorch,放到同一个模型里面,等价写一个MyEnsemble模型,然后同时调用两个模型(内部本质上和上面单独叫没啥差别)
还可以参考 Train multiple models on multiple GPUs 这个回答,用分布式实现
修改模型的时候不建议把Module.children()做成一个list再放到nn.Sequential里面
参考 Combining Trained Models in PyTorch
The code looks generally OK, but I wouldn’t recommend to create new models via passing the child modules to
nn.Sequential.
Using this approach you would call each submodule in a sequential way and would therefore lose all functional calls, which were used in the originalforward.
E.g. forDenseNetyou would lose these calls.
